“创建 Python 模型”组件
本文介绍 Azure 机器学习设计器中的一个组件。
了解如何使用“创建 Python 模型”组件从 Python 脚本创建未经训练的模型。 可以将模型基于包含在 Python 包中的任何学习器,该包位于 Azure 机器学习设计器环境中。
创建模型后,可以使用训练模型来训练数据集中的模型,就像 Azure 机器学习中的任何其他学习器一样。 训练的模型可以传递给评分模型,以便进行预测。 然后,你可以保存训练的模型,并将评分工作流发布为 Web 服务。
警告
目前,无法将此组件连接到“优化模型超参数”组件,或将 Python 模型的评分结果传递到评估模型。 如果需要优化超参数或评估模型,可以使用执行 Python 脚本组件编写自定义 Python 脚本。
配置组件
使用此组件需要具备中级或专家级 Python 知识。 此组件支持使用 Azure 机器学习中已安装的 Python 包中包含的任何学习器。 请参阅执行 Python 脚本中的预安装 Python 包列表。
注意
编写脚本时请务必小心,并确保无语法错误,例如使用未声明的对象或未导入的组件。
注意
此外,请特别注意执行 Python 脚本中的预安装组件列表。 仅导入预安装的组件。 请不要在此脚本中安装“pip install xgboost”等额外的包,否则在读取下游组件模型时会引发错误。
本文介绍如何将“创建 Python 模型”与简单管道配合使用。 下面是管道的示意图:
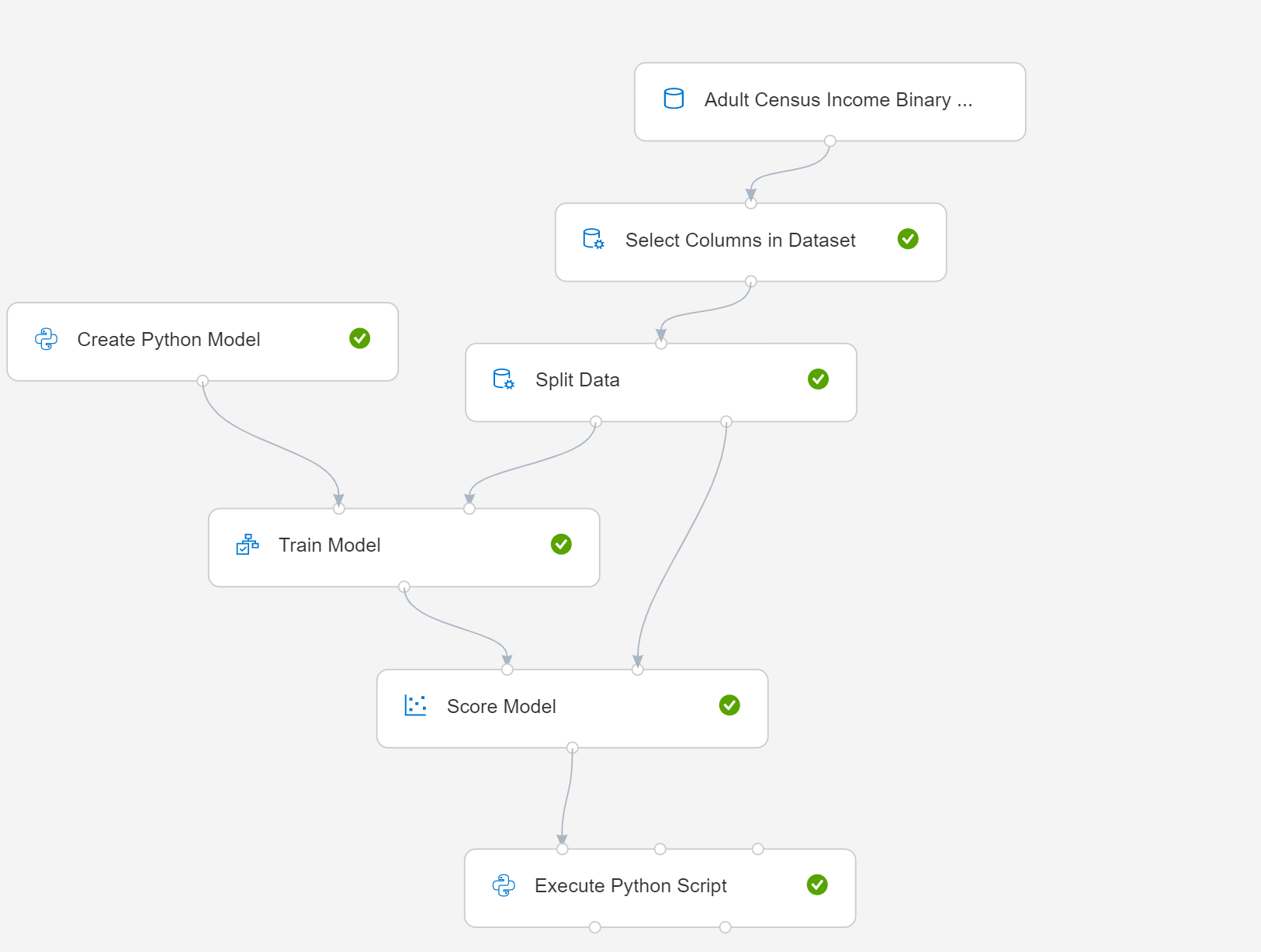
- 选择“创建 Python 模型”,编辑脚本以实现建模或数据管理过程。 可以将模型基于包含在 Python 包中的任何学习器,该包位于 Azure 机器学习环境中。
注意
请特别注意脚本示例代码中的注释,确保脚本严格遵循对类名、方法以及方法签名等的要求。 违反要求将导致异常。 “创建 Python 模型”仅支持创建基于 sklearn 的模型以使用“训练模型”进行训练。
下面是使用常用 sklearn 包的双类 Naive Bayes 分类器的示例代码:
# The script MUST define a class named Azure Machine LearningModel.
# This class MUST at least define the following three methods:
# __init__: in which self.model must be assigned,
# train: which trains self.model, the two input arguments must be pandas DataFrame,
# predict: which generates prediction result, the input argument and the prediction result MUST be pandas DataFrame.
# The signatures (method names and argument names) of all these methods MUST be exactly the same as the following example.
# Please do not install extra packages such as "pip install xgboost" in this script,
# otherwise errors will be raised when reading models in down-stream components.
import pandas as pd
from sklearn.naive_bayes import GaussianNB
class AzureMLModel:
def __init__(self):
self.model = GaussianNB()
self.feature_column_names = list()
def train(self, df_train, df_label):
