Azure Monitor 从系统收集并聚合指标和日志,以监视可用性、性能和复原能力,并通知你影响系统的问题。 可以使用 Azure 门户、PowerShell、Azure CLI、REST API 或客户端库来设置和查看监视数据。
不同的指标和日志可用于不同的资源类型。 本文介绍可为此服务收集的监视数据类型以及分析这些数据的方法。
使用 Azure Monitor 收集数据
下表介绍了如何收集数据来监视服务,以及收集到的数据可以做些什么:
| 要收集的数据 | 说明 | 如何收集和路由数据 | 查看数据的位置 | 支持的数据 |
|---|---|---|---|---|
| 指标数据 | 指标是数字值,用于描述系统某个方面在特定时间点的情况。 可以使用算法来聚合指标、将其与其他指标进行比较,以及通过分析指标来了解一段时间内的趋势。 | - 定期自动收集。 - 可以将某些平台指标路由到 Log Analytics 工作区,以使用其他数据进行查询。 检查每个指标的“DS 导出”设置,查看是否可以使用诊断设置来路由指标数据。 |
指标资源管理器 | Azure Monitor 支持的 Azure 数据资源管理器指标 |
| 资源日志数据 | 日志是记录的具有时间戳的系统事件。 日志可包含不同类型的数据,可以结构化或采用自由文本格式。 可以将资源日志数据路由到 Log Analytics 工作区进行查询和分析。 | 创建诊断设置以收集和路由资源日志数据。 | Log Analytics | Azure Monitor 支持的 Azure 数据资源管理器资源日志数据 |
| 活动日志数据 | Azure Monitor 活动日志提供关于订阅级事件的见解。 活动日志包括何时修改了资源或何时启动了虚拟机等信息。 | - 自动收集。 - 免费为 Log Analytics 工作区创建诊断设置。 |
活动日志 |
有关 Azure Monitor 支持的所有数据的列表,请参阅:
Azure 数据资源管理器的内置监视
Azure 数据资源管理器提供用于监视服务的指标和日志。
通过指标监视 Azure 数据资源管理器的性能、运行状况和使用情况
Azure 数据资源管理器指标提供关于 Azure 数据资源管理器群集资源运行状况和性能的关键指标。 可以将指标作为独立指标,用来监视特定方案中 Azure 数据资源管理器群集的使用情况、运行状况和性能。 还可以将指标用作正常运行的 Azure 仪表板和 Azure 警报的基础。
要使用指标来监视 Azure 门户中的 Azure 数据资源管理器资源,请执行以下操作:
- 登录到 Azure 门户。
- 在 Azure 数据资源管理器群集的左窗格中,搜索“指标”。
- 选择“指标”,以打开指标窗格,然后开始对群集进行分析。
在指标窗格中,选择要跟踪的特定指标,选择聚合数据的方式,并创建要在仪表板上查看的指标图表。
