使用自动化 ML 和 Python (SDK v1) 训练回归模型

本文介绍如何通过 Azure 机器学习 Python SDK 使用 Azure 机器学习自动化 ML 训练回归模型。 回归模型预测纽约市 (NYC) 运营的出租车的乘客费用。 使用 Python SDK 编写代码,以配置包含已准备数据的工作区、使用自定义参数在本地训练模型以及浏览结果。
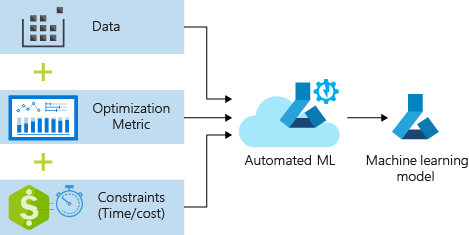
该过程接受训练数据和配置设置。 它自动循环访问不同特征规范化/标准化方法、模型和超参数设置的组合,以实现最佳模型。 下图演示了回归模型训练的过程流:
先决条件
Azure 订阅。 可以创建 Azure 机器学习的免费或付费帐户。
一个 Azure 机器学习工作区或一个计算实例。 要准备这些资源,请参阅快速入门:开始使用 Azure 机器学习。
通过将笔记本加载到工作区,获取已为教程练习准备的示例数据:
在 Azure 机器学习工作室中转到你的工作区,选择“笔记本”,然后选择“示例”选项卡。
在笔记本列表中,展开“示例”>“SDK v1”>“教程”>“regression-automl-nyc-taxi-data”节点。
选择“regression-automated-ml.ipynb”笔记本。
若要在本教程中运行每个笔记本单元,请选择“克隆此文件”。
备用方法:如果需要,可以在本地环境中运行教程练习。 本教程在 GitHub 上的 Azure 机器学习笔记本存储库中提供。 对于此方法,请按照以下步骤获取所需的包:
在本地计算机上运行
pip install azureml-opendatasets azureml-widgets命令以获取所需的包。
下载并准备数据
“开放数据集”包内有表示各个数据源的类(如 NycTlcGreen),用于在下载前轻松筛选日期参数。
以下代码导入必要的包:
from azureml.opendatasets import NycTlcGreen
import pandas as pd
from datetime import datetime
from dateutil.relativedelta import relativedelta
第一步是为出租车数据创建数据帧。 如果是在非 Spark 环境中,“开放数据集”包仅允许特定类一次下载一个月的数据。 此方法有助于避免大型数据集可能出现的 MemoryError 问题。
若要下载出租车数据,请一次迭代提取一个月。 在将下一组数据追加到 green_taxi_df 数据帧之前,请从每个月随机采样 2,000 条记录,然后预览数据。 此方法有助于避免膨胀数据帧。
以下代码创建数据帧、提取数据并将其加载到数据帧中:
green_taxi_df = pd.DataFrame([])
start = datetime.strptime("1/1/2015","%m/%d/%Y")
end = datetime.strptime("1/31/2015","%m/%d/%Y")
for sample_month in range(12):
temp_df_green = NycTlcGreen(start + relativedelta(months=sample_month), end + relativedelta(months=sample_month)) \
.to_pandas_dataframe()
green_taxi_df = green_taxi_df.append(temp_df_green.sample(2000))
green_taxi_df.head(10)
下表显示了示例出租车数据中的多个值列:
| vendorID | lpepPickupDatetime | lpepDropoffDatetime | passengerCount | tripDistance | puLocationId | doLocationId | pickupLongitude | pickupLatitude | dropoffLongitude | ... | paymentType | fareAmount | extra | mtaTax | improvementSurcharge | tipAmount | tollsAmount | ehailFee | totalAmount | tripType |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 2015-01-30 18:38:09 | 2015-01-30 19:01:49 | 1 | 1.88 | 无 | 无 | -73.996155 | 40.690903 | -73.964287 | ... | 1 | 15.0 | 1.0 | 0.5 | 0.3 | 4.00 | 0.0 | 无 | 20.80 | 1.0 |
| 1 | 2015-01-17 23:21:39 | 2015-01-17 23:35:16 | 1 | 2.70 | 无 | 无 | -73.978508 | 40.687984 | -73.955116 | ... | 1 | 11.5 | 0.5 | 0.5 | 0.3 | 2.55 | 0.0 | 无 | 15.35 | 1.0 |
| 2 | 2015-01-16 01:38:40 | 2015-01-16 01:52:55 | 1 | 3.54 | 无 | 无 | -73.957787 | 40.721779 | -73.963005 | ... | 1 | 13.5 | 0.5 | 0.5 | 0.3 | 2.80 | 0.0 | 无 | 17.60 | 1.0 |
