本页介绍如何在 Databricks 笔记本中开发代码,包括自动完成、Python 和 SQL 的自动格式设置、在笔记本中组合使用 Python 和 SQL,以及跟踪笔记本版本历史记录。
有关编辑器提供的高级功能(例如自动完成、变量选择、多光标支持和并列比较)的更多详细信息,请参阅使用 Databricks 笔记本和文件编辑器。
Databricks 笔记本还包括适用于 Python 笔记本的内置交互式调试程序。 请参阅调试笔记本。
访问用于编辑的笔记本
若要打开笔记本,请使用工作区搜索功能或使用工作区浏览器导航到笔记本,然后单击笔记本的名称或图标。
浏览数据
使用架构浏览器浏览可用于笔记本的 Unity Catalog 对象。 单击笔记本左侧的 ![]() 打开架构浏览器。
打开架构浏览器。
“推荐”按钮仅显示你在当前会话中使用的或以前加入收藏夹的对象。
在“筛选器”框中键入文本时,界面将更改为仅显示包含键入的文本的那些对象。 仅显示当前打开或已在当前会话中打开的对象。 “筛选器”框不会完全搜索可用于笔记本的目录、架构、表和卷。
若要打开 ![]() kebab 菜单,请如下所示将光标悬浮在对象的名称上:
kebab 菜单,请如下所示将光标悬浮在对象的名称上:
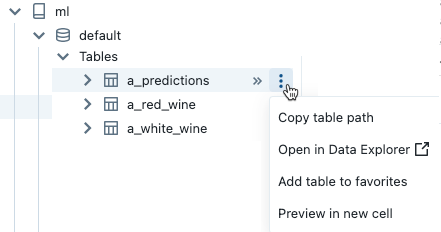
如果该对象是一个表,则可以执行以下操作:
- 自动创建并运行单元格以显示表中数据的预览。 从表的 kebab 菜单中选择在“新单元格中预览”。
- 在目录资源管理器中查看目录、架构或表。 从 kebab 菜单中选择“在目录资源管理器中打开”。 此时会打开一个新选项卡,其中显示所选的对象。
- 获取目录、架构或表的路径。 从对象的 kebab 菜单中选择“复制...路径”。
- 将表添加到收藏夹。 从表的 kebab 菜单中选择“添加到收藏夹”。
如果该对象是目录、架构或卷,则你可以复制该对象的路径,或在目录资源管理器中将其打开。
若要将表名或列名直接插入单元格中,请执行以下操作:
- 在单元格中你想要输入名称的位置单击光标。
- 将光标移到架构浏览器中的表名或列名上。
- 单击出现在项对象名称右侧的双箭头
 。
。
键盘快捷方式
