为 Azure 机器学习设置 Python 开发环境 (v1)

了解如何为 Azure 机器学习配置 Python 开发环境。
下表描述了本文所述的每个开发环境及其优点和缺点。
| 环境 | 优点 | 缺点 |
|---|---|---|
| 本地环境 | 可以全面控制开发环境和依赖项。 使用所选的任何生成工具、环境或 IDE 来运行。 | 入门需要更长的时间。 必须安装必要的 SDK 包,此外,必须安装一个环境(如果尚未安装)。 |
| Data Science Virtual Machine (DSVM) | 类似于基于云的计算实例(已预装 Python 和 SDK),但预装了其他流行的数据科学和机器学习工具。 易于缩放,并可与其他自定义工具和工作流结合使用。 | 与基于云的计算实例相比,入门过程更慢。 |
| Azure 机器学习计算实例 | 最容易入门。 整个 SDK 已安装在工作区 VM 中,笔记本教程已预先克隆,随时可供运行。 | 缺少对开发环境和依赖项的控制。 Linux VM 会产生额外的成本(可以停止不使用的 VM,以免产生费用)。 请参阅定价详细信息。 |
| Azure Databricks | 非常适合用于在可缩放的 Apache Spark 平台上运行大规模的密集型机器学习工作流。 | 对于试验性机器学习或较小规模的试验和工作流而言性能过剩。 Azure Databricks 会产生额外的成本。 请参阅定价详细信息。 |
本文还将提供以下工具的用法提示:
Jupyter Notebook:如果已在使用 Jupyter Notebook,则应安装 SDK 的某些附加功能。
Visual Studio Code:如果使用 Visual Studio Code,Azure 机器学习扩展包含对 Python 的广泛语言支持,还包含便于更方便、更高效地使用 Azure 机器学习的功能。
先决条件
- Azure 机器学习工作区。 如果没有 Azure 机器学习工作区,则可以通过 Azure 门户、Azure CLI 和 Azure 资源管理器模板来创建一个。
仅限本地和 DSVM:创建一个工作区配置文件
工作区配置文件是一个 JSON 文件,用于告知 SDK 如何与 Azure 机器学习工作区进行通信。 该文件命名为 config.json,其格式如下:
{
"subscription_id": "<subscription-id>",
"resource_group": "<resource-group>",
"workspace_name": "<workspace-name>"
}
此 JSON 文件必须采用包含 Python 脚本或 Jupyter Notebook 的目录结构。 它可以位于同一目录(名为 .azureml 的子目录)中,也可以位于父目录中。
若要从代码使用此文件,请使用 Workspace.from_config 方法。 此代码从文件中加载信息,并连接到工作区。
使用下列方法之一创建工作区配置文件:
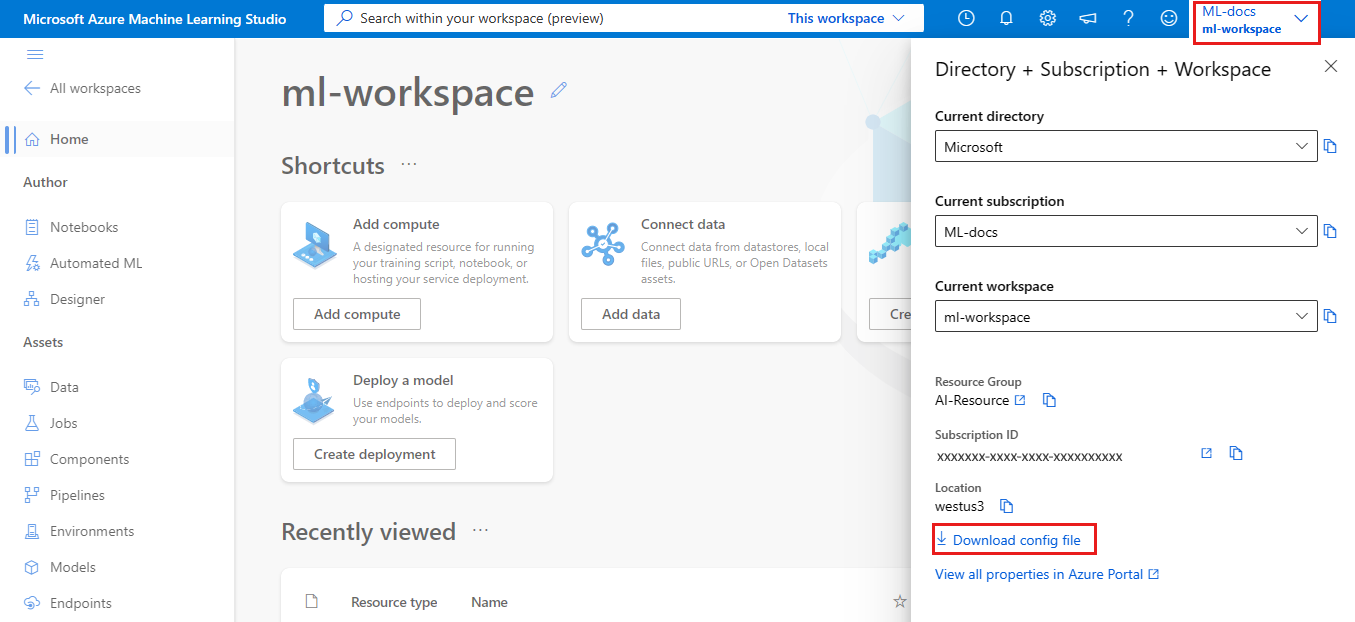
Azure 门户
下载文件:在 Azure 门户中,选择工作区的“概述”部分中的“下载 config.json”。
Azure 机器学习 Python SDK
创建一个脚本,用于连接到你的 Azure 机器学习工作区,使用
write_config方法生成文件并将其另存为 .azureml/config.json。 确保将subscription_id、resource_group和workspace_name替换为你自己的值。from azureml.core import Workspace subscription_id = '<subscription-id>' resource_group = '<resource-group>' workspace_name = '<workspace-name>' try: ws = Workspace(subscription_id = subscription_id, resource_group = resource_group, workspace_name = workspace_name) ws.write_config() print('Library configuration succeeded') except: print('Workspace not found')
