适用于:![]() Azure SQL 数据库
Azure SQL 数据库
无服务器是 Azure SQL 数据库中单一数据库的计算层级,可根据工作负荷需求自动缩放计算,并按每秒使用的计算量计费。 此外,当仅对存储计费时,无服务器计算层将在非活动期间自动暂停数据库;当活动返回时,它将自动恢复数据库。 无服务器计算层级在常规用途服务层级和超大规模服务层级均已发布。
注意
自动暂停和自动恢复目前仅在常规用途服务层级中受支持。
概述
计算自动缩放范围和自动暂停延迟是无服务器计算层级的重要参数。 这些参数的配置将组成数据库性能经验和计算成本。
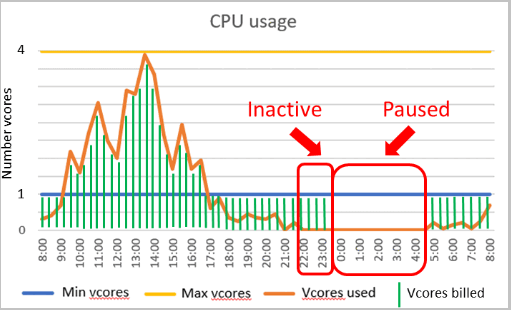
性能配置
- “最小 vCore 数”和“最大 vCore 数”是可配置的参数,用于定义数据库可用的计算容量范围。 内存和 IO 限制与指定的 vCore 范围成正比。
- 自动暂停延迟是可配置的参数,用于定义数据库在自动暂停之前必须处于非活动状态的时间段。 下次登录或发生其他活动时,数据库会自动恢复。 或者,可以禁用自动暂停。
成本
- 无服务器数据库的成本是计算成本和存储成本之和。
- 如果计算用量介于配置的下限和上限之间,则计算成本基于使用的 vCore 数和内存量。
- 如果计算用量低于配置的下限,则计算成本基于配置的最小 vCore 数和最小内存量。
- 暂停数据库后,计算成本将会归零,只会产生存储成本。
- 存储成本的确定方式与在预配计算层中相同。
有关成本的更多详细信息,请参阅计费。
方案
对于具有间歇性、不可预测的使用模式,在空闲使用时间段后的计算预热期间能够容忍一定延迟的单一数据库来说,无服务器是一种高性价比的方案。 比较而言,对于具有较高的平均使用量,并且在计算预热期间无法容忍任何延迟的弹性池内的单一数据库或多个数据库,预配计算层级是更具性价比的方案。
非常适合无服务器计算的场景
- 具有间歇性、不可预测的使用模式,中间穿插着非活动时段且一段时间内平均计算利用率较低的单一数据库。
- 预配计算层中经常重新缩放的单一数据库;客户更倾向于将计算重新缩放委托到服务。
- 不提供用量历史记录,且在 Azure SQL 数据库中部署之前难以或者无法估算计算大小的新单一数据库。
适合预配计算的场景
- 采用较有规律的可预测使用模式,且在一段时间内平均计算利用率较高的单一数据库。
- 不能容忍因较频繁的内存微调或从暂停状态下恢复的延迟,而导致需要对性能做出妥协的数据库。
- 采用间歇性、不可预测使用模式,可整合到弹性池以提高性价比优化的多个数据库。
比较计算层级
下表汇总了无服务器计算层和预配计算层之间的区别:
| 无服务器计算 | 预配计算 | |
|---|---|---|
| 数据库使用模式 | 间歇性、不可预测的使用模式,在一段时间内的平均计算利用率较低。 | 较有规律的使用模式,在一段时间内平均计算利用率较高;或者使用弹性池的多个数据库。 |
| 性能管理工作量 | 较低 | 较高 |
| 计算缩放 | 自动 | 手动 |
| 计算响应能力 | 在非活动期后较低 | 即时 |
| 计费粒度 | 每秒 | 每小时 |
购买模型和服务层级
下表描述了基于购买模型、服务层级和硬件的无服务器支持:
| 类别 | 支持 | 不支持 |
|---|---|---|
| 购买模型 | vCore | DTU |
| 服务层 | 常规用途 超大规模 |
业务关键 |
| 硬件 | 标准系列 (Gen5) | 所有其他硬件 |
自动缩放
缩放响应能力
无服务器数据库在具有足够运算能力的计算机上运行,以满足资源需求,而不会中断由最大 vCore 数值设置的限制范围内任何数量的计算请求。 有时,如果计算机无法在几分钟内满足资源需求,系统便会自动进行负载均衡。 例如,如果资源需求为 4 个 vCore,但只有 2 个 vCore 可用,则在提供 4 个 vCore 之前,可能需要几分钟时间进行负载均衡。 在负载均衡过程中,除了在连接丢失,操作结束时的一小段时间内,数据库将保持联机状态。
