训练模型组件
本文介绍 Azure 机器学习设计器中的一个组件。
使用此组件可以训练分类或回归模型。 训练在你定义模型并设置其参数后进行,并且需要带标记的数据。 你还可以使用训练模型来使用新数据重新训练现有模型。
训练过程的工作原理
在 Azure 机器学习中,创建和使用机器学习模型通常是一个三步过程。
可以通过选择特定类型的算法并定义其参数或超参数来配置模型。 选择以下任一模型类型:
- 分类模型,基于神经网络、决策树,以及决策林和其他算法。
- 回归模型,这可能包括标准线性回归,也可能使用其他算法(包括神经网络和 Bayesian 回归)。
提供一个带标记且其数据与算法兼容的数据集。 将数据和模型都连接到训练模型。
训练产生的是特定的二元格式 iLearner,它封装了从数据中获知的统计模式。 无法直接修改或读取此格式;但是,其他组件可以使用已训练的此模型。
你还可以查看模型的属性。 有关详细信息,请参阅“结果”部分。
训练完成后,通过某个评分组件使用已训练的模型对新数据做出预测。
如何使用训练模型
将“训练模型”组件添加到管道。 可以在“机器学习”类别下找到此组件。 展开“训练”,然后将“训练模型”组件拖放到管道中 。
在左侧输入中,附加未训练的模式。 将训练数据集附加到训练模型的右侧输入。
训练数据集必须包含一个标签列。 不带标签的任何行都将被忽略。
对于“标签列”,请在组件右侧面板中单击“编辑列”,然后选择包含可用于训练的结果的单个列 。
对于分类问题,标签列必须包含分类值或离散值。 可能的一些示例如下:“是/否”评级、疾病分类代码或名称,或收入组。 如果选择非分类列,则在训练过程中,该组件将返回错误。
对于回归问题,标签列必须包含表示响应变量的数字数据。 理想情况下,数字数据表示连续标度。