本地计算机或远程 VM 环境
你可以在本地计算机或远程虚拟机上设置环境,例如 Azure 机器学习计算实例或 Data Science VM。
若要配置本地开发环境或远程 VM,请执行以下操作:
创建 Python 虚拟环境(virtualenv,conda)。
重要
如果在 Linux 或 macOS 上操作,并使用除 bash 以外的 shell(例如 zsh),则在运行某些命令时可能会收到错误消息。 若要解决此问题,请使用
bash命令启动新的 bash shell,然后运行命令。激活新创建的 Python 虚拟环境。
若要将本地环境配置为使用你的 Azure 机器学习工作区,请创建一个工作区配置文件或使用现有文件。
设置本地环境后,便可以开始使用 Azure 机器学习。 若要开始,请参阅 Azure 机器学习 Python 入门指南。
Jupyter Notebook
运行本地 Jupyter Notebook 服务器时,建议为你的 Python 虚拟环境创建一个 IPython 内核。 这有助于确保实现预期的内核和包导入行为。
启用环境特定的 IPython 内核
conda install notebook ipykernel为你的 Python 虚拟环境创建一个内核。 请确保将
<myenv>替换为你的 Python 虚拟环境的名称。ipython kernel install --user --name <myenv> --display-name "Python (myenv)"启动 Jupyter Notebook 服务器
若要开始使用 Azure 机器学习和 Jupyter Notebook,请参阅 Azure 机器学习笔记本存储库。 另请参阅由社区主导的存储库 AzureML - 示例。
Visual Studio Code
若要使用 Visual Studio Code 进行开发:
安装 Azure 机器学习 Visual Studio Code 扩展(预览版)。
重要
此功能目前处于公开预览状态。 此预览版在提供时没有附带服务级别协议,我们不建议将其用于生产工作负荷。 某些功能可能不受支持或者受限。
有关详细信息,请参阅适用于 Azure 预览版的补充使用条款。
安装 Visual Studio Code 扩展后,请使用它来执行以下操作:
Azure 机器学习计算实例
Azure 机器学习计算实例是一个安全的基于云的 Azure 工作站,为数据科学家提供 Jupyter Notebook 服务器、JupyterLab 和一个完全托管的机器学习环境。
无需为计算实例安装或配置任何组件。
随时可从 Azure 机器学习工作区内部创建组件。 只需提供名称并指定 Azure VM 类型即可。 通过创建帮助入门的资源立即开始试用。
若要详细了解计算实例(包括如何安装包),请参阅创建和管理 Azure 机器学习计算实例。
除了 Jupyter Notebook 服务器和 JupyterLab 以外,还可以在 Azure 机器学习工作室内的集成笔记本功能中使用计算实例。
还可以使用 Azure 机器学习 Visual Studio Code 扩展以通过 VS Code 连接到远程计算实例。
数据科学虚拟机
Data Science VM 是一种可用作开发环境的自定义虚拟机 (VM) 映像。 它专为数据科学工作而设计,其中预配置了工具和软件,例如:
- TensorFlow、PyTorch、Scikit-learn、XGBoost 和 Azure 机器学习 SDK 等包
- Spark Standalone 和 Drill 等常用数据科学工具
- Azure CLI、AzCopy 和存储资源管理器等 Azure 工具
- Visual Studio Code 和 PyCharm 等集成开发环境 (IDE)
- Jupyter Notebook 服务器
有关更全面的工具列表,请参阅 Data Science VM 工具指南。
重要
如果你计划将 Data Science VM 用作训练或推理作业的计算目标,则仅 Ubuntu 受支持。
若要使用 Data Science VM 作为开发环境,请执行以下操作:
使用下列方法之一创建一个 Data Science VM:
使用 Azure CLI
若要创建 Ubuntu Data Science VM,请使用以下命令:
# create a Ubuntu Data Science VM in your resource group # note you need to be at least a contributor to the resource group in order to execute this command successfully # If you need to create a new resource group use: "az group create --name YOUR-RESOURCE-GROUP-NAME --location YOUR-REGION (For example: chinaeast2)" az vm create --resource-group YOUR-RESOURCE-GROUP-NAME --name YOUR-VM-NAME --image microsoft-dsvm:linux-data-science-vm-ubuntu:linuxdsvmubuntu:latest --admin-username YOUR-USERNAME --admin-password YOUR-PASSWORD --generate-ssh-keys --authentication-type password若要创建 Windows DSVM,请使用以下命令:
# create a Windows Server 2016 DSVM in your resource group # note you need to be at least a contributor to the resource group in order to execute this command successfully az vm create --resource-group YOUR-RESOURCE-GROUP-NAME --name YOUR-VM-NAME --image microsoft-dsvm:dsvm-windows:server-2016:latest --admin-username YOUR-USERNAME --admin-password YOUR-PASSWORD --authentication-type password
激活包含 Azure 机器学习 SDK 的 conda 环境。
对于 Ubuntu Data Science VM:
conda activate py36对于 Windows Data Science VM:
conda activate AzureML
若要将 Data Science VM 配置为使用你的 Azure 机器学习工作区,请创建一个工作区配置文件或使用现有的工作区配置文件。
你可以使用 Visual Studio Code 和 Azure 机器学习 Visual Studio Code 扩展(与本地环境类似)与 Azure 机器学习进行交互。
有关详细信息,请参阅 Data Science Virtual Machine。
后续步骤
- 在 Azure 机器学习中使用 MNIST 数据集来训练和部署模型。
- 请参阅适用于 Python 的 Azure 机器学习 SDK 参考。