系统为 Azure 数据资源管理器群集预先选择了“资源”和“指标命名空间”选取器。 下图中的数字对应编号列表。 这些内容可以指导你掌握在设置和查看指标时使用的不同选项。
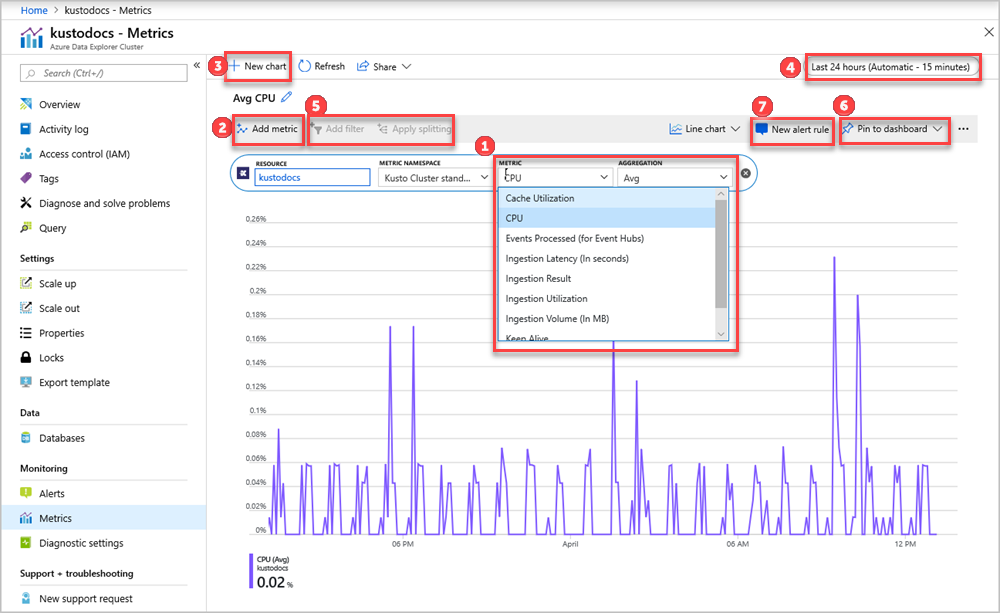
- 若要创建指标图表,请选择指标名称和每个指标的相关聚合。 有关不同指标的详细信息,请参阅支持的 Azure 数据资源管理器指标。
- 选择“添加指标”可以查看在同一图表中绘制的多个指标。
- 选择“+ 新建图表”可在一个视图中查看多个图表。
- 使用时间选取器更改时间范围(默认:过去 24 小时)。
- 对包含维度的指标使用添加筛选器和应用拆分。
- 选择“固定到仪表板”可将图表配置添加到仪表板,以便可以再次查看它。
- 设置新的警报规则可以使用设置的条件将指标可视化。 新的警报规则包括图表的目标资源、指标、拆分和筛选器维度。 在警报规则创建窗格中修改这些设置。
使用诊断日志监视 Azure 数据资源管理器的引入、命令、查询和表
Azure 数据资源管理器是一项快速、完全托管的数据分析服务,用于实时分析从应用程序、网站和 IoT 设备等资源流式传输的海量数据。 Azure Monitor 诊断日志提供有关 Azure 资源操作的数据。 Azure 数据资源管理器使用诊断日志获取有关引入、命令、查询和表的见解。 可将操作日志导出到 Azure 存储、事件中心或 Log Analytics 以监视引入、命令和查询状态。 来自 Azure 存储和 Azure 事件中心的日志可以路由到 Azure 数据资源管理器群集中的表,供进一步分析。
重要
诊断日志数据可能包含敏感数据。 请根据监视需求限制日志目标的权限。
注意
在 Azure 门户中,“指标”和“见解”页面的原始指标数据存储在 Azure Monitor 中。 这些页面上的查询会直接查询原始指标数据,以提供最准确的结果。 使用诊断设置功能时,可以将原始指标数据迁移到 Log Analytics 工作区。 在迁移过程中,可能会因为四舍五入而丢失部分数据精度;因此,查询结果可能与原始数据略有不同。 误差幅度小于百分之一。
诊断日志可用于配置以下日志数据的收集:
注意
- 使用 Kusto 客户端库和数据连接器排队引入到数据引入 URI 时,支持引入日志。
- 对于流式引入、目标为 群集 URI 的直接引入、从查询进行的引入或者
.set-or-append命令,引入日志不受支持。
注意
只会针对引入操作的最终状态报告“失败引入”日志,这与引入结果指标不同,后者是针对在内部重试的暂时性故障发出的。
- 成功的引入操作:这些日志包含有关已成功完成的引入操作的信息。
- 失败的引入操作:这些日志包含有关失败的引入操作的详细信息,包括错误详细信息。
- 引入批处理操作:这些日志包含准备引入的批的详细统计信息(持续时间、批大小、blob 计数和批处理类型)。
可以选择将日志数据发送到 Log Analytics 工作区、存储帐户,或将其流式传输到事件中心。
诊断日志默认已禁用。 使用以下步骤为群集启用诊断日志:
在 Azure 门户中,选择要监视的群集资源。
在“监视”下,选择“诊断设置” 。
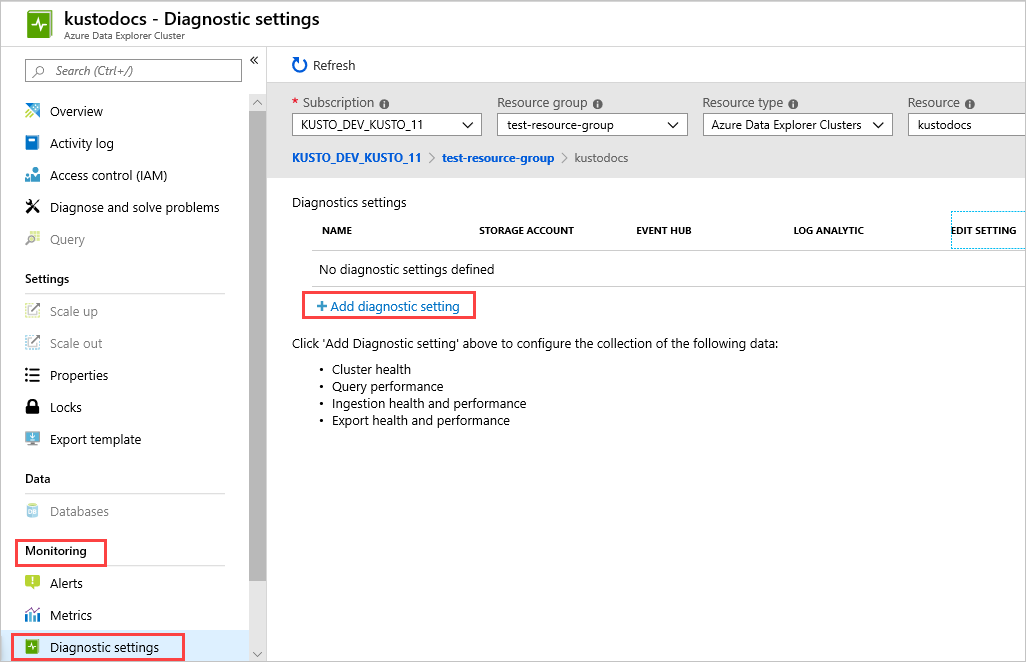
选择“添加诊断设置”。
在“诊断设置”窗口中,执行以下操作:
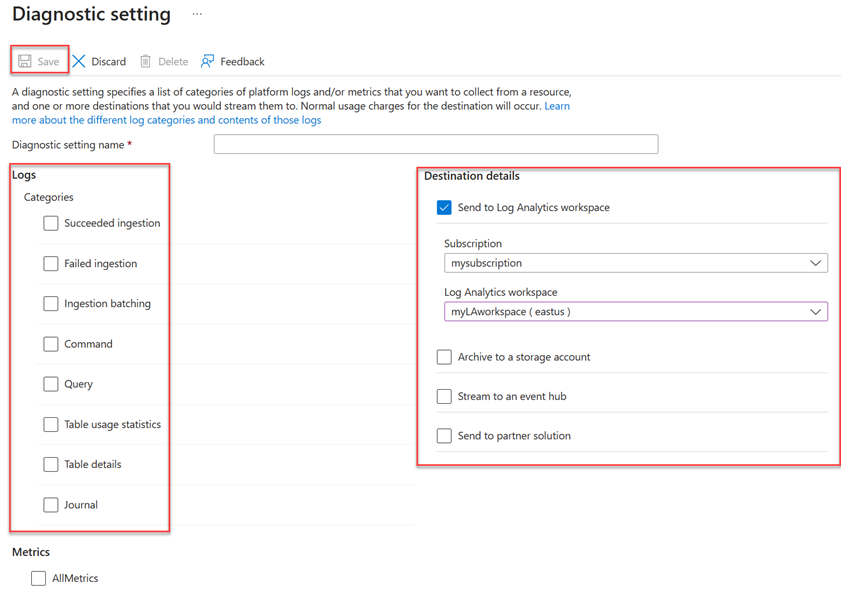
- 输入一个诊断设置名称。
- 选择一个或多个目标:Log Analytics 工作区、存储帐户或事件中心。
- 选择要收集的日志:成功的引入、失败的引入、引入批处理、命令、查询、表使用情况统计信息、表详细信息或日记。
- 选择要收集的指标(可选)。
- 选择“保存”以保存新的诊断日志设置和指标。
设置准备就绪后,日志开始显示在配置的目标中:存储帐户、事件中心或 Log Analytics 工作区。
注意
如果将日志发送到 Log Analytics 工作区,则 SucceededIngestion、FailedIngestion、IngestionBatching、Command、Query、TableUsageStatistics、TableDetails 和 Journal 日志会分别存储在名为 SucceededIngestion、FailedIngestion、ADXIngestionBatching、ADXCommand、ADXQuery、ADXTableUsageStatistics、ADXTableDetails 和 ADXJournal 的 Log Analytics 表中。
使用 Azure Monitor 工具分析数据
Azure 门户中提供了以下 Azure Monitor 工具,可帮助你分析监视数据:
某些 Azure 服务在 Azure 门户中具有内置的监视仪表板。 这些仪表板称为“见解”,可以在 Azure 门户的 Azure Monitor 的“见解”部分找到它们。
指标资源管理器可用于查看和分析 Azure 资源的指标。 有关详细信息,请参阅使用 Azure Monitor 指标资源管理器分析指标。
Log Analytics 支持使用 Kusto 查询语言 (KQL) 来查询和分析日志数据。 有关详细信息,请参阅 Azure Monitor 日志查询入门。
Azure 门户具有用于执行活动日志查看和基本搜索的用户界面。 要进行更深入的分析,请将数据路由到 Azure Monitor 日志,并在 Log Analytics 中运行更复杂的查询。
Application Insights 监视 Web 应用程序的可用性、性能和使用情况,因此你可以确定并诊断错误,而无需等待用户报告这些错误。