要显示键盘快捷键,请选择“帮助”>“键盘快捷键”。 键盘快捷键是否可用取决于光标是位于代码单元中(编辑模式),还是不位于代码单元中(命令模式)。
命令面板
可以使用命令面板在笔记本中快速执行操作。 若要打开笔记本操作面板,请单击工作区右下角的  ,或使用快捷键 Cmd + Shift + P(在 MacOS 上)或 Ctrl + Shift + P(在 Windows 上)。
,或使用快捷键 Cmd + Shift + P(在 MacOS 上)或 Ctrl + Shift + P(在 Windows 上)。
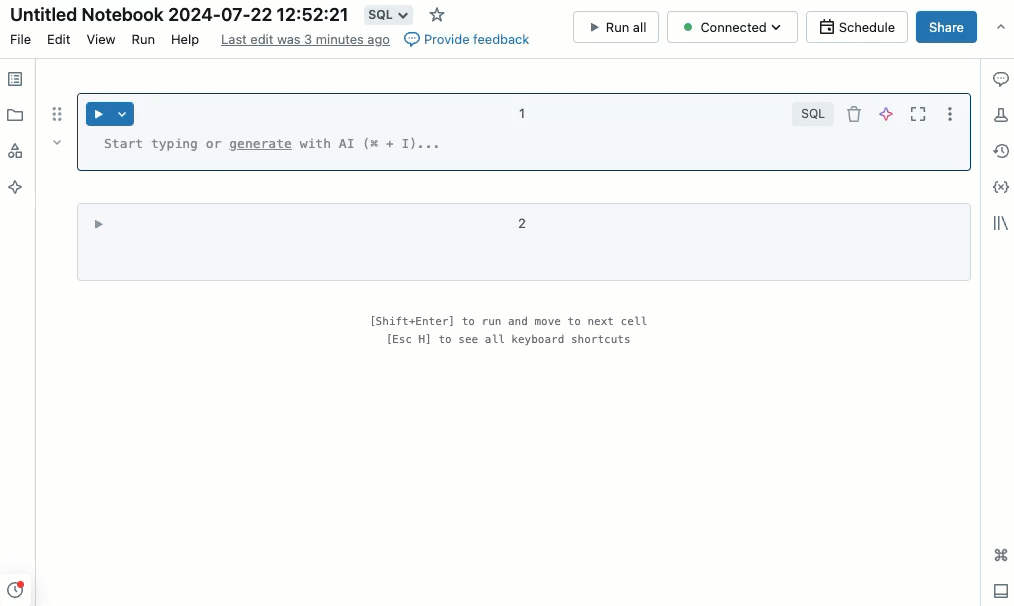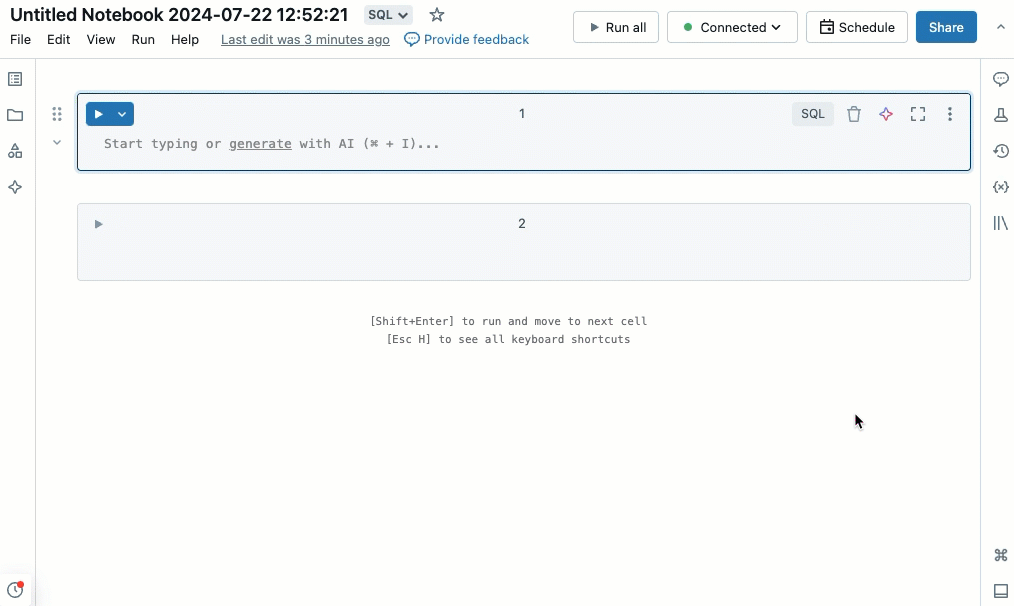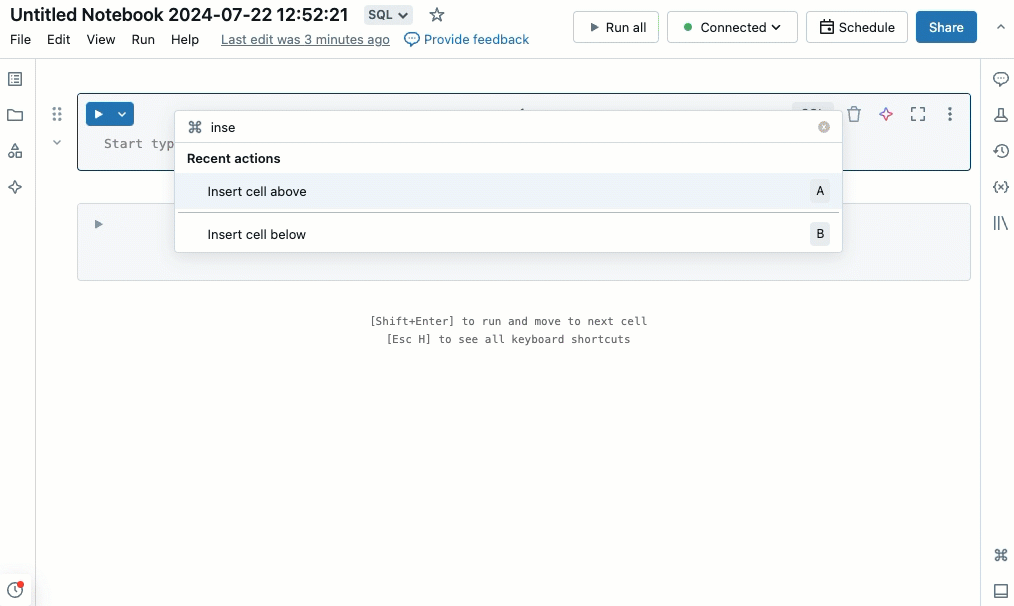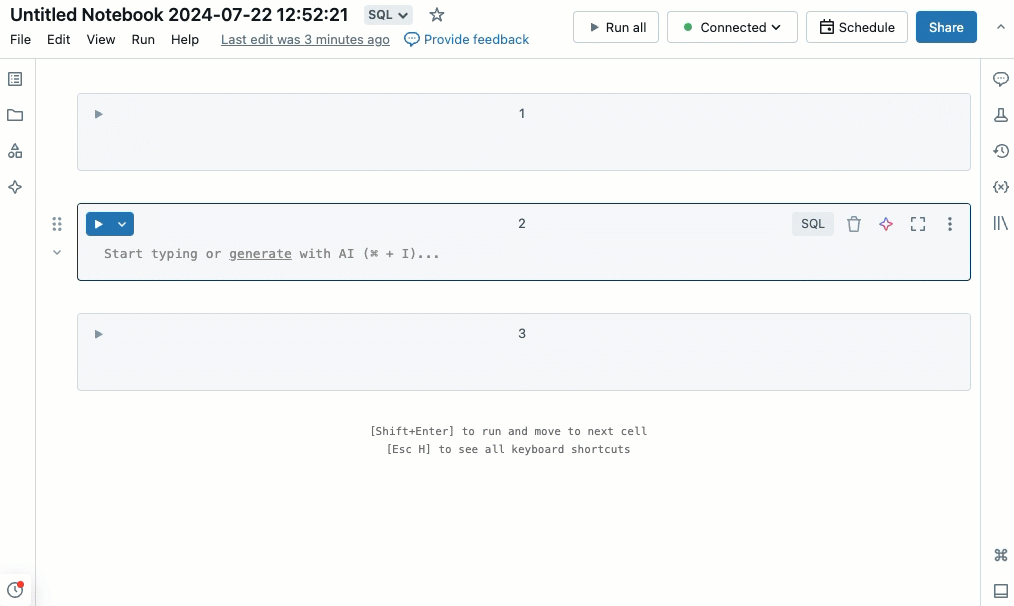
查找和替换文本
要查找和替换笔记本中的文本,请选择“编辑”>“查找和替换”。 当前的匹配项以橙色突出显示,所有其他的匹配项以黄色突出显示。
若要替换当前匹配项,请单击“替换”。 若要替换笔记本中的所有匹配项,请单击“全部替换”。
若要在匹配项之间移动,请单击“上一个”和“下一个”按钮 。 还可以按“Shift+Enter”和“Enter”,分别转到上一个和下一个匹配项 。
若要关闭查找和替换工具,请单击![]() 或按“Esc”。
或按“Esc”。
运行所选单元格
可以运行单个单元格或单元格集合。 若要选择单个单元格,请单击单元格中的任意位置。 若要选择多个单元格,请按住 MacOS 上的 Command 键或 Windows 上的 Ctrl 键,然后单击文本区域外的单元格,如屏幕截图所示。
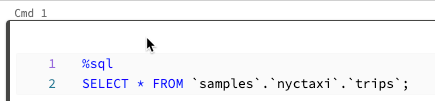
要运行所选 此命令的行为取决于笔记本附加到的群集。
- 在运行 Databricks Runtime 13.3 LTS 或更低版本的群集上,将单独执行所选单元格。 如果单元格中发生错误,则执行将继续执行后续单元格。
- 在运行 Databricks Runtime 14.0 或更高版本的群集或者 SQL 仓库上,所选单元格将作为一批执行。 任何错误都将停止执行,并且无法取消单个单元格的执行。 可以使用“中断”按钮停止执行所有单元格。