| 2 | 2015-01-04 17:09:26 | 2015-01-04 17:16:12 | 1 | 1.00 | 无 | 无 | -73.919914 | 40.826023 | -73.904839 | ... | 2 | 6.5 | 0.0 | 0.5 | 0.3 | 0.00 | 0.0 | 无 | 7.30 | 1.0 |
| 1 | 2015-01-14 10:10:57 | 2015-01-14 10:33:30 | 1 | 5.10 | 无 | 无 | -73.943710 | 40.825439 | -73.982964 | ... | 1 | 18.5 | 0.0 | 0.5 | 0.3 | 3.85 | 0.0 | 无 | 23.15 | 1.0 |
| 2 | 2015-01-19 18:10:41 | 2015-01-19 18:32:20 | 1 | 7.41 | 无 | 无 | -73.940918 | 40.839714 | -73.994339 | ... | 1 | 24.0 | 0.0 | 0.5 | 0.3 | 4.80 | 0.0 | 无 | 29.60 | 1.0 |
| 2 | 2015-01-01 15:44:21 | 2015-01-01 15:50:16 | 1 | 1.03 | 无 | 无 | -73.985718 | 40.685646 | -73.996773 | ... | 1 | 6.5 | 0.0 | 0.5 | 0.3 | 1.30 | 0.0 | 无 | 8.60 | 1.0 |
| 2 | 2015-01-12 08:01:21 | 2015-01-12 08:14:52 | 5 | 2.94 | 无 | 无 | -73.939865 | 40.789822 | -73.952957 | ... | 2 | 12.5 | 0.0 | 0.5 | 0.3 | 0.00 | 0.0 | 无 | 13.30 | 1.0 |
| 1 | 2015-01-16 21:54:26 | 2015-01-16 22:12:39 | 1 | 3.00 | 无 | 无 | -73.957939 | 40.721928 | -73.926247 | ... | 1 | 14.0 | 0.5 | 0.5 | 0.3 | 2.00 | 0.0 | 无 | 17.30 | 1.0 |
| 2 | 2015-01-06 06:34:53 | 2015-01-06 06:44:23 | 1 | 2.31 | 无 | 无 | -73.943825 | 40.810257 | -73.943062 | ... | 1 | 10.0 | 0.0 | 0.5 | 0.3 | 2.00 | 0.0 | 无 | 12.80 | 1.0 |
移除训练或其他功能生成不需要的一些列,这很有用。 例如,可移除 lpepPickupDatetime 列,因为自动化 ML 会自动处理基于时间的功能。
以下代码从示例数据中移除 14 列:
columns_to_remove = ["lpepDropoffDatetime", "puLocationId", "doLocationId", "extra", "mtaTax",
"improvementSurcharge", "tollsAmount", "ehailFee", "tripType", "rateCodeID",
"storeAndFwdFlag", "paymentType", "fareAmount", "tipAmount"
]
for col in columns_to_remove:
green_taxi_df.pop(col)
green_taxi_df.head(5)
清理数据
下一步是清理数据。
以下代码对新数据帧运行 describe() 函数,以生成各个字段的汇总统计信息:
green_taxi_df.describe()
下表显示了示例数据中剩余字段的摘要统计信息:
| vendorID | passengerCount | tripDistance | pickupLongitude | pickupLatitude | dropoffLongitude | dropoffLatitude | totalAmount | |
|---|---|---|---|---|---|---|---|---|
| count | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 |
| 平均值 | 1.777625 | 1.373625 | 2.893981 | -73.827403 | 40.689730 | -73.819670 | 40.684436 | 14.892744 |
| 标准 | 0.415850 | 1.046180 | 3.072343 | 2.821767 | 1.556082 | 2.901199 | 1.599776 | 12.339749 |
| min | 1.00 | 0.00 | 0.00 | -74.357101 | 0.00 | -74.342766 | 0.00 | -120.80 |
| 25% | 2.00 | 1.00 | 1.05 | -73.959175 | 40.699127 | -73.966476 | 40.699459 | 8.00 |
| 50% | 2.00 | 1.00 | 1.93 | -73.945049 | 40.746754 | -73.944221 | 40.747536 | 11.30 |
| 75% | 2.00 | 1.00 | 3.70 | -73.917089 | 40.803060 | -73.909061 | 40.791526 | 17.80 |
| max | 2.00 | 8.00 | 154.28 | 0.00 | 41.109089 | 0.00 | 40.982826 | 425.00 |
摘要统计信息显示,有几个字段是离群值,会降低模型准确度。 若要解决此问题,请筛选纬度/经度 (lat/long) 字段,以便值出于曼哈顿区域的边界内。 此方法会筛选出较长的出租车行程,或者在与其他特征的关系上属于离群值的行程。
然后,筛选值大于 0 但小于 31 英里(两个纬度/经度对之间的迭加正弦波距离)的 tripDistance 字段。 此方法会消除行程费用不一致的长离群行程。
最后,totalAmount 字段包含出租车费用的负值,这在模型上下文中毫无意义。 passengerCount 字段还包含最小值为零的不良数据。
以下代码使用查询函数筛选掉这些异常值。 然后,该代码将移除训练不需要的最后几个列:
final_df = green_taxi_df.query("pickupLatitude>=40.53 and pickupLatitude<=40.88")
final_df = final_df.query("pickupLongitude>=-74.09 and pickupLongitude<=-73.72")
final_df = final_df.query("tripDistance>=0.25 and tripDistance<31")
final_df = final_df.query("passengerCount>0 and totalAmount>0")
columns_to_remove_for_training = ["pickupLongitude", "pickupLatitude", "dropoffLongitude", "dropoffLatitude"]
for col in columns_to_remove_for_training:
final_df.pop(col)
此序列中的最后一步是对数据再次调用 describe() 函数,以确保按预期清理。 至此,已有经过准备和清理的出租车、节假日和天气数据集,用于机器学习模型训练:
final_df.describe()
配置工作区
从现有工作区创建工作区对象。 工作区是可接受 Azure 订阅和资源信息的类。 它还可创建云资源来监视和跟踪模型运行。
以下代码调用 Workspace.from_config() 函数来读取 config.json 文件并将身份验证详细信息加载到名为 ws 的对象中。
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
在本教程中,ws 对象在代码的其余部分使用。
将数据拆分为训练集和测试集
使用 scikit-learn 库中的 train_test_split 函数将数据拆分为训练集和测试集。 该函数将数据分成用于模型训练的 x(特征)数据集和用于测试的 y(用于预测的值)数据集。
test_size 参数决定了分配用于测试的数据的百分比。 random_state 参数设置随机生成器的种子。这样一来,训练-测试拆分是有确定性的。
以下代码调用 train_test_split 函数来加载 x 和 y 数据集:
from sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(final_df, test_size=0.2, random_state=223)
此步骤的目的是准备用于测试已完成模型的数据点,确保其未曾用于模型训练。 这些点用于测量真正的准确性。 训练良好的模型可以从看不见的数据进行准确的预测。 现已准备好用于自动训练机器学习模型的数据。
自动训练模型
若要自动训练模型,请执行以下步骤:
定义试验运行的设置。 将训练数据附加到配置,并修改用于控制训练过程的设置。
提交用于模型优化的试验。 在提交试验以后,此过程会根据定义的约束循环访问不同的机器学习算法和超参数设置。 它通过优化准确性指标来选择最佳拟合模型。
定义训练设置
定义用于训练的试验参数和模型设置。 查看设置的完整列表。 提交具有这些默认设置的试验大约需要 5-20 分钟。 若要减少运行时,请减少 experiment_timeout_hours 参数。
| properties | 本教程中的值 | 说明 |
|---|---|---|
iteration_timeout_minutes |
10 | 每个迭代的时间限制(分钟)。 对于每次迭代需要更多时间的更大数据集,增加此值。 |
experiment_timeout_hours |
0.3 | 在试验结束之前,所有合并的迭代所花费的最大时间量(以小时为单位)。 |
enable_early_stopping |
True | 如果分数在短期内没有提高,则进行标记,以提前终止。 |
primary_metric |
spearman_correlation | 要优化的指标。 根据此指标选择最佳拟合模型。 |
featurization |
auto | auto 值允许试验预处理输入数据,包含处理缺失的数据、将文本转换为数字,等等。 |
verbosity |
logging.INFO | 控制日志记录的级别。 |
n_cross_validations |
5 | 在验证数据未指定的情况下,需执行的交叉验证拆分的数目。 |
以下代码提交试验:
import logging
automl_settings = {
"iteration_timeout_minutes": 10,
"experiment_timeout_hours": 0.3,
"enable_early_stopping": True,
"primary_metric": 'spearman_correlation',
"featurization": 'auto',
"verbosity": logging.INFO,
"n_cross_validations": 5
}
以下代码可让你使用定义的训练设置作为 AutoMLConfig 对象的 **kwargs 参数。 另请指定训练数据和模型的类型,后者在此示例中为 regression。
from azureml.train.automl import AutoMLConfig
automl_config = AutoMLConfig(task='regression',
debug_log='automated_ml_errors.log',
training_data=x_train,
label_column_name="totalAmount",
**automl_settings)
注意
自动化 ML 预处理步骤(特征规范化、处理缺失数据,将文本转换为数字等)成为基础模型的一部分。 使用模型进行预测时,训练期间应用的相同预处理步骤将自动应用于输入数据。
训练自动回归模型
在工作区中创建一个试验对象。 试验充当单个作业的容器。 将定义的 automl_config 对象传递至试验,并将输出设置为 True,以便查看作业过程中的进度。
启动试验后,显示的输出会随着试验的运行实时更新。 可以看到每次迭代的模型类型、运行持续时间以及训练准确性。 字段 BEST 根据指标类型跟踪运行情况最好的训练分数:
from azureml.core.experiment import Experiment
experiment = Experiment(ws, "Tutorial-NYCTaxi")
local_run = experiment.submit(automl_config, show_output=True)
输出如下:
Running on local machine
Parent Run ID: AutoML_1766cdf7-56cf-4b28-a340-c4aeee15b12b
Current status: DatasetFeaturization. Beginning to featurize the dataset.
Current status: DatasetEvaluation. Gathering dataset statistics.
Current status: FeaturesGeneration. Generating features for the dataset.
Current status: DatasetFeaturizationCompleted. Completed featurizing the dataset.
Current status: DatasetCrossValidationSplit. Generating individually featurized CV splits.
Current status: ModelSelection. Beginning model selection.
****************************************************************************************************
ITERATION: The iteration being evaluated.
PIPELINE: A summary description of the pipeline being evaluated.
DURATION: Time taken for the current iteration.
METRIC: The result of computing score on the fitted pipeline.
BEST: The best observed score thus far.
****************************************************************************************************
ITERATION PIPELINE DURATION METRIC BEST
0 StandardScalerWrapper RandomForest 0:00:16 0.8746 0.8746
1 MinMaxScaler RandomForest 0:00:15 0.9468 0.9468
2 StandardScalerWrapper ExtremeRandomTrees 0:00:09 0.9303 0.9468
3 StandardScalerWrapper LightGBM 0:00:10 0.9424 0.9468
4 RobustScaler DecisionTree 0:00:09 0.9449 0.9468
5 StandardScalerWrapper LassoLars 0:00:09 0.9440 0.9468
6 StandardScalerWrapper LightGBM 0:00:10 0.9282 0.9468
7 StandardScalerWrapper RandomForest 0:00:12 0.8946 0.9468
8 StandardScalerWrapper LassoLars 0:00:16 0.9439 0.9468
9 MinMaxScaler ExtremeRandomTrees 0:00:35 0.9199 0.9468
10 RobustScaler ExtremeRandomTrees 0:00:19 0.9411 0.9468
11 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9077 0.9468
12 StandardScalerWrapper LassoLars 0:00:15 0.9433 0.9468
13 MinMaxScaler ExtremeRandomTrees 0:00:14 0.9186 0.9468
14 RobustScaler RandomForest 0:00:10 0.8810 0.9468
15 StandardScalerWrapper LassoLars 0:00:55 0.9433 0.9468
16 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9026 0.9468
17 StandardScalerWrapper RandomForest 0:00:13 0.9140 0.9468
18 VotingEnsemble 0:00:23 0.9471 0.9471
19 StackEnsemble 0:00:27 0.9463 0.9471
浏览结果
通过 Jupyter 小组件浏览自动训练的结果。 此小组件支持查看每个作业迭代的图和表,以及训练准确度指标和元数据。 此外,可以筛选不同于下拉选择器中的主要指标的准确度指标。
以下代码会生成一个图形,用来浏览结果:
from azureml.widgets import RunDetails
RunDetails(local_run).show()
Jupyter 小组件的运行详细信息:

Jupyter 小组件的绘图图表:

检索最佳模型
以下代码可让你从迭代中选择最佳模型。 get_output 函数针对上次拟合调用返回最佳运行和拟合的模型。 在 get_output 函数上使用重载,可以针对任何记录的指标或特定的迭代来检索最佳运行和拟合的模型。
best_run, fitted_model = local_run.get_output()
print(best_run)
print(fitted_model)
测试最佳模型准确度
使用最佳模型针对测试数据集运行预测,以便预测出租车费。 predict 函数使用最佳模型根据 x_test 数据集预测 y(行程费用)的值。
以下代码从 y_predict 数据集输出前 10 个预测的成本值:
y_test = x_test.pop("totalAmount")
y_predict = fitted_model.predict(x_test)
print(y_predict[:10])
计算结果的 root mean squared error。 将 y_test 数据帧转换为列表并与预测值比较。 mean_squared_error 函数接受两个数组的值,计算两个数组之间的平均平方误差。 取结果的平方根会将相同单位的误差提供为 y 差异(成本)。 它大致指出了出租车费预测值与实际费用之间有多大的差距。
from sklearn.metrics import mean_squared_error
from math import sqrt
y_actual = y_test.values.flatten().tolist()
rmse = sqrt(mean_squared_error(y_actual, y_predict))
rmse
运行以下代码,使用完整的 y_actual 和 y_predict 数据集来计算平均绝对百分比误差 (MAPE)。 此指标计算每个预测值和实际值之间的绝对差,将所有差值求和。 然后,它将总和表示为实际值总和的百分比。
sum_actuals = sum_errors = 0
for actual_val, predict_val in zip(y_actual, y_predict):
abs_error = actual_val - predict_val
if abs_error < 0:
abs_error = abs_error * -1
sum_errors = sum_errors + abs_error
sum_actuals = sum_actuals + actual_val
mean_abs_percent_error = sum_errors / sum_actuals
print("Model MAPE:")
print(mean_abs_percent_error)
print()
print("Model Accuracy:")
print(1 - mean_abs_percent_error)
输出如下:
Model MAPE:
0.14353867606052823
Model Accuracy:
0.8564613239394718
从两个预测准确度指标来看,该模型可以很好地根据数据集的特征来预测出租车费,误差率大约为 15%,通常在 4.00 美元上下。
传统的机器学习模型开发过程是高度资源密集型。 它需要大量的领域知识和时间投资来运行和比较数十个模型的结果。 使用自动化机器学习是一种很好的方式,可以针对方案快速测试许多不同的模型。
清理资源
如果不打算处理其他 Azure 机器学习教程,请完成以下步骤以移除不再需要的资源。
停止计算
如果使用了计算,则可以在不使用虚拟机时停止虚拟机并降低成本:
转到 Azure 机器学习工作室中的工作区,然后选择“计算”。
在列表中,选择要停止的计算,然后选择“停止”。
准备好再次使用计算时,可以重启虚拟机。
删除其他资源
如果不打算使用本教程中创建的资源,可以将其删除以避免产生后续费用。
按照以下步骤移除资源组和所有资源:
在 Azure 门户中,转到资源组。
在列表中,选择在本教程中创建的资源组,然后选择“删除资源组”。
在收到确认提示时输入资源组名称,然后选择“删除”。
如果要保留资源组并仅删除单个工作区,请执行以下步骤:
在 Azure 门户中,转到包含要移除的工作区的资源组。
选择该工作区,选择“属性”,然后选择“删除”。