本文介绍如何管理 Azure Databricks 计算,包括显示、编辑、启动、终止、删除、控制访问权限以及监视性能和日志。 还可以使用群集 API 以编程方式管理计算。
查看计算
若要查看计算,请单击工作区边栏中的“![]() 计算”。
计算”。
左侧有两列,指示计算是否已固定,以及计算的状态。 将鼠标悬停在状态上可获取详细信息。
以 JSON 文件的形式查看计算配置
有时,将计算配置视为 JSON 会很有帮助。 尤其是当你想要使用群集 API 创建相似的计算时,此方法特别有用。 查看现有计算时,转到“配置”选项卡,单击此选项卡右上角的“JSON”,复制该 JSON 并将其粘贴到 API 调用中。 JSON 视图是只读的。
固定计算
计算在终止 30 天后会永久删除。 若要在计算已终止超过 30 天后保留通用计算配置,管理员可以固定计算。 最多可以固定 100 个计算资源。
管理员可以通过单击固定图标,从计算列表或计算详细信息页固定计算。
编辑计算
可在计算详细信息 UI 中编辑计算的配置。
注意
- 附加到计算的笔记本和作业在编辑后将保持附加状态。
- 在计算上安装的库在编辑后将保持安装状态。
- 如果要编辑正在运行的计算的任何属性(计算大小和权限除外),则必须重启它。 这可能会影响当前正在使用该计算的用户。
- 只能编辑正在运行或已终止的计算。 但可以在计算详细信息页上更新未处于这些状态的计算的权限。
克隆计算
若要克隆现有计算,请从计算的 ![]() kebab 菜单中选择“克隆”。
kebab 菜单中选择“克隆”。
选择“克隆”后,会打开计算创建 UI,其中预先填充了计算配置。 克隆中不包括以下属性:
- 计算权限
- 附加的笔记本
如果不想在克隆的计算中包括以前安装的库,请单击“创建计算”按钮旁边的下拉菜单,然后选择“创建使不使用库”。
计算权限
计算有四个权限级别:“无权限”、“可附加到”、“可重启”和“可管理”。 有关详细信息,请参阅计算 ACL。
注意
不会从群集的 Spark 驱动程序日志 stdout 和 stderr 流中修订机密。 为了保护敏感数据,默认情况下,只有由对作业、单用户访问模式和共享访问模式群集具有“CAN MANAGE”权限的用户才能查看 Spark 驱动程序日志。 若要允许具有“CAN ATTACH TO”或“CAN RESTART”权限的用户查看这些群集上的日志,请在群集配置中设置以下 Spark 配置属性:spark.databricks.acl.needAdminPermissionToViewLogs false。
在“无隔离共享”访问模式群集上,具有“CAN ATTACH TO”或“CAN MANAGE”权限的用户可以查看 Spark 驱动程序日志。 若要限制只有具有“CAN MANAGE”权限的用户才能读取日志,请将 spark.databricks.acl.needAdminPermissionToViewLogs 设置为 true。
请参阅 Spark 配置来了解如何将 Spark 属性添加到群集配置。
配置计算权限
此部分介绍如何使用工作区 UI 来管理权限。 还可以使用权限 API 或 Databricks Terraform 提供程序。
必须对计算具有“可管理”权限才能配置计算权限。
- 在边栏中,单击“计算”。
- 在计算的行上,单击右侧的串形菜单
 ,然后选择“编辑权限”。
,然后选择“编辑权限”。 - 在“权限设置”中,单击“选择用户、组或服务主体...”下拉菜单,然后选择用户、组或服务主体。
- 从“权限”下拉菜单中选择权限。
- 依次点击“添加”、“保存”。
终止计算
若要保存计算资源,可以终止计算。 存储已终止计算的配置,以便今后可以重用(或者在作业中自动启动)该群集。 可以手动终止计算,也可以将计算配置为在处于不活动状态一定时间后自动终止。 当终止的计算数超过 150 时,将删除最早的计算。
除非计算已固定或重启,否则会在终止该计算 30 天后,自动将其永久删除。
终止的计算显示在计算列表中,计算名称左侧有灰色圆圈。
注意
在新的作业计算上运行作业时(建议做法),计算将终止,并且在作业完成后无法重启。 另一方面,如果计划在已终止的现有通用计算上运行作业,则该计算将自动启动。
手动终止
可以从计算列表(单击计算行上的方块)或计算详细信息页(单击“终止”)中手动终止计算。
自动终止
还可以为计算设置自动终止。 在计算创建过程中,可以指定希望计算在处于不活动状态几分钟后终止。
如果当前时间与计算上运行的最后一个命令之间的差值大于处于不活动状态指定时间,则 Azure Databricks 会自动终止该计算。