将代码模块化
重要
此功能目前以公共预览版提供。
使用 Databricks Runtime 11.3 LTS 及更高版本,可以在 Azure Databricks 工作区中创建和管理源代码文件,然后根据需要将这些文件导入到笔记本中。
有关使用源代码文件的详细信息,请参阅在 Databricks 笔记本之间共享代码和使用 Python 和 R 模块。
运行所选文本
可在笔记本单元格中突出显示代码或 SQL 语句,并仅运行所选内容。 当你想要快速循环访问代码和查询时,这非常有用。
突出显示要运行的行。
选择“运行”>“运行所选文本”或使用键盘快捷方式
Ctrl+Shift+Enter。 如果未突出显示任何文本,“运行所选文本”将执行当前行。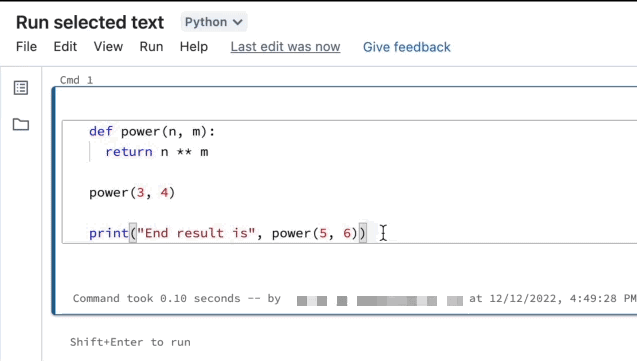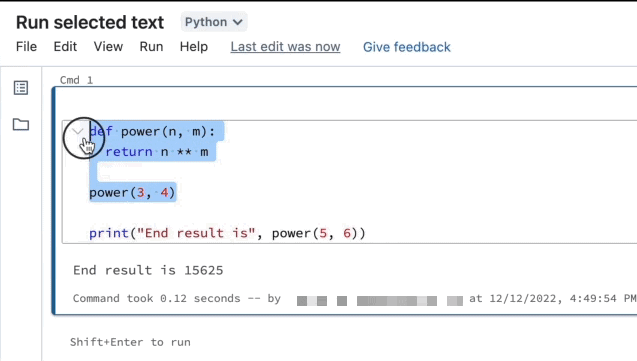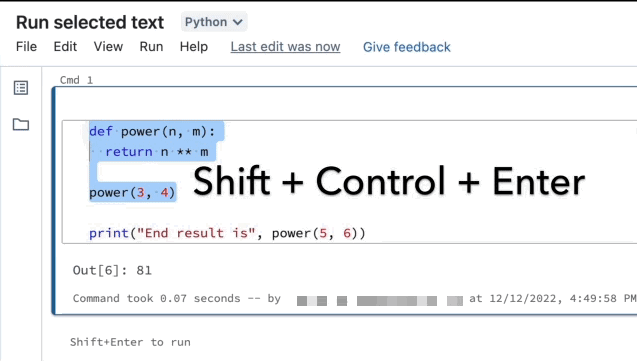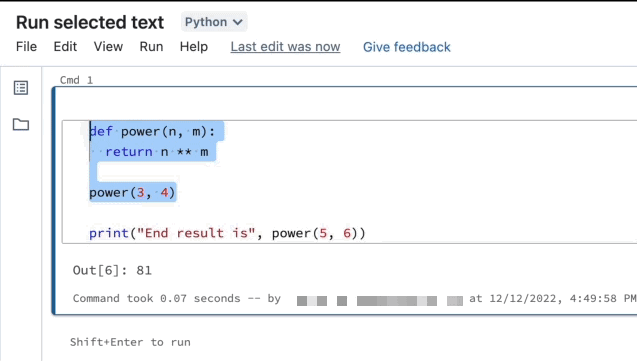
如果在单元格中使用混合语言,则必须在所选内容中包含 %<language> 行。
“运行所选文本”还会执行折叠的代码(如果突出显示的选定内容中有任何代码)。
支持特殊的单元格命令,例如 %run、%pip 和 %sh。
不能在具有多个输出选项卡的单元格(即已定义数据配置文件或可视化效果的单元格)上使用“运行所选文本”。
设置代码单元格的格式
Azure Databricks 提供的工具可用于在笔记本单元格中快速且轻松地设置 Python 和 SQL 代码的格式。 这些工具减少了使代码带有格式的工作量,有助于在笔记本中强制实施相同的编码标准。
Python black 格式化程序库
重要
此功能目前以公共预览版提供。
Azure Databricks 支持在笔记本中使用 black 的 Python 代码格式设置。 笔记本必须附加到安装了 black 和 tokenize-rt Python 包的群集。
在 Databricks Runtime 11.3 LTS 及更高版本上,Azure Databricks 将预安装 black 和 tokenize-rt。 可以直接使用格式化程序,而无需安装这些库。