Application Insights 包含各种开发工具的连接点,并与 Visual Studio 集成以支持 DevOps 过程。 有关详细信息,请参阅应用服务的应用程序监视。
支持更复杂可视化效果的工具包括:
- 仪表板,它支持将不同类型的数据合并到 Azure 门户的单个窗格中。
- 工作簿,它们是可在 Azure 门户中创建的可自定义报表。 工作簿可以包括文本、指标和日志查询。
- Grafana,它是一个适用于操作仪表板的开放平台工具。 可以使用 Grafana 创建包含来自除 Azure Monitor 以外多个源的数据的仪表板。
- Power BI,它是一项业务分析服务,可提供跨各种数据源的交互式可视化效果。 可将 Power BI 配置为自动从 Azure Monitor 导入日志数据,以利用这些可视化效果。
导出 Azure Monitor 数据
可以使用以下方法将数据从 Azure Monitor 导出到其他工具:
指标:使用适用于指标的 REST API 从 Azure Monitor 指标数据库提取指标数据。 有关详细信息,请参阅 Azure Monitor REST API 参考。
日志:使用 REST API 或关联的客户端库。
要开始使用 Azure Monitor REST API,请参阅 Azure 监视 REST API 演练。
使用 Kusto 查询分析日志数据
可以使用 Kusto 查询语言 (KQL) 分析 Azure Monitor 日志数据。 有关详细信息,请参阅 Azure Monitor 中的日志查询。
使用 Azure Monitor 警报通知问题
Azure Monitor 警报允许你识别和解决系统中的问题,并在监视数据中观察到特定情况时在客户注意到之前主动通知你。 可以针对 Azure Monitor 数据平台中的任何指标或日志数据源发出警报。 有不同类型的 Azure Monitor 警报,具体取决于要监视的服务以及要收集的监视数据。 请参阅选择正确的警报规则类型。
有关 Azure 资源常见警报的示例,请参阅示例日志警报查询。
大规模实现警报
对于某些服务,你可以通过将相同的指标警报规则应用于同一 Azure 区域中的多个相同类型资源,进行大规模的监视。 Azure Monitor 基线警报 (AMBA) 提供了大规模实现重要平台指标警报、仪表板和指南的半自动化方法。
使用 Azure 顾问获取个性化建议
对于某些服务,如果在资源操作期间出现严重情况或即将发生变化,则门户中的服务“概述”页面上会显示一个警报。 可以在左侧菜单“监视”下的“顾问建议”中找到警报的详细信息和建议补丁。 在正常操作期间,不会显示任何顾问建议。
有关 Azure 顾问的详细信息,请参阅 Azure 顾问概述。