内存管理
在常规用途和超大规模服务层级中,无服务器数据库的内存回收比预配计算数据库的内存回收更加频繁。 这种行为对于在无服务器条件下控制成本非常重要,并可能会影响性能。
缓存回收
与预配的计算数据库不同,当 CPU 或活动缓存使用率较低时,从无服务器数据库回收 SQL 缓存中的内存。
- 当最近使用的缓存条目的总大小低于某个时间段的阈值时,将认为活动缓存利用率低。
- 触发缓存回收后,目标缓存大小将递减到以前大小的一部分,并且仅当使用率保持较低时才继续回收。
- 发生缓存回收时,用于选择要逐出的缓存条目的策略与当内存压力较高时适用于预配计算数据库的策略相同。
- 缓存大小永远不会减至小于最小 vCore 数定义的最小内存限制。
在无服务器数据库和预配的计算数据库中,如果使用了所有可用内存,则可能会逐出缓存条目。
在 CPU 利用率较低时,主动缓存利用率可能会保持较高水平(具体取决于使用模式),并会阻止内存回收。 此外,用户活动停止后,在内存回收之前,可能会有其他延迟,因为后台进程会定期响应先前的用户活动。 例如,删除操作和查询存储清除任务会生成标记为待删除的虚影记录,但该记录不会被物理删除,直至虚影清除进程运行为止。 虚影清除可能涉及将数据页读入缓存。
缓存合成
随着从磁盘中不断提取数据,SQL 内存缓存也会不断增大,其增长速度与预配数据库相同。 当数据库处于繁忙状态时,允许缓存在有可用内存的情况下无约束增大。
磁盘缓存管理
在无服务器和预配计算层级的超大规模服务层级中,每个计算副本都使用可复原缓冲池扩展 (RBPEX) 缓存,该缓存将数据页存储在本地 SSD 上以提高 IO 性能。 但是,在超大规模的无服务器计算层级中,每个计算副本的 RBPEX 缓存会自动增长和收缩,以响应工作负荷需求的增加和减少。 RBPEX 缓存可以增长到的最大大小是为数据库配置的最大内存的三倍。 有关无服务器中最大内存和 RBPEX 自动缩放限制的详细信息,请参阅无服务器超大规模资源限制。
自动暂停和自动恢复
目前,无服务器自动暂停和自动恢复仅在常规用途层级中受支持。
自动暂停
如果在自动暂停延迟的时间段内,下面的所有条件均成立,则会触发自动暂停:
- 会话数 = 0
- CPU = 0(对于在用户资源池中运行的用户工作负荷)
如有需要,系统也提供了禁用自动暂停的选项。
以下功能不支持自动暂停,但支持自动缩放。 如果使用了以下任意功能,那么无论数据库处于不活动状态的时间有多长,都必须禁用自动暂停,让数据库保持联机状态:
- 异地复制(活动异地复制和故障转移组)。
- 长期备份保留 (LTR)。
- SQL 数据同步中使用的同步数据库。与同步数据库不同,中心数据库和成员数据库支持自动暂停。
- 为包含无服务器数据库的逻辑服务器创建的 DNS 别名。
- 弹性作业,不支持已启用自动暂停的无服务器数据库作为作业数据库。 弹性作业用作目标的无服务器数据库支持自动暂停。 作业连接将恢复数据库。
在部署某些需要数据库联机的服务更新期间,会暂时阻止自动暂停。 在这种情况下,一旦服务更新完成,就会再次允许自动暂停。
自动暂停故障排除
如果启用了自动暂停并且未使用会阻止自动暂停的功能,但数据库在延迟期结束后未自动暂停,则可能是应用程序或用户会话在阻止自动暂停。
若要查看当前是否有任何应用程序或用户会话连接到数据库,请使用任何客户端工具连接到数据库,然后执行以下查询:
SELECT session_id,
host_name,
program_name,
client_interface_name,
login_name,
status,
login_time,
last_request_start_time,
last_request_end_time
FROM sys.dm_exec_sessions AS s
INNER JOIN sys.dm_resource_governor_workload_groups AS wg
ON s.group_id = wg.group_id
WHERE s.session_id <> @@SPID
AND
(
(
wg.name like 'UserPrimaryGroup.DB%'
AND
TRY_CAST(RIGHT(wg.name, LEN(wg.name) - LEN('UserPrimaryGroup.DB') - 2) AS int) = DB_ID()
)
OR
wg.name = 'DACGroup'
);
提示
在运行查询后,请确保断开与数据库的连接。 否则,查询所使用的已打开会话会阻止自动暂停。
- 如果结果集不为空,则表示当前有会话阻止自动暂停。
- 如果结果集为空,则会话仍有可能已在自动暂停延迟期间较早的某个时间点暂时打开。 要检查延迟期间是否发生了此类活动,可以使用 Azure SQL 数据库和 Azure Synapse Analytics 的审核并检查相关时间段内的审核数据。
重要
无服务器数据库无法按预期自动暂停的最常见原因是,无论有无并发 CPU 利用率,用户资源池中都存在打开的会话。
自动恢复
如果在任何时候,下面的任意条件成立,均会触发自动恢复:
| 功能 | 自动恢复触发器 |
|---|---|
| 身份验证和授权 | 登录 |
| 威胁检测 | 启用/禁用数据库或服务器级别的威胁检测设置。 修改数据库或服务器级别的威胁检测设置。 |
| 数据发现和分类 | 添加、修改、删除或查看敏感度标签 |
| 审核 | 查看审核记录。 更新或查看审核策略。 |
| 数据屏蔽 | 添加、修改、删除或查看数据屏蔽规则 |
| 透明数据加密 | 查看透明数据加密的状况或状态 |
| 漏洞评估 | 如果启用,则为临时扫描和定期扫描 |
| 查询(性能)数据存储 | 修改或查看查询存储设置 |
| 性能建议 | 查看或应用性能建议 |
| 自动优化 | 自动优化建议的应用和验证,例如自动索引 |
| 数据库复制 | 创建数据库作为副本。 导出到 BACPAC 文件。 |
| SQL 数据同步 | 按照可配置的时间表或手动执行中心和成员数据库之间的同步 |
| 修改特定的数据库元数据 | 添加新的数据库标记。 更改最大 vCore 数、最小 vCore 数或自动暂停延迟。 |
| SQL Server Management Studio (SSMS) | 使用早于 18.1 的 SSMS 版本并为服务器中的任何数据库打开新的查询窗口时,同一服务器中任何自动暂停的数据库都将恢复。 如果使用 SSMS 版本 18.1 或更高版本,则不会发生此行为。 |
监控解决方案、管理解决方案或其他执行任何这些操作的解决方案将触发自动恢复。 在部署某些需要数据库联机的服务更新期间,也会触发自动恢复。
连接
如果无服务器数据库处于暂停状态,则第一次连接尝试将恢复数据库,并返回一个错误,指出数据库将不可用,错误代码为 40613。 恢复数据库后,可以重新尝试登录来建立连接。 遵循连接重试逻辑建议的数据库客户端应该不需要进行修改。 有关连接重试逻辑选项和建议,请参阅:
- SqlClient 中的连接重试逻辑
- SQL 数据库中使用 Entity Framework Core 的连接重试逻辑
- SQL 数据库中使用 Entity Framework 6 的连接重试逻辑
- SQL 数据库中使用 ADO.NET 的连接重试逻辑
延迟
自动恢复和自动暂停无服务器数据库的延迟通常为 1 分钟自动恢复,延迟期到期后 1-10 分钟自动暂停。
客户托管透明数据加密 (BYOK)
密钥删除或吊销