在 Databricks Runtime 10.4 LTS 及更低版本上,必须在笔记本或群集上通过 PyPI 安装 black==22.3.0 和 tokenize-rt==4.2.1 才能使用 Python 格式化程序。 可以在笔记本中运行以下命令:
%pip install black==22.3.0 tokenize-rt==4.2.1
或在群集上安装库。
有关安装库的更多详细信息,请参阅 Python 环境管理。
对于 Databricks Git 文件夹中的文件和笔记本,可根据 pyproject.toml 文件配置 Python 格式化程序。 若要使用此功能,请在 Git 文件夹根目录中创建一个 pyproject.toml 文件,并根据 Black 配置格式对其进行配置。 编辑文件中的 [tool.black] 部分。 当格式化该 Git 文件夹中的任何文件和笔记本时,将应用该配置。
如何设置 Python 和 SQL 单元格的格式
必须拥有笔记本“可编辑”权限,才能设置代码的格式。
Azure Databricks 使用 Gethue/sql-formatter 库来设置 SQL 格式,并使用适用于 Python 的 black 代码格式化程序。
可通过以下方式触发格式化程序:
设置单个单元格的格式
设置多个单元格的格式
选择多个单元格,然后选择“编辑”>“设置单元格格式”。 如果选择多个语言的单元格,则仅会设置 SQL 和 Python 单元格的格式。 这包括那些使用
%sql和%python的单元格。设置笔记本中所有 Python 和 SQL 单元格的格式
选择“编辑”>“设置笔记本格式”。 如果笔记本包含多种语言,则只会设置 SQL 和 Python 单元格的格式。 这包括那些使用
%sql和%python的单元格。
代码格式设置的限制
- Black 对 4 空格缩进强制执行 PEP 8 标准。 缩进不可配置。
- 不支持设置 SQL UDF 中嵌入的 Python 字符串的格式。 同样,不支持设置 Python UDF 中 SQL 字符串的格式。
版本历史记录
Azure Databricks 笔记本维护笔记本版本历史记录,允许查看和还原笔记本以前的快照。 可以执行以下有关版本的操作:添加注释、还原和删除版本,以及清除版本历史记录。
