适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
数据工厂和 Synapse 管道中的 Spark 活动在自己的或按需 HDInsight 群集上执行 Spark 程序。 本文基于数据转换活动一文,它概述了数据转换和受支持的转换活动。 使用按需的 Spark 链接服务时,此服务会自动为你实时创建用于处理数据的 Spark 群集,然后在处理完成后删除群集。
通过 UI 将 Spark 活动添加到管道
若要对管道使用 Spark 活动,请完成以下步骤:
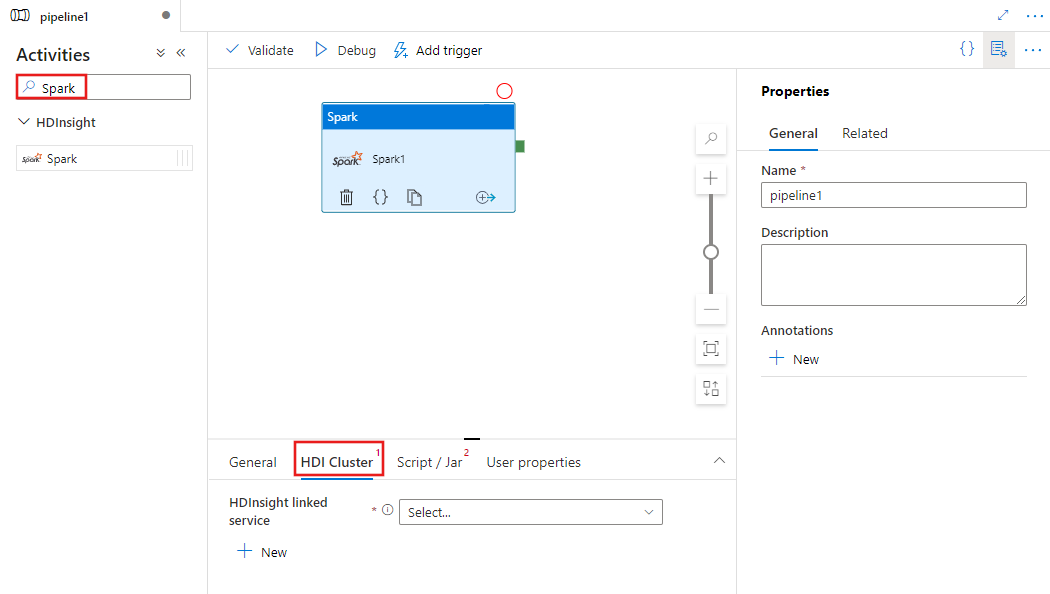
在管道的“活动”窗格中搜索“Spark”,然后将“Spark”活动拖到管道画布上。
在画布上选择新的 Spark 活动(如果尚未选择)。
选择“HDI 群集”选项卡以选择或创建新的链接到 HDInsight 群集的服务,该群集将用于执行 Spark 传输活动。
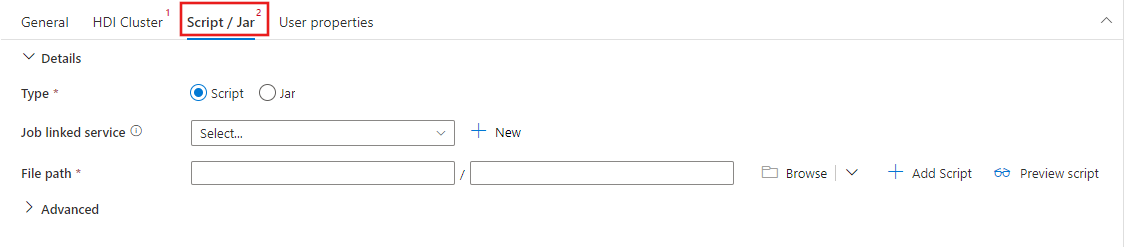
选择“脚本 / Jar”选项卡以选择或创建新的作业链接服务到将托管脚本的 Azure 存储帐户。 指定要在其中执行的文件的路径。 还可以配置高级详细信息,包括代理用户、调试配置以及要传递给脚本的自变量和 Spark 配置参数。
Spark 活动属性
下面是 Spark 活动的示例 JSON 定义:
{
"name": "Spark Activity",
"description": "Description",
"type": "HDInsightSpark",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"sparkJobLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"rootPath": "adfspark",
"entryFilePath": "test.py",
"sparkConfig": {
"ConfigItem1": "Value"
},
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
]
}
}
下表描述了 JSON 定义中使用的 JSON 属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| name | 管道中活动的名称。 | 是 |
| description | 描述活动用途的文本。 | 否 |
| type | 对于 Spark 活动,活动类型是 HDInsightSpark。 | 是 |
| linkedServiceName | 运行 Spark 程序的 HDInsight Spark 链接服务的名称。 若要了解此链接服务,请参阅计算链接服务一文。 | 是 |
| SparkJobLinkedService | 用于保存 Spark 作业文件、依赖项和日志的 Azure 存储链接服务。 此处仅支持 Azure Blob 存储和 ADLS Gen2 链接服务 。 如果未指定此属性的值,将使用与 HDInsight 群集关联的存储。 此属性的值只能是 Azure 存储链接服务。 | 否 |
