Azure Cosmos DB 中的 API for Cassandra 已成为在 Apache Cassandra 上运行的企业工作负载的极佳选择,原因各种各样,例如:
无管理和监视开销: 它不需管理和监视跨 OS、JVM 和 yaml 文件的大量设置,也不需进行交互。
显著节省成本:使用 Azure Cosmos DB 可以节省成本,其中包括 VM、带宽以及任何适用许可证的成本。 另外,你无需管理数据中心、服务器、SSD 存储、网络以及电力成本。
能够使用现有的代码和工具: Azure Cosmos DB 提供的线路协议级别与现有 Cassandra SDK 和工具兼容。 此兼容性确保只需经过细微的更改,就可以将现有代码库用于 Azure Cosmos DB for Apache Cassandra。
Azure Cosmos DB 不支持用于复制的原生 Apache Cassandra gossip 协议。 因此,如果迁移要求零停机时间,则需要采用不同的方法。 本教程介绍如何使用双重写入代理和 Apache Spark 将数据从原生 Apache Cassandra 群集实时迁移到 Azure Cosmos DB for Apache Cassandra。
下图演示了该模式。 双重写入代理用于捕获实时更改,而历史数据是使用 Apache Spark 批量复制的。 只需进行少量的配置更改甚至不进行任何配置更改,代理就能接受来自应用程序代码的连接。 它会将所有请求路由到源数据库,并在进行批量复制时将写入异步路由到 API for Cassandra。

先决条件
确保源群集与目标 API for Cassandra 终结点之间已建立网络连接。
确保已将密钥空间/表方案从源 Cassandra 数据库迁移到目标 API for Cassandra 帐户。
重要
在迁移过程中,如果需要保留 Apache Cassandra
writetime,则必须在创建表时设置以下标志:with cosmosdb_cell_level_timestamp=true and cosmosdb_cell_level_timestamp_tombstones=true and cosmosdb_cell_level_timetolive=true例如:
CREATE KEYSPACE IF NOT EXISTS migrationkeyspace WITH REPLICATION= {'class': 'org.apache.> cassandra.locator.SimpleStrategy', 'replication_factor' : '1'};CREATE TABLE IF NOT EXISTS migrationkeyspace.users ( name text, userID int, address text, phone int, PRIMARY KEY ((name), userID)) with cosmosdb_cell_level_timestamp=true and > cosmosdb_cell_level_timestamp_tombstones=true and cosmosdb_cell_level_timetolive=true;
预配 Spark 群集
建议使用 Azure Databricks。 使用支持 Spark 3.0 或更高版本的运行时。
重要
你需要确保 Azure Databricks 帐户与源 Apache Cassandra 群集之间已建立网络连接。 这可能需要 VNet 注入。 有关详细信息,请参阅此处。
添加 Spark 依赖项
你需要将 Apache Spark Cassandra 连接器库添加到群集,以便连接到原生终结点和 Azure Cosmos DB Cassandra 终结点。 在群集中,选择“库”>“安装新库”>“Maven”,然后在 Maven 坐标中添加 com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 。
重要
如果需要在迁移期间保留每一行的 Apache Cassandra writetime,建议使用此示例。 此示例中的依赖项 jar 还包含 Spark 连接器,因此应安装此连接器,而不是上述连接器程序集。 如果要在历史数据加载完成后在源和目标之间执行行比较验证,此示例也很有用。 有关更多详细信息,请参阅下面的“运行历史数据加载”和“验证源和目标”部分。
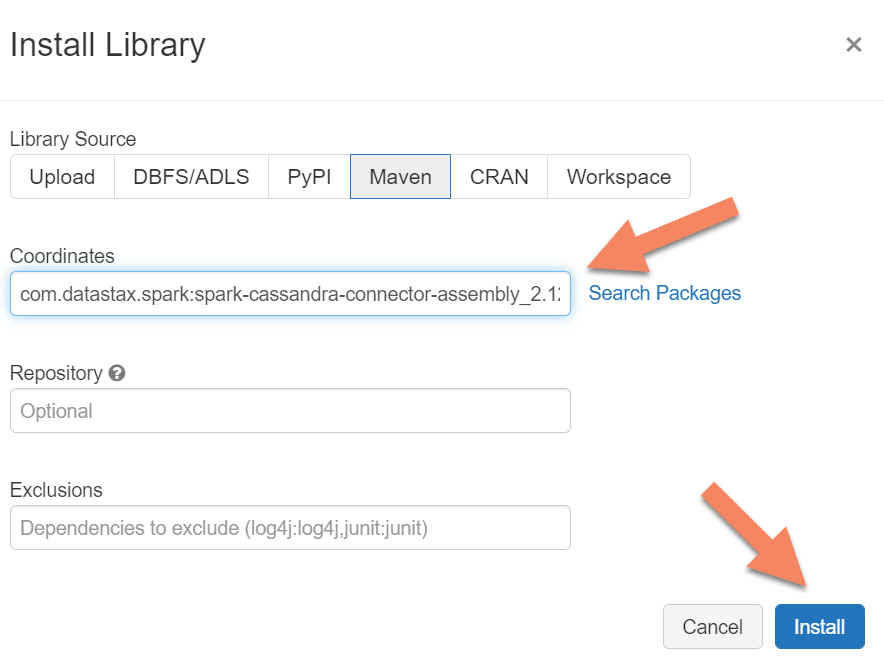
选择“安装”,然后在安装完成后重启群集。
注意
安装 Cassandra 连接器库后,请务必重启 Azure Databricks 群集。
安装双重写入代理
为了在双重写入期间获得最佳性能,我们建议在源 Cassandra 群集中的所有节点上安装该代理。
#assuming you do not have git already installed
sudo apt-get install git
#assuming you do not have maven already installed
sudo apt install maven
#clone repo for dual-write proxy
git clone https://github.com/Azure-Samples/cassandra-proxy.git
#change directory
cd cassandra-proxy
#compile the proxy
mvn package
启动双重写入代理
建议在源 Cassandra 群集中的所有节点上安装该代理。 至少,请运行以下命令在每个节点上启动代理。 请将 <target-server> 替换为目标群集中某个节点上的 IP 地址或服务器地址。 请将 <path to JKS file> 替换为本地 jks 文件的路径,将 <keystore password> 替换为相应的密码。
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password>
以这种方式启动代理的前提是满足以下条件:
- 源和目标终结点具有相同的用户名和密码。
- 源和目标终结点实现安全套接字层 (SSL)。
如果源和目标终结点无法满足这些条件,请继续阅读以了解其他配置选项。
配置 SSL
对于 SSL,可以实现现有的密钥存储(例如源群集使用的密钥存储),或者可以使用 keytool 创建自签名证书:
keytool -genkey -keyalg RSA -alias selfsigned -keystore keystore.jks -storepass password -validity 360 -keysize 2048
如果源或目标终结点不实现 SSL,则你还可为其禁用 SSL。 使用 --disable-source-tls 或 --disable-target-tls 标志:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --source-port 9042 --target-port 10350 --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password> --disable-source-tls true --disable-target-tls true
注意
通过代理与数据库建立 SSL 连接时,请确保客户端应用程序使用的密钥存储和密码与双重写入代理所用的密钥存储和密码相同。
配置凭据和端口
默认情况下将从客户端应用传递源凭据。 代理将使用这些凭据来与源和目标群集建立连接。 如前所述,此过程假设源和目标凭据相同。 启动代理时,需要为目标 API for Cassandra 终结点单独指定不同的用户名和密码:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password>
默认的源和目标端口将是 9042(如果未指定)。 在本例中,API for Cassandra 在端口 10350 上运行,因此你需要使用 --source-port 或 --target-port 来指定端口号:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --source-port 9042 --target-port 10350 --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password>
远程部署代理
在某些情况下,你可能不希望在群集节点本身上安装代理,而是希望将其安装在单独的计算机上。 在这种情况下,需要指定 <source-server> 的 IP 地址:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar <source-server> <destination-server>
警告
如果在单独的计算机上远程安装和运行代理(而不是在源 Apache Cassandra 群集中的所有节点上运行),则会在执行实时迁移时影响性能。 虽然它可以正常运行,但客户端驱动程序无法与群集中的所有节点建立连接,而将依赖于单个协调器节点(安装代理的位置)来建立连接。
实现零应用程序代码更改
默认情况下,代理侦听端口 29042。 必须将应用程序代码更改为指向此端口。 但是,可以更改代理侦听的端口。 如果你想要消除应用程序级别的代码更改,可采取以下做法:
- 让源 Cassandra 服务器在其他端口上运行。
- 让代理在标准 Cassandra 端口 9042 上运行。
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --proxy-port 9042
注意
在群集节点上安装代理不需要重启节点。 但是,如果你有许多应用程序客户端,并希望代理在标准 Cassandra 端口 9042 上运行,以便无需进行任何应用程序级别的代码更改,则需要更改 Apache Cassandra 默认端口。 然后需要重启群集中的节点,并将源端口配置为你已为源 Cassandra 群集定义的新端口。
在以下示例中,我们将源 Cassandra 群集更改为在端口 3074 上运行,并在端口 9042 上启动群集:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --proxy-port 9042 --source-port 3074
强制实施协议
代理提供强制实施协议的功能。如果源终结点比目标更高级或者不受支持,可能需要强制实施协议。 在这种情况下,可以指定 --protocol-version 和 --cql-version 来强制实施协议,以便与目标相符:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --protocol-version 4 --cql-version 3.11
在运行双重写入代理后,需要更改应用程序客户端上的端口并重启。 (或者更改 Cassandra 端口并重启群集,如果已选择此方法的话。)然后,代理会开始将写入转发到目标终结点。 你可以了解代理工具中提供的监视和指标。
运行历史数据加载
若要加载数据,请在 Azure Databricks 帐户中创建一个 Scala 笔记本。 将源和目标 Cassandra 配置替换为相应的凭据,并替换源和目标密钥空间和表。 根据需要在以下示例中为每个表添加更多变量,然后运行该示例。 在应用程序开始向双重写入代理发送请求后,你便可以迁移历史数据。
重要
在迁移数据之前,请将容器吞吐量提高到快速迁移应用程序所需的量。 在开始迁移之前提高吞吐量可以缩短数据迁移时间。 为了帮助防止在历史数据加载过程中发生速率限制,建议在 API for Cassandra 中启用服务器端重试 (SSR)。 有关详细信息以及有关如何启用 SSR 的说明,请参阅此处的文章。
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val sourceCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val targetCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "10350",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "1",
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//set timestamp to ensure it is before read job starts
val timestamp: Long = System.currentTimeMillis / 1000
//Read from source Cassandra
val DFfromSourceCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(sourceCassandra)
.load
//Write to target Cassandra
DFfromSourceCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(targetCassandra)
.option("writetime", timestamp)
.mode(SaveMode.Append)
.save
注意
在以上 Scala 示例中可以看到,在读取源表中的所有数据之前 timestamp 设置为当前时间。 然后 writetime 设置为此回溯时间戳。 这可以确保通过加载历史数据而写入到目标终结点的记录,无法覆盖在读取历史数据时从双重写入代理传入的具有更迟时间戳的更新内容。
重要
如果你出于任何原因需要保留确切的时间戳,应采用可保留时间戳的历史数据迁移方法,如此示例所示。 示例中的依赖项 jar 还包含 Spark 连接器,因此无需安装前面的先决条件中提到的 Spark 连接器程序集 - 同时在 Spark 群集中安装这两个连接器会导致冲突。
验证源和目标
历史数据加载完成后,数据库应已同步并准备好进行直接转换。 但是,我们建议对源和目标执行验证,以确保在最终进行直接转换之前它们是匹配的。
注意
如果使用上面提到的 cassandra 迁移程序示例来保留 writetime,这需要通过基于特定容差比较源和目标中的行来验证迁移。