还可以将 Databricks 中的工作与远程 Git 存储库同步。
要访问笔记本版本,请单击右侧边栏中的 。 此时会显示笔记本版本历史记录。 还可以选择“文件”>“版本历史记录”。
。 此时会显示笔记本版本历史记录。 还可以选择“文件”>“版本历史记录”。
添加注释
要将注释添加到最新版本,请执行以下操作:
单击版本。
单击“立即保存”。
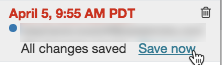
在“保存笔记本版本”对话框中,输入注释。
单击“ 保存”。 笔记本版本将连同输入的注释一起保存。
还原版本
要还原版本,请执行以下操作:
单击版本。
单击“还原此版本”。
单击“确认” 。 所选版本将成为笔记本的最新版本。
删除版本
若要删除版本条目,请执行以下操作:
单击版本。
单击回收站图标
 。
。
单击“是,擦除”。 所选版本将从历史记录中删除。
清除版本历史记录
版本历史记录清除后无法恢复。
要清除笔记本的版本历史记录,请执行以下操作:
- 选择“文件”>“清除版本历史记录”。
- 单击“是,清除”。 此时会清除笔记本版本历史记录。
笔记本中的代码语言
设置默认语言
笔记本的默认语言显示在笔记本名称旁边。

要更改默认语言,请单击语言按钮并从下拉菜单中选择新语言。 为确保现有命令可继续正常工作,以前的默认语言的命令会自动带有语言 magic 命令前缀。
混合语言
默认情况下,单元格使用笔记本的默认语言。 通过单击语言按钮并从下拉菜单中选择一种语言,可以替代单元格中的默认语言。
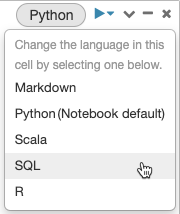
或者,可以在单元格的开头使用语言 magic 命令 %<language>。 支持的 magic 命令为:%python、%r、%scala 和 %sql。
注意
调用语言 magic 命令时,该命令会被调度到笔记本的执行上下文中的 REPL。 用一种语言定义(并且因此位于该语言的 REPL 中)的变量在其他语言的 REPL 中不可用。 REPL 只能通过外部资源(例如 DBFS 中的文件或对象存储中的对象)共享状态。
笔记本还支持几个辅助 magic 命令:
%sh:允许你在笔记本中运行 shell 代码。 若要在 shell 命令的退出状态为非零值的情况下使单元格发生失败,请添加-e选项。 此命令仅在 Apache Spark 驱动程序上运行,不在工作器上运行。 若要在所有节点上运行 shell 命令,请使用初始化脚本。%fs:允许你使用dbutils文件系统命令。 例如,如需运行dbutils.fs.ls命令以列出文件,可以改为指定%fs ls。 有关详细信息,请参阅使用 Azure Databricks 上的文件。%md:允许你包括各种类型的文档,例如文本、图像以及数学公式和等式。 请参阅下一部分。
Python 命令中的 SQL 语法突出显示和自动完成
当你在 Python 命令(例如 spark.sql 命令)中使用 SQL 时,可以使用语法突出显示和 SQL 自动完成。
浏览 SQL 单元格结果
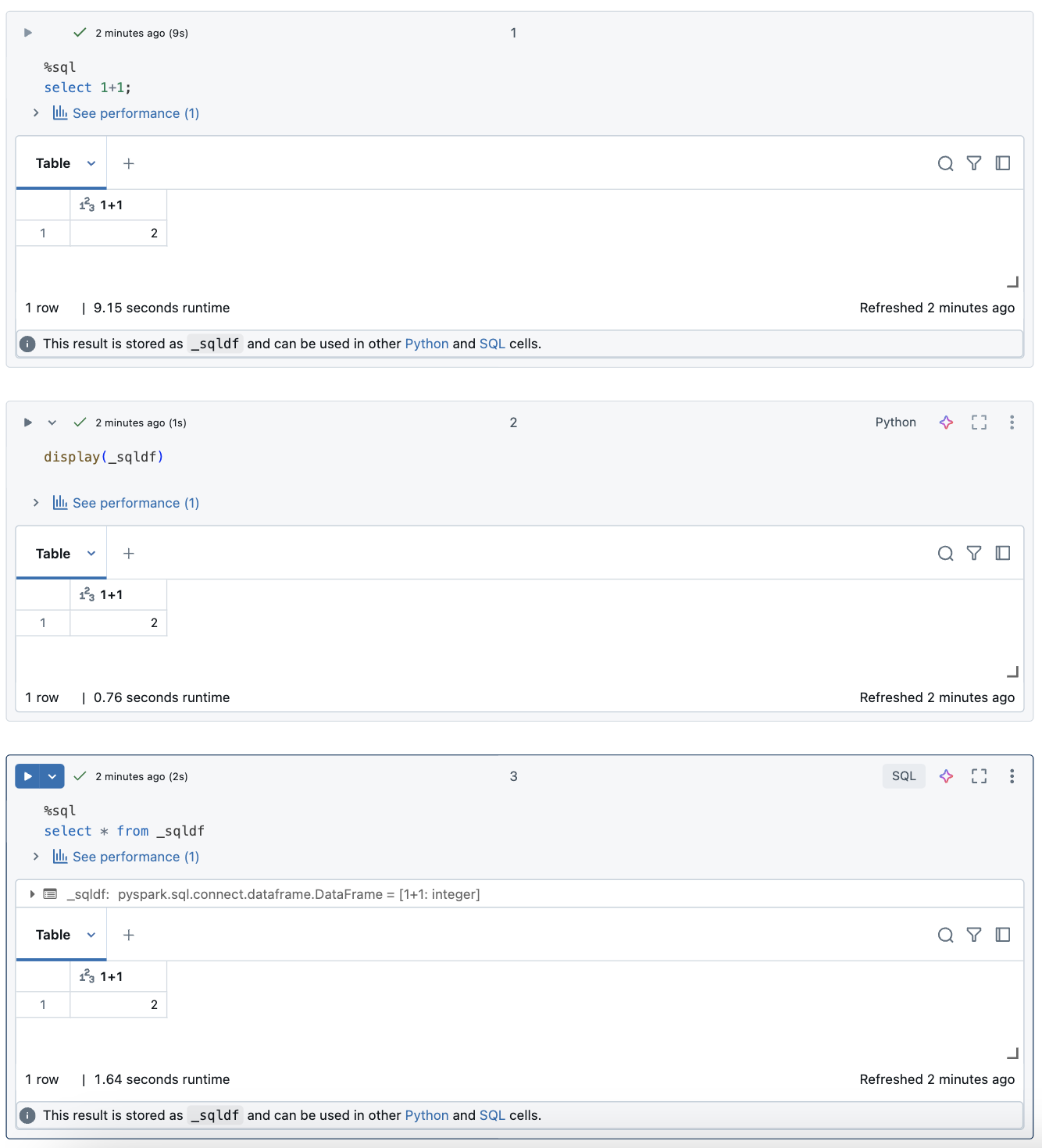
在 Databricks 笔记本中,SQL 语言单元格中的结果自动作为分配到变量 _sqldf 的隐式数据帧提供。 然后,可在之后运行的任何 Python 和 SQL 单元格中使用此变量,而不考虑它们在笔记本中的位置。
注意
此功能具有以下限制:
- 该
_sqldf变量在使用 SQL 仓库进行计算的笔记本中不可用。 - Databricks Runtime 13.3 及更高版本中支持在后续 Python 单元格中使用
_sqldf。 - Databricks Runtime 14.3 及更高版本中支持在后续 SQL 单元格中使用
_sqldf。 - 如果查询使用关键字
CACHE TABLE或UNCACHE TABLE,则_sqldf变量不可用。
以下屏幕截图显示了如何在后续 Python 和 SQL 单元格中使用 _sqldf:
重要
每次运行 SQL 单元格时,都可以重新分配变量 _sqldf。 若要避免丢失对特定数据帧结果的引用,请在运行下一个 SQL 单元格之前将其分配到新的变量名称:
Python
new_dataframe_name = _sqldf
SQL
ALTER VIEW _sqldf RENAME TO new_dataframe_name
并行执行 SQL 单元格
当某个命令正在运行且你的笔记本已附加到交互式群集时,可以将 SQL 单元格与当前命令同时运行。 SQL 单元格在新的并行会话中执行。