| rootPath | 包含 Spark 文件的 Azure Blob 容器和文件夹。 文件名称需区分大小写。 有关此文件夹结构的详细信息,请参阅“文件夹结构”部分(下一部分)。 | 是 |
| entryFilePath | Spark 代码/包的根文件夹的相对路径 条目文件必须是 Python 文件或 .jar 文件。 | 是 |
| className | 应用程序的 Java/Spark main 类 | 否 |
| 参数 | Spark 程序的命令行参数列表。 | 否 |
| proxyUser | 用于模拟执行 Spark 程序的用户帐户 | 否 |
| sparkConfig | 指定在以下主题中列出的 Spark 配置属性的值:Spark 配置 - 应用程序属性。 | 否 |
| getDebugInfo | 指定何时将 Spark 日志文件复制到 HDInsight 群集使用的(或者)sparkJobLinkedService 指定的 Azure 存储。 允许的值:None、Always 或 Failure。 默认值:无。 | 否 |
文件夹结构
与 Pig/Hive 作业相比,Spark 作业的可扩展性更高。 对于 Spark 作业,可以提供多个依赖项,例如 jar 包(放在 Java CLASSPATH 中)、Python 文件(放在 PYTHONPATH 中)和其他任何文件。
在 HDInsight 链接服务引用的 Azure Blob 存储中创建以下文件夹结构。 然后,将依赖文件上传到 entryFilePath 表示的根文件夹中的相应子文件夹。 例如,将 Python 文件上传到根文件夹的 pyFiles 子文件夹,将 jar 文件上传到根文件夹的 jars 子文件夹。 在运行时,此服务需要 Azure Blob 存储中的以下文件夹结构:
| 路径 | 说明 | 必需 | 类型 |
|---|---|---|---|
.(根) |
Spark 作业在存储链接服务中的根路径 | 是 | 文件夹 |
| <用户定义> | 指向 Spark 作业入口文件的路径 | 是 | 文件 |
| ./jars | 此文件夹下的所有文件将被上传并放置在群集的 Java 类路径中 | 否 | 文件夹 |
| ./pyFiles | 此文件夹下的所有文件将上传并放置在群集的 PYTHONPATH 中 | 否 | 文件夹 |
| ./files | 此文件夹下的所有文件将上传并放置在执行器工作目录中 | 否 | 文件夹 |
| ./archives | 此文件夹下的所有文件未经压缩 | 否 | 文件夹 |
| ./logs | 包含 Spark 群集的日志的文件夹。 | 否 | 文件夹 |
以下示例显示了一个在 HDInsight 链接服务引用的 Azure Blob 存储中包含两个 Spark 作业文件的存储。
SparkJob1
main.jar
files
input1.txt
input2.txt
jars
package1.jar
package2.jar
logs
archives
pyFiles
SparkJob2
main.py
pyFiles
scrip1.py
script2.py
logs
archives
jars
files
相关内容
参阅以下文章了解如何以其他方式转换数据: