单用户计算上的精细访问控制
本文介绍数据筛选功能,该功能可对单用户计算(配置了单用户访问模式的通用计算或作业计算)上运行的查询实现精细访问控制。 请参阅访问模式。
此数据筛选是在幕后使用无服务器计算执行的。
为何单用户计算上的某些查询需要数据筛选?
Unity Catalog 可让你使用以下功能在列和行级别控制对表格数据的访问(也称为精细访问控制):
当用户查询从引用表中排除数据的视图,或查询应用筛选器和掩码的表时,他们可以不受限制地使用以下任何计算资源:
- SQL 仓库
- 共享计算
但是,如果使用单用户计算来运行此类查询,则计算和工作区必须满足特定的要求:
单用户计算资源必须位于 Databricks Runtime 15.4 LTS 或更高版本上。
必须为工作区的作业、笔记本和增量实时表启用无服务器计算。
若要确认你的工作区区域是否支持无服务器计算,请参阅区域可用性受限的功能。
如果你的单用户计算资源和工作区满足这些要求,则每当你查询使用精细访问控制的视图或表时,都会自动运行数据筛选。
对具体化视图、流式表和标准视图的支持
除了动态视图、行筛选器和列掩码之外,数据筛选还支持对以下视图和表进行查询,而这些视图和表在运行 Databricks Runtime 15.3 及更低版本的单用户计算上不受支持:
-
在运行 Databricks Runtime 15.3 及更低版本的单用户计算中,对视图运行查询的用户必须对视图引用的表和视图具有
SELECT权限,这意味着不能使用视图来提供精细的访问控制。 在支持数据筛选的 Databricks Runtime 15.4 上,查询视图的用户不需要访问引用的表和视图。
单用户计算上的数据筛选的工作原理是怎样的?
每当查询访问以下数据库对象时,单用户计算资源都会将该查询传递给无服务器计算以执行数据筛选:
- 基于用户没有
SELECT权限的表生成的视图 - 动态视图
- 定义了行筛选器或列掩码的表
- 具体化视图和流式表
在下图中,用户对 table_1、view_2 和 table_w_rls(应用了行筛选器)具有 SELECT 权限。 用户对 view_2 引用的 table_2 没有 SELECT 权限。

对 table_1 的查询完全由单用户计算资源处理,因为不需要筛选。 对 view_2 和 table_w_rls 的查询需要执行数据筛选才能返回用户有权访问的数据。 这些查询由无服务器计算上的数据筛选功能进行处理。
会产生哪些成本?
客户需要为用于执行数据筛选操作的无服务器计算资源付费。 有关定价信息,请参阅平台层和加载项。
可以查询系统计费使用情况表,以查看已收取的费用。 例如,以下查询按用户细分计算成本:
SELECT usage_date,
sku_name,
identity_metadata.run_as,
SUM(usage_quantity) AS `DBUs consumed by FGAC`
FROM system.billing.usage
WHERE usage_date BETWEEN '2024-08-01' AND '2024-09-01'
AND billing_origin_product = 'FINE_GRAINED_ACCESS_CONTROL'
GROUP BY 1, 2, 3 ORDER BY 1;
查看启用数据筛选时的查询性能
单用户计算的 Spark UI 会显示指标,你可以使用这些指标来了解查询性能。 对于你针对计算资源运行的每个查询,“SQL/数据帧”选项卡会显示查询的图形表示形式。 如果查询涉及数据筛选,则 UI 会在图形底部显示“RemoteSparkConnectScan”操作程序节点。 该节点显示了可用于调查查询性能的指标。 请参阅在 Apache Spark UI 中查看计算信息。
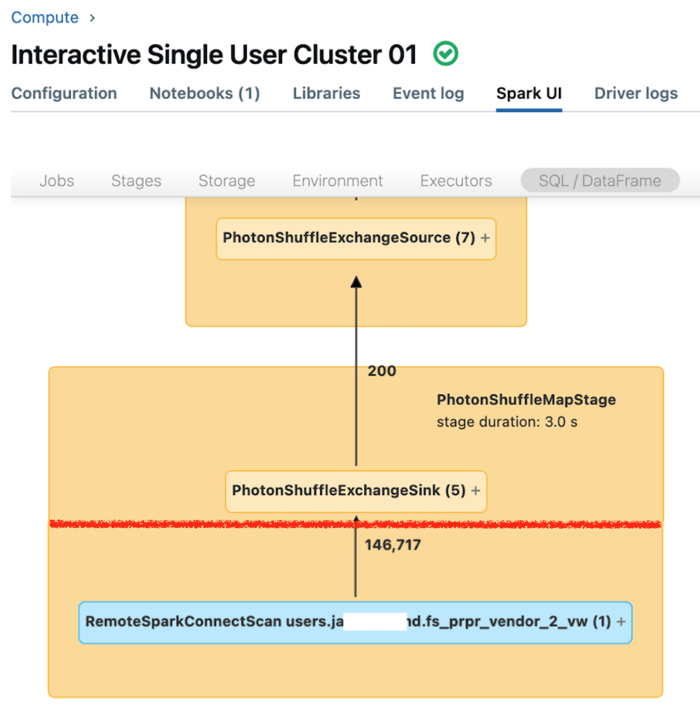
展开“RemoteSparkConnectScan”操作程序节点,查看可解决以下问题的指标:
- 数据筛选花费了多长时间? 查看“总远程执行时间”。
- 数据筛选后还剩下多少行? 查看“行数输出”。
- 数据筛选后返回了多少数据(以字节为单位)? 查看“行数输出大小”。
- 有多少数据文件已经过分区修剪,因此不必从存储中读取? 查看“已删除的文件”和“已删除文件的大小”。
- 有多少数据文件无法修剪,因此必须从存储中读取? 查看“已读取的文件”和“已读取文件的大小”。
- 在必须读取的文件中,有多少个文件已在缓存中? 查看“缓存命中大小”和“缓存未命中大小”。
限制
不支持对应用了行筛选器或列掩码的表执行写入或刷新表操作。
具体而言,不支持
INSERT,、DELETE、UPDATE、REFRESH TABLE和MERGE等 DML 操作。 只能从这些表中读取 (SELECT)。调用数据筛选时,默认会阻止自联接,但你可以通过在运行这些命令的计算机上将
spark.databricks.remoteFiltering.blockSelfJoins设置为 false 来允许自联接。在单用户计算资源上启用自联接之前请注意,数据筛选功能处理的自联接查询可能会返回同一远程表的不同快照。