若要并行执行某个单元格,请执行以下操作:
单击“立即运行”。 此时会立即执行该单元格。
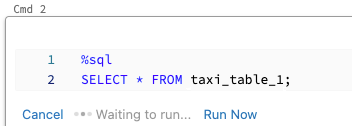
由于单元格在新会话中运行,因此并行执行的单元格不支持临时视图、UDF 和隐式 Python 数据帧 (_sqldf)。 此外,在并行执行期间将使用默认目录和数据库名称。 如果代码引用不同目录或数据库中的表,则你必须使用三级命名空间 (catalog.schema.table) 来指定表名。
在 SQL 仓库上执行 SQL 单元格
可以在 SQL 仓库上的 Databricks 笔记本中运行 SQL 命令,这是一种针对 SQL 分析优化的计算类型。 请参阅将笔记本与 SQL 仓库配合使用。
显示图像
Azure Databricks 支持在 Markdown 单元格中显示图像。 可显示存储在工作区、卷或 FileStore 中的图像。
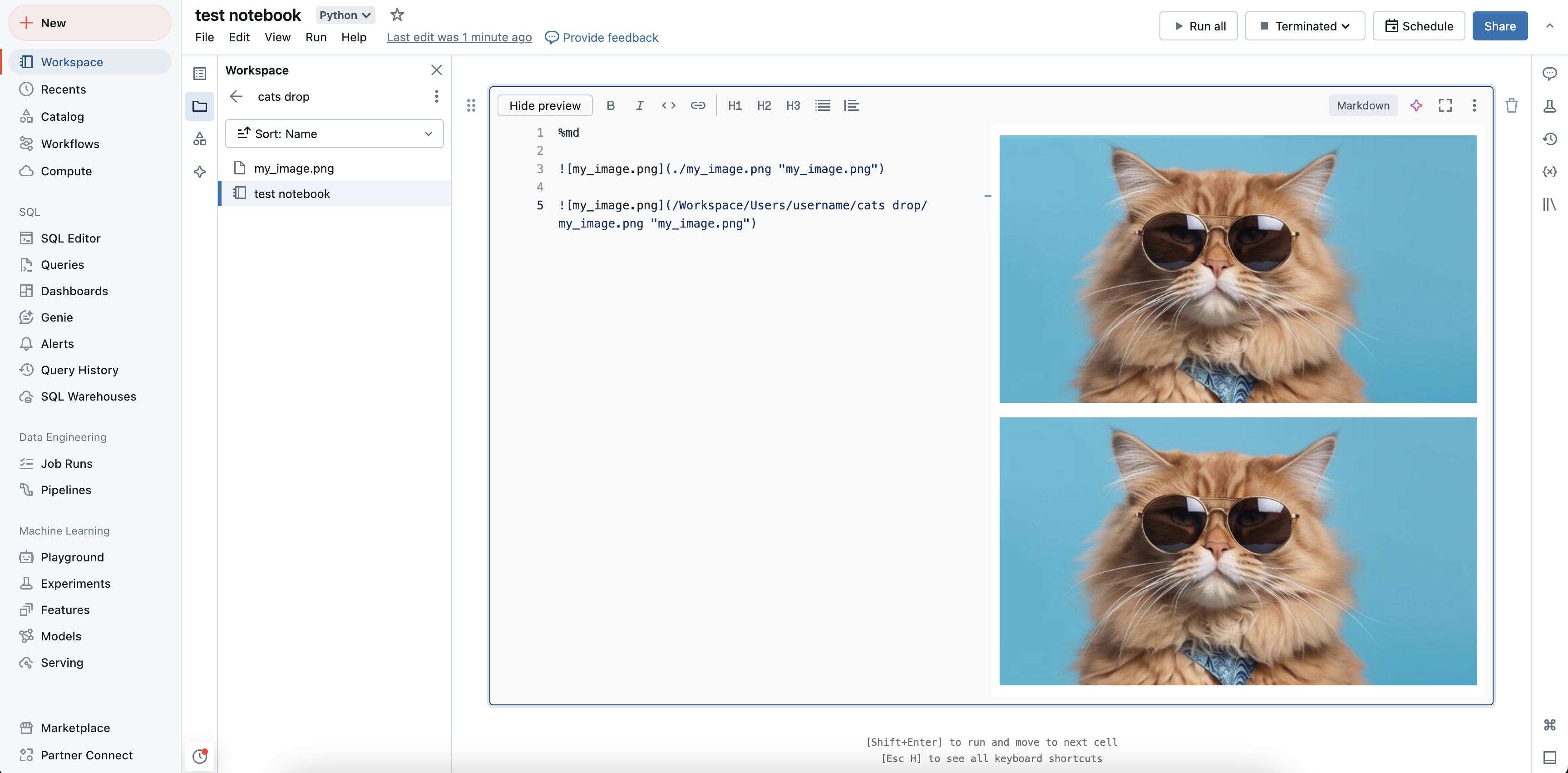
显示存储在工作区中的图像
可以使用绝对路径或相对路径来显示存储在工作区中的图像。 若要显示存储在工作区中的图像,请使用以下语法:
%md


显示存储在卷中的图像
可使用绝对路径来显示存储在卷中的图像。 若要显示存储在卷中的图像,请使用以下语法:
%md

显示存储在 FileStore 中的图像
若要显示在 FileStore 中存储的图像,请使用以下语法:
%md

例如,假设你在 FileStore 中有 Databricks 徽标图像文件:
dbfs ls dbfs:/FileStore/
databricks-logo-mobile.png
在 Markdown 单元格中包括以下代码时:

图像会呈现在单元格中:

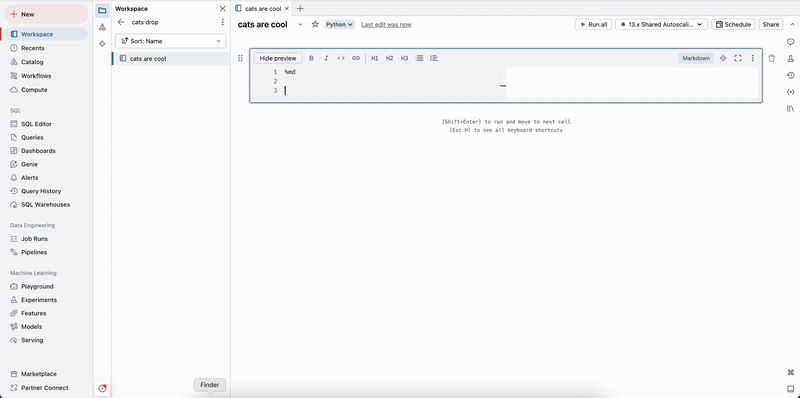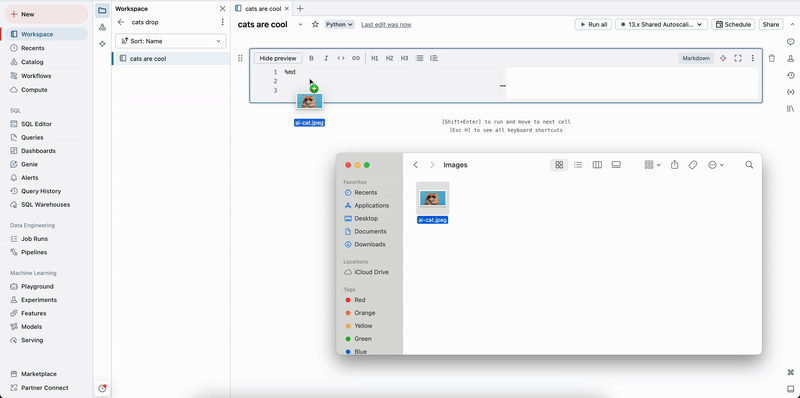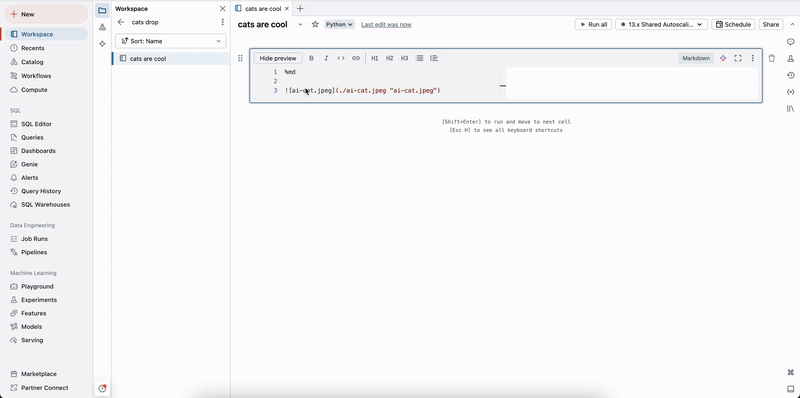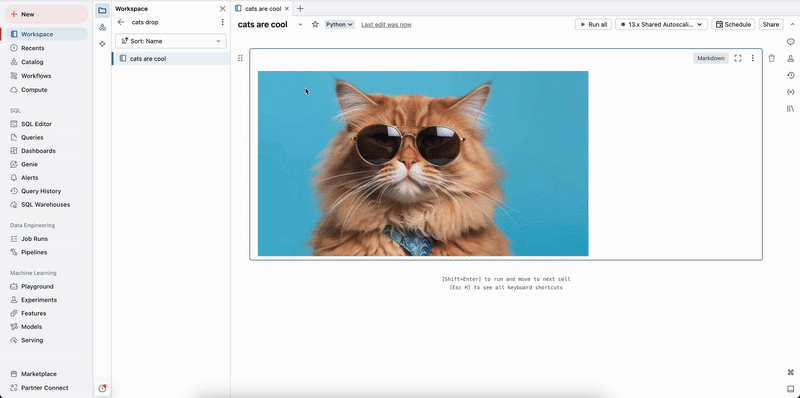
拖放图像
可将图像从本地文件系统拖放到 Markdown 单元格中。 图像上传到当前工作区目录并显示在单元格中。