可能的示例有信用风险分数、硬盘驱动器的预计故障时间,或者在给定的日期或时间内对某个呼叫中心的呼叫预测数。 如果未选择数字列,则可能会出现错误。
- 如果未指定要使用的标签列,则 Azure 机器学习将尝试使用数据集的元数据推断哪个列是相应的标签列。 如果它选择了错误的列,请使用列选择器来更正它。
提示
如果使用列选择器时遇到问题,请参阅选择数据集中的列一文中的提示。 该文章介绍了使用 WITH RULES 和 BY NAME 选项的一些常见方案和提示。
提交管道。 如果有大量数据,则可能需要一段时间。
重要
如果有一个 ID 列是每一行的 ID,或者有一个文本列包含太多的唯一值,则训练模型可能会遇到如下错误:“列 "{column_name}" 中的唯一值的数目大于允许的数目。”
这是因为该列达到了唯一值的阈值,可能会导致内存不足。 可以使用编辑元数据将该列标记为“清除特征”,这样该列就不会在训练中使用,并且“从文本中提取 N 元语法特征”组件也不会预处理文本列。 请参阅设计器错误代码获取更多错误详细信息。
模型可解释性
模型可解释性为理解 ML 模型并以人类可以理解的方式呈现决策基础提供了可能性。
“训练模型”组件目前支持使用可解释性包来解释 ML 模型。 支持以下内置算法:
- 线性回归
- 神经网络回归
- 提升决策树回归
- 决策林回归
- 泊松回归
- 双类逻辑回归
- 两类支持向量机
- 双类提升决策树
- 双类决策林
- 多类决策林
- 多类逻辑回归
- 多类神经网络
若要生成模型说明,可以在“训练模型”组件的“模型说明”下拉列表中选择“True” 。 在“训练模型”组件中,默认设置为 False。 请注意,生成说明需要额外的计算成本。
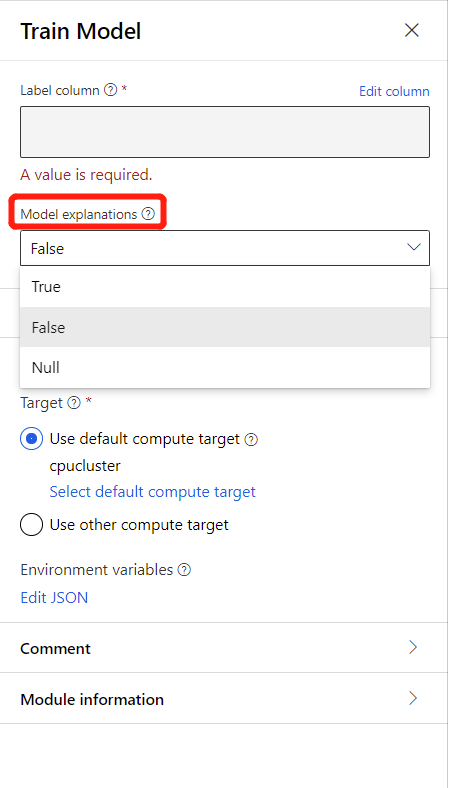
在管道运行完成后,可以访问“训练模型”组件右侧窗格的“说明”选项卡,然后浏览模型性能、数据集和特征重要性 。
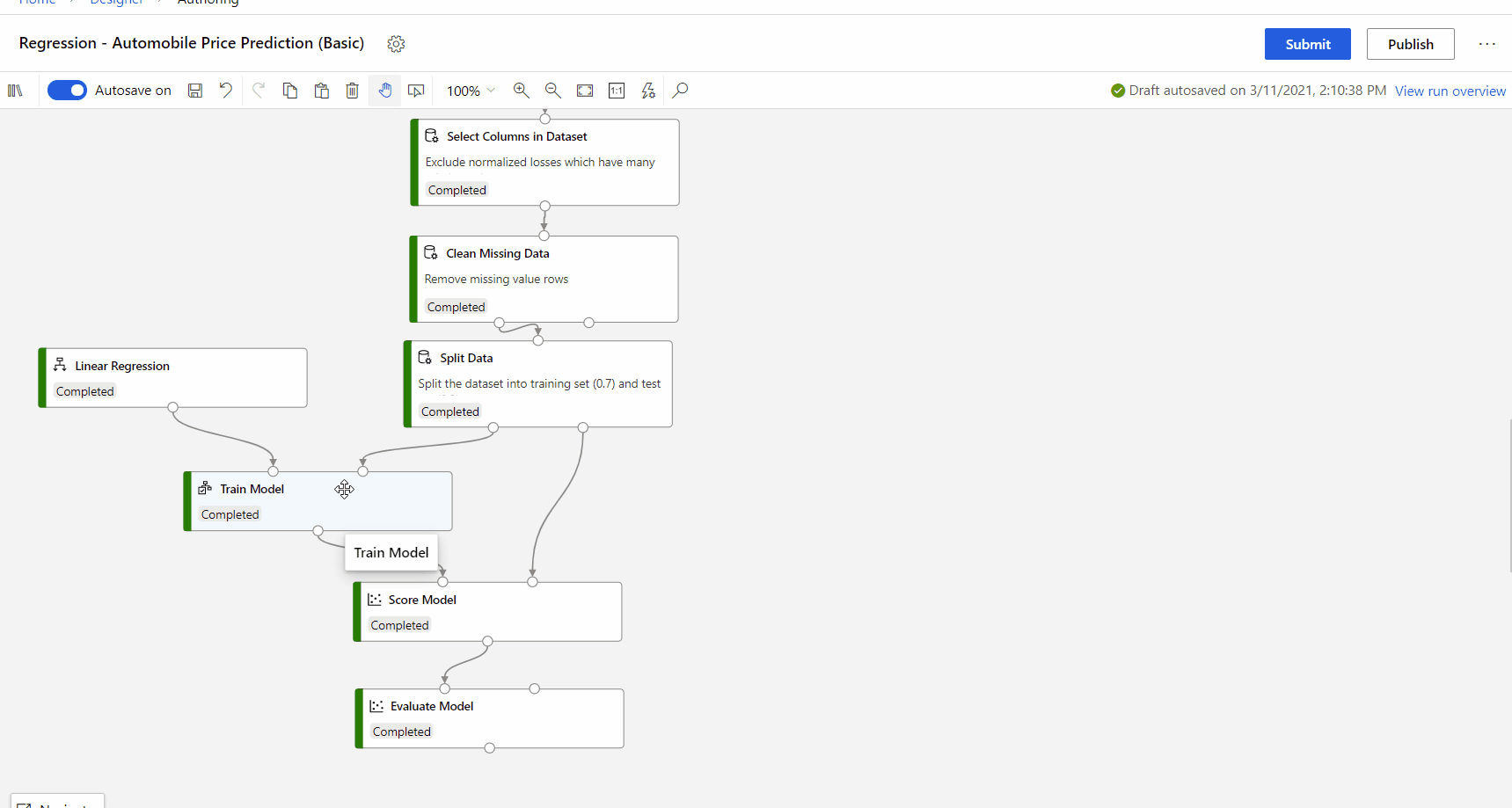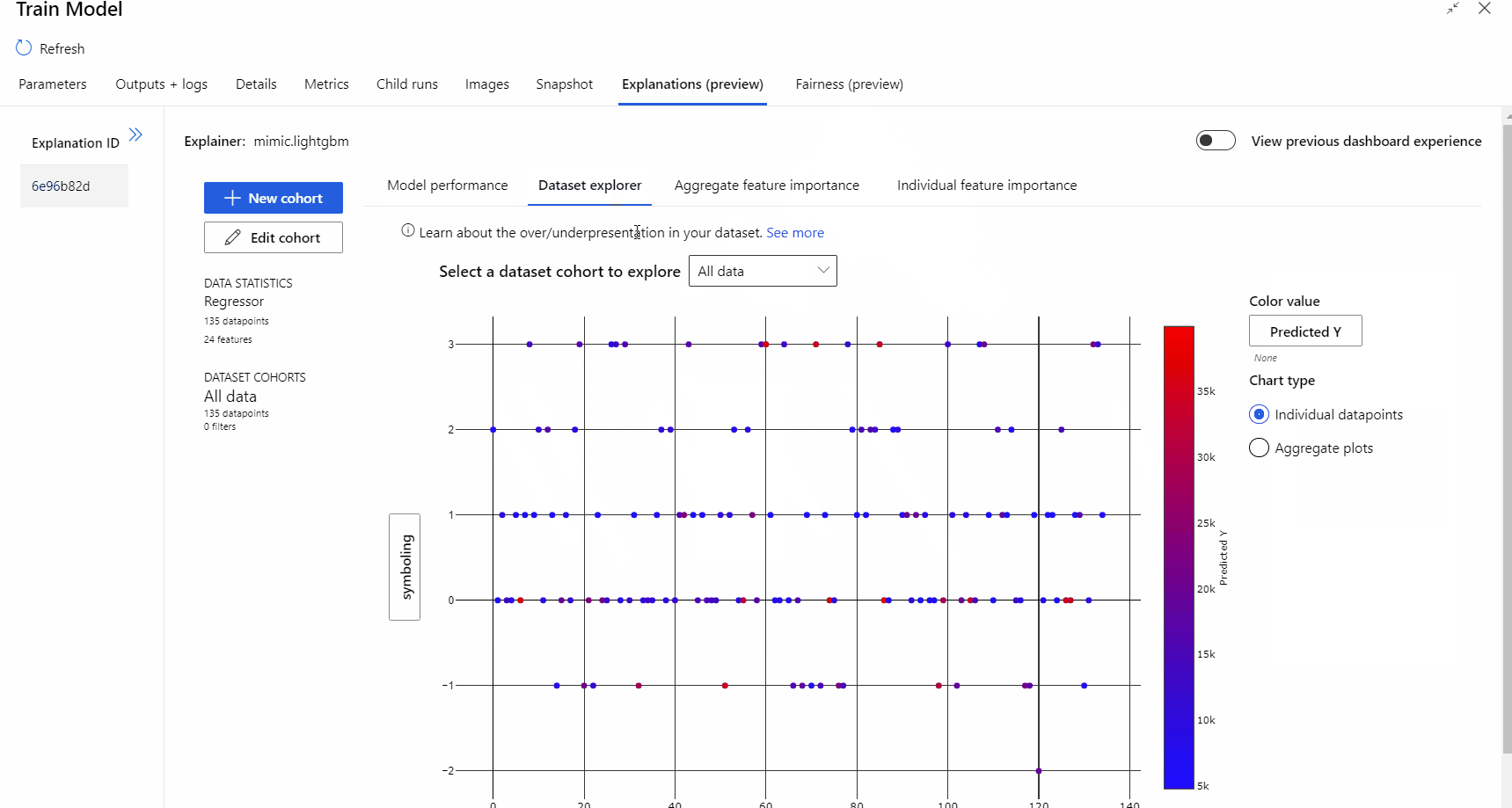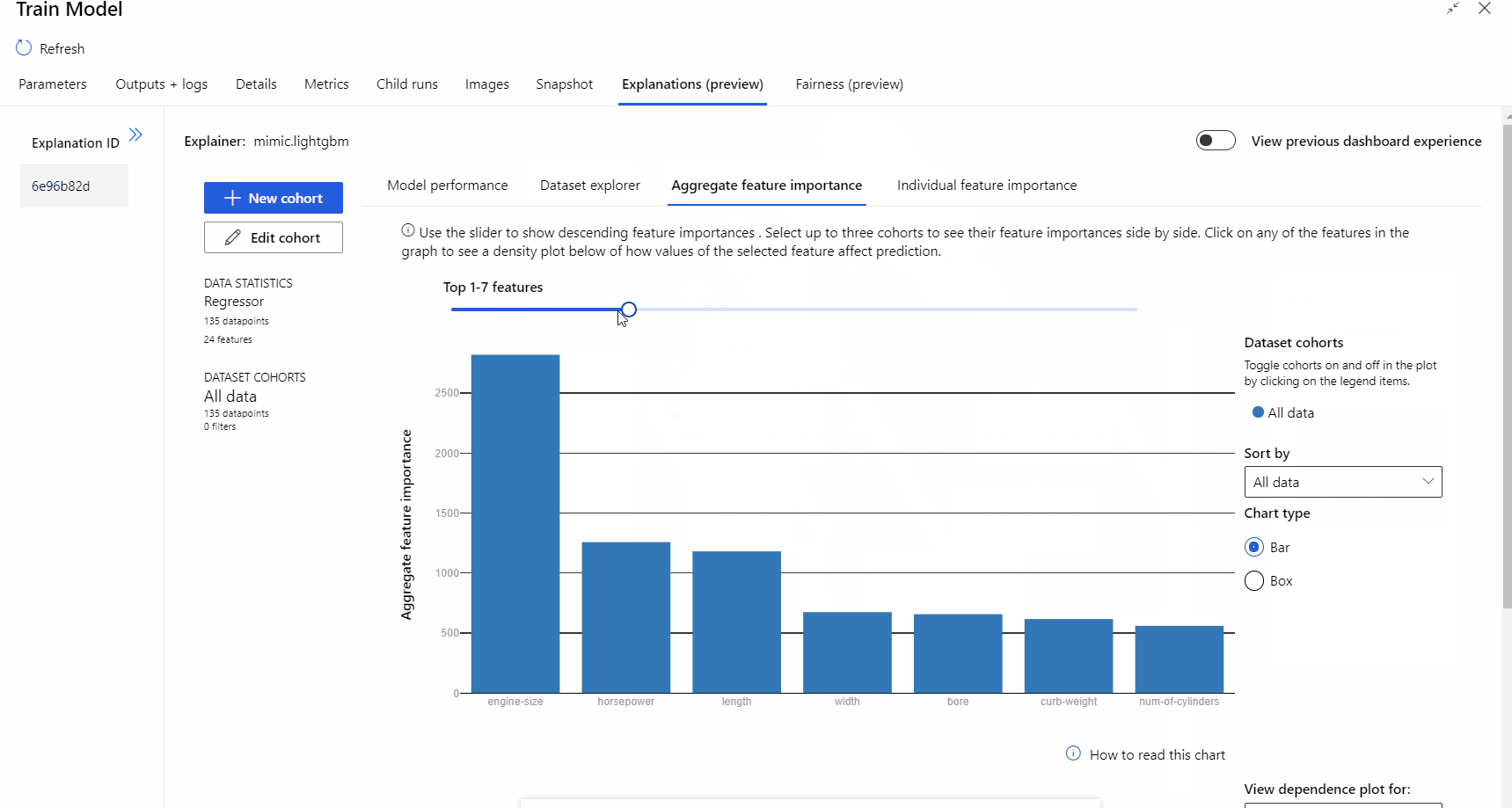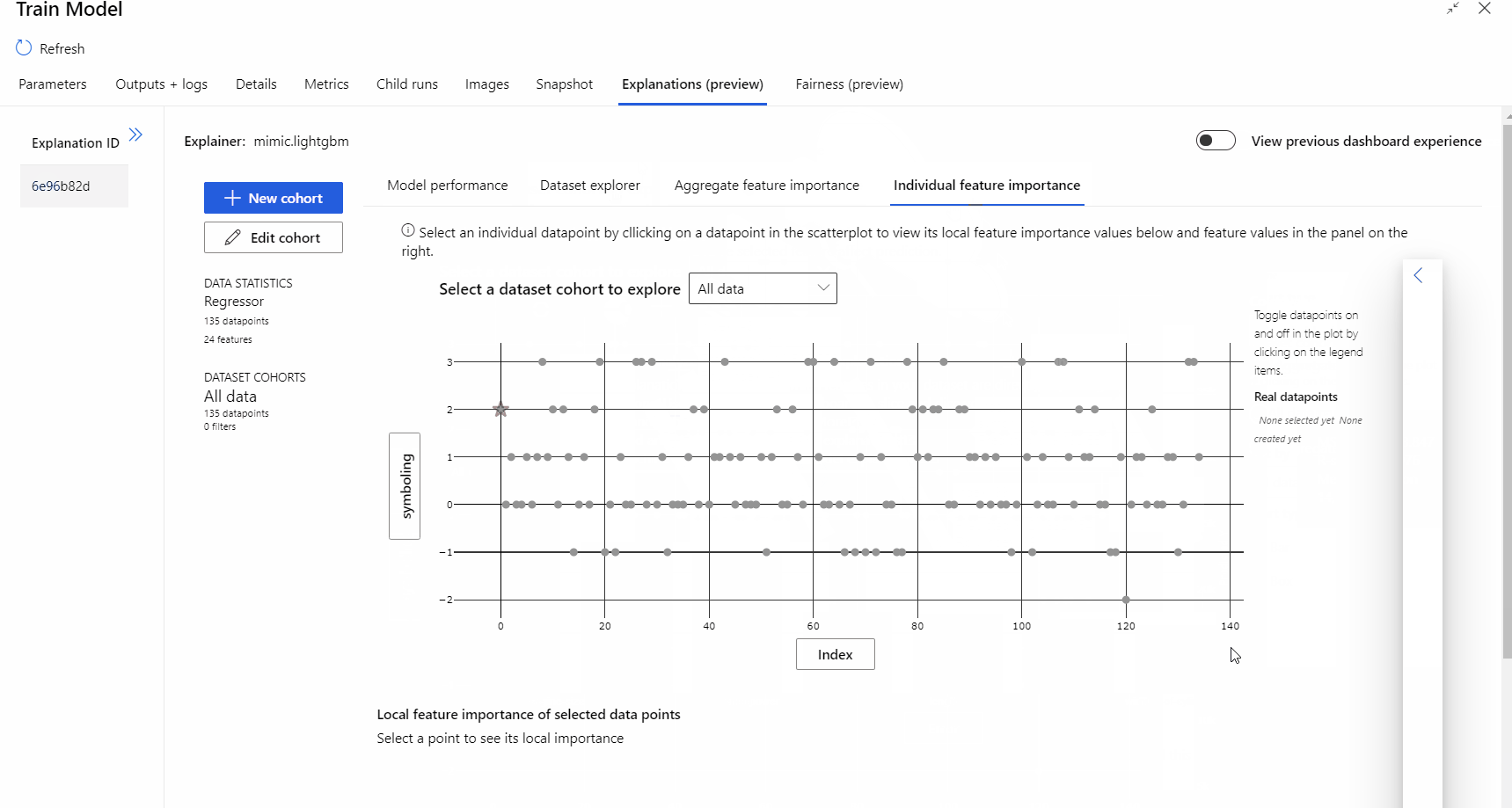
结果
在对模型进行训练后:
若要在其他管道中使用该模型,请选择组件,并在右侧面板中的“输出”选项卡下选择“注册数据集”图标 。 可以在组件面板中的“数据集”下访问已保存的模型。
若要在预测新值时使用该模型,请将它连同新的输入数据一起连接到评分模型组件。
后续步骤
请参阅 Azure 机器学习可用的组件集。