当计算上的所有命令(包括 Spark 作业、结构化流式处理和 JDBC 调用)执行完毕时,该计算被视为处于不活动状态。
警告
- 计算不会报告使用 DStreams 时产生的活动。 这意味着自动终止的计算在运行 DStreams 时可能会被终止。 请关闭针对运行 DStreams 的计算的自动终止功能,或考虑使用结构化流式处理。
- 空闲计算在终止之前的不活动期间会继续累积 DBU 和云实例费用。
配置自动终止
可以在新的计算 UI 中配置自动终止。 确保选中此框,并在“在非活动 ___ 分钟后终止”设置中输入分钟数。
可通过清除“自动终止”复选框或通过将处于不活动状态的时间指定为 0 来选择退出自动终止。
注意
自动终止在最新的 Spark 版本中最受支持。 较早的 Spark 版本具有已知的限制,这可能会导致计算活动的报告不准确。 例如,运行 JDBC、R 或流式处理命令的计算可能会报告过时的活动时间,导致计算提前终止。 请升级到最新的 Spark 版本,以从 bug 修补程序和改进的自动终止功能中受益。
意外终止
有时,计算会意外终止,而不是手动终止或所配置的自动终止。
有关终止原因和修正步骤的列表,请参阅知识库。
删除计算
删除计算会终止计算并删除其配置。 若要删除计算,请从计算的 ![]() 菜单中选择“删除”。
菜单中选择“删除”。
警告
不能撤消此操作。
若要删除固定计算,必须先由管理员取消固定该计算。
还可以调用群集 API 终结点,以编程方式删除计算。
重启计算
可以从计算列表、计算详细信息页或笔记本重启先前已终止的计算。 还可以调用群集 API 终结点,以编程方式启动计算。
Azure Databricks 使用计算的唯一群集 ID 标识该计算。 启动已终止的计算后,Databricks 将重新创建具有相同 ID 的计算,自动安装所有库,然后重新附加笔记本。
注意
如果使用的是试用版工作区并且该试用版已过期,则将无法启动计算。
重启计算以使用最新映像对其进行更新
重启计算时,它会获取计算资源容器和 VM 主机的最新映像。 为长时间运行的计算(例如用于处理流数据的计算)安排定期重启很重要。
由你负责定期重启所有计算资源,使映像采用最新的映像版本保持为最新。
Notebook 示例:查找长时间运行的计算
如果你是工作区管理员,则可以运行一个可以确定每个计算已经运行的时长的脚本,并选择在这些计算的运行时长超过指定天数时重启它们。 Azure Databricks 将此脚本作为笔记本提供。
脚本的第一行定义配置参数:
min_age_output:计算可以运行的最大天数。 默认为 1。perform_restart:如果为True,脚本将重启运行时长大于min_age_output所指定的天数的任何计算。 默认值为False,它会确定长时间运行的计算,但不会重启它们。secret_configuration:使用机密范围和密钥名称替换REPLACE_WITH_SCOPE和REPLACE_WITH_KEY。 有关设置机密的更多详细信息,请参阅笔记本。
警告
如果将 perform_restart 设置为 True,脚本将自动重启符合条件的计算,这可能会导致活动作业失败并重置打开的笔记本。 为了降低中断工作区的业务关键型作业的风险,请计划一个计划性维护时段,并确保通知工作区用户。
确定并选择性地重启长时间运行的计算
针对作业和 JDBC/ODBC 查询进行的计算自动启动
当计划运行分配给已终止的计算的作业时,或者从 JDBC/ODBC 接口连接到已终止的计算时,该计算将自动重启。 请参阅配置作业的计算和 JDBC 连接。
通过计算自动启动,你可以将计算配置为自动终止,而无需手动干预来为计划的作业重启计算。 此外,还可以通过计划作业在已终止的计算上运行来计划计算初始化。
注意
如果计算是在 Azure Databricks 平台版本 2.70 或更早版本中创建的,则不会自动启动:计划在已终止的计算上运行的作业将会失败。
在 Apache Spark UI 中查看计算信息
可以通过选择计算详细信息页上的“Spark UI”选项卡查看有关 Spark 作业的详细信息。
如果重启已终止的计算,Spark UI 将显示已重启的计算的信息,而不会显示已终止的计算的历史信息。
请参阅使用 Spark UI 诊断成本和性能问题,来逐步了解如何使用 Spark UI 诊断成本和性能问题。
查看计算日志
Azure Databricks 提供以下三种与计算相关的活动日志记录:
- 计算事件日志,可捕获计算生命周期事件,如创建、终止和配置编辑。