如果使用客户托管的透明数据加密 (BYOK),并且在发生密钥删除或吊销时自动暂停了无服务器数据库,则该数据库将保持自动暂停状态。 在这种情况下,在下次恢复数据库后,大约 10 分钟内数据库将无法访问。 该数据库变为不可访问后,恢复过程将与预配的计算数据库相同。 如果在发生密钥删除或吊销时无服务器数据库处于联机状态,则该数据库也将在大约 10 分钟内变得不可访问,其方式与预配的计算数据库相同。
密钥轮换
如果使用客户管理的透明数据加密 (BYOK),并启用了无服务器自动暂停,则每次轮换密钥时,数据库都会自动恢复。 满足自动暂停条件后,数据库就会自动暂停。
创建新的无服务器数据库
创建新的数据库,或将现有数据库移动到无服务器计算层中的模式与在预配计算层中创建新的数据库相同,均包含以下两个步骤:
指定服务目标。 服务目标规定了服务层级、硬件配置和最大 vCore 数。 有关服务目标选项,请参阅无服务器资源限制
(可选)指定最小 vCore 数和自动暂停延迟以更改它们的默认值。 下表显示了这些参数可用的值。
参数 可选的值 默认值 最小 vCore 数 取决于配置的最大 vCore 数 - 请参阅资源限制。 0.5 个 vCore 自动暂停延迟 最小值:15 分钟
最大值:604800 分钟(七天)
增量:1 分钟
禁用自动暂停:-160 分钟
以下示例在无服务器计算层中创建新数据库。
使用 Azure 门户
请参阅快速入门:使用 Azure 门户在 Azure SQL 数据库中创建单一数据库。
使用 PowerShell
使用以下 PowerShell 示例创建新的无服务器常规用途数据库:
New-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 0.5 -MaxVcore 2 -AutoPauseDelayInMinutes 720
使用 Azure CLI
使用以下 Azure CLI 示例创建新的无服务器常规用途数据库:
az sql db create -g $resourceGroupName -s $serverName -n $databaseName `
-e GeneralPurpose --compute-model Serverless -f Gen5 `
--min-capacity 0.5 -c 2 --auto-pause-delay 720
使用 Transact-SQL (T-SQL)
使用 T-SQL 创建新的无服务器数据库时,将针对最小 vCore 和自动暂停延迟应用默认值。 之后,可以从 Azure 门户或通过 PowerShell、Azure CLI 和 REST 等 API 更改其值。
有关详细信息,请参阅 CREATE DATABASE。
使用以下 T-SQL 示例创建新的常规用途无服务器数据库:
CREATE DATABASE testdb
( EDITION = 'GeneralPurpose', SERVICE_OBJECTIVE = 'GP_S_Gen5_1' ) ;
在计算层级或服务层级之间移动数据库
可以在预配的计算层级和无服务器计算层级之间移动数据库。
还可以将无服务器数据库从“常规用途”服务层级移动到“超大规模”服务层级。 有关详细信息,请查看管理超大规模数据库。
在计算层级之间移动数据库时,请在使用 PowerShell 或 Azure CLI 时,将“计算模型参数”指定为 Serverless 或 Provisioned,并在使用 T-SQL 时,将其指定为 SERVICE_OBJECTIVE。 查看 资源限制,确定相应的服务目标。
下面的示例将现有数据库从预配计算层级中移入无服务器计算层级。
使用 PowerShell
使用以下 PowerShell 示例将预配计算常规用途数据库移动到无服务器计算层级:
Set-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 1 -MaxVcore 4 -AutoPauseDelayInMinutes 1440
使用 Azure CLI
使用以下 Azure CLI 示