显示数学等式
笔记本支持 KaTeX,用于显示数学公式和等式。 例如,
%md
\\(c = \\pm\\sqrt{a^2 + b^2} \\)
\\(A{_i}{_j}=B{_i}{_j}\\)
$$c = \\pm\\sqrt{a^2 + b^2}$$
\\[A{_i}{_j}=B{_i}{_j}\\]
呈现为:
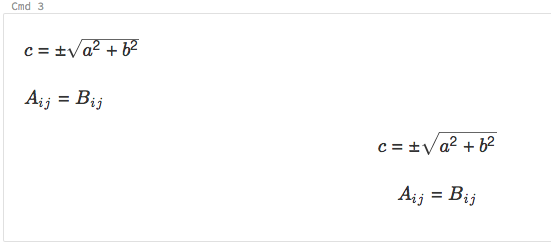
and
%md
\\( f(\beta)= -Y_t^T X_t \beta + \sum log( 1+{e}^{X_t\bullet\beta}) + \frac{1}{2}\delta^t S_t^{-1}\delta\\)
where \\(\delta=(\beta - \mu_{t-1})\\)
呈现为:
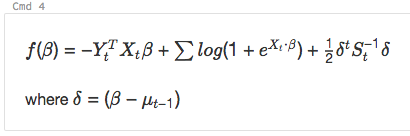
包括 HTML
可以使用函数 displayHTML 在笔记本中包括 HTML。 请参阅笔记本中的 HTML、D3 和 SVG,通过示例来了解如何执行此操作。
注意
displayHTML iframe 是从域 databricksusercontent.com 提供的,iframe 沙盒包含 allow-same-origin 属性。 必须可在浏览器中访问 databricksusercontent.com。 如果它当前被企业网络阻止,则必须将其添加到允许列表。
链接到其他笔记本
可以使用相对路径链接到 Markdown 单元格中的其他笔记本或文件夹。 将定位点标记的 href 属性指定为相对路径(以 $ 开头),然后遵循与 Unix 文件系统中的模式相同的模式:
%md
<a href="$./myNotebook">Link to notebook in same folder as current notebook</a>
<a href="$../myFolder">Link to folder in parent folder of current notebook</a>
<a href="$./myFolder2/myNotebook2">Link to nested notebook</a>