- Apache Spark 驱动程序和工作器日志,可用于调试。
- 计算 init 脚本日志,这对于调试 init 脚本非常有用。
本部分讨论计算事件日志、驱动程序和辅助角色日志。 有关 init 脚本日志的详细信息,请参阅 Init 脚本日志记录。
计算事件日志
计算事件日志显示由用户操作手动触发或 Azure Databricks 自动触发的重要计算生命周期事件。 此类事件影响计算的整个操作以及计算中运行的作业。
有关受支持的事件类型,请参阅群集 API 数据结构。
事件的存储时间为 60 天,相当于 Azure Databricks 中的其他数据保留时间。
查看计算的事件日志
若要查看计算的事件日志,请在计算详细信息页上选择“事件日志”选项卡。
有关事件的详细信息,请在日志中单击其所在行,然后单击“JSON”选项卡以查看详细信息。
计算驱动程序和辅助角色日志
笔记本、作业和库中的直接打印和日志语句会转到 Spark 驱动程序日志。 可以从计算详细信息页上的“驱动程序日志”选项卡访问这些日志文件。 单击日志文件名称即可下载。
这些日志包含三个输出:
- 标准输出
- 标准错误
- Log4j 日志
若要查看 Spark 辅助角色日志,可以使用“Spark UI”选项卡。还可以为计算配置日志传递位置。 辅助角色和计算日志均传递到指定位置。
监视性能
为了帮助你监视 Azure Databricks 计算的性能,Azure Databricks 提供了从计算详细信息页访问指标的权限。 对于 Databricks Runtime 12.2 及更低版本,Azure Databricks 提供对 Ganglia 指标的访问权限。 对于 Databricks Runtime 13.3 LTS 及更高版本,计算指标由 Azure Databricks 提供。
此外,你还可以配置 Azure Databricks 计算,以将指标发送到 Azure Monitor(Azure 的监视平台)中的 Log Analytics 工作区。
还可以在计算节点上安装 Datadog 代理,以将 Datadog 指标发送到 Datadog 帐户。
计算指标
计算指标是用于非无服务器通用和作业计算的默认监视工具。 若要访问计算指标 UI,请导航到计算详细信息页上的“指标”选项卡。
可以通过使用日期选取器筛选器选择时间范围来查看历史指标。 每分钟收集一次指标。 还可以通过单击“刷新”按钮获取最新指标。 有关详细信息,请参阅查看计算指标。
Ganglia 指标
注意
Ganglia 指标仅适用于 Databricks Runtime 12.2 及更低版本。
若要访问 Ganglia UI,请导航到计算详细信息页上的“指标”选项卡,并启用“旧指标”设置。 GPU 指标适用于已启用 GPU 的计算。
若要查看实时指标,请单击“Ganglia UI”链接。
若要查看历史指标,请单击快照文件。 快照包含所选时间前一小时的聚合指标。
注意
Docker 容器不支持 Ganglia。 如果你在计算中使用 Docker 容器,则不会提供 Ganglia 指标。
配置 Ganglia 指标收集
默认情况下,Azure Databricks 每 15 分钟收集一次 Ganglia 指标。 若要配置集合时间,请使用 init 脚本或在创建群集 API 的 spark_env_vars 字段中设置 DATABRICKS_GANGLIA_SNAPSHOT_PERIOD_MINUTES 环境变量。
Azure Monitor
可以配置 Azure Databricks 计算,以将指标发送到 Azure Monitor(Azure 的监视平台)中的 Log Analytics 工作区。 有关完整说明,请参阅监视 Azure Databricks。
注意
如果你已在自己的虚拟网络中部署了 Azure Databricks 工作区,并且已将网络安全组 (NSG) 配置为拒绝 Azure Databricks 不需要的所有出站流量,则必须为“AzureMonitor”服务标记配置其他出站规则。
笔记本示例:Datadog 指标
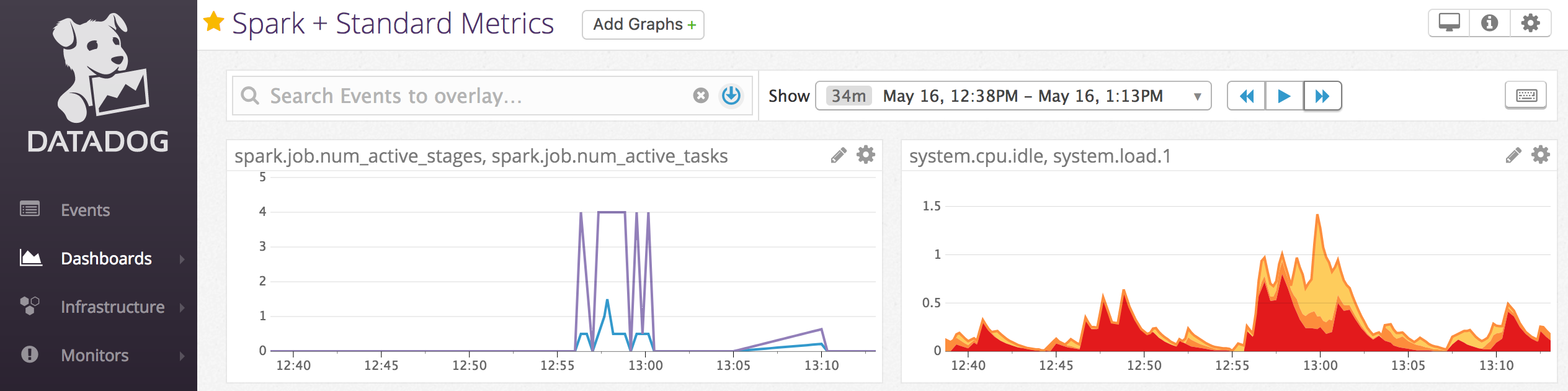
可以在计算节点上安装 Datadog 代理,以将 Datadog 指标发送到 Datadog 帐户。 以下笔记本演示了如何使用计算范围 init 脚本在计算上安装 Datadog 代理。
若要在所有计算上安装 Datadog 代理,请使用计算策略管理计算范围的 init 脚本。