# self.feature_column_names records the column names used for training.
# It is recommended to set this attribute before training so that the
# feature columns used in predict and train methods have the same names.
self.feature_column_names = df_train.columns.tolist()
self.model.fit(df_train, df_label)
def predict(self, df):
# The feature columns used for prediction MUST have the same names as the ones for training.
# The name of score column ("Scored Labels" in this case) MUST be different from any other columns in input data.
return pd.DataFrame(
{'Scored Labels': self.model.predict(df[self.feature_column_names]),
'probabilities': self.model.predict_proba(df[self.feature_column_names])[:, 1]}
)
将刚创建的“创建 Python 模型”组件连接到“训练模型”和“评分模型” 。
如果需要评估模型,请添加 执行 Python 脚本组件并编辑 Python 脚本。
下面的脚本是示例评估代码:
# The script MUST contain a function named azureml_main # which is the entry point for this component. # imports up here can be used to import pandas as pd # The entry point function MUST have two input arguments: # Param<dataframe1>: a pandas.DataFrame # Param<dataframe2>: a pandas.DataFrame def azureml_main(dataframe1 = None, dataframe2 = None): from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_auc_score, roc_curve import pandas as pd import numpy as np scores = dataframe1.ix[:, ("income", "Scored Labels", "probabilities")] ytrue = np.array([0 if val == '<=50K' else 1 for val in scores["income"]]) ypred = np.array([0 if val == '<=50K' else 1 for val in scores["Scored Labels"]]) probabilities = scores["probabilities"] accuracy, precision, recall, auc = \ accuracy_score(ytrue, ypred),\ precision_score(ytrue, ypred),\ recall_score(ytrue, ypred),\ roc_auc_score(ytrue, probabilities) metrics = pd.DataFrame(); metrics["Metric"] = ["Accuracy", "Precision", "Recall", "AUC"]; metrics["Value"] = [accuracy, precision, recall, auc] return metrics,
后续步骤
请参阅 Azure 机器学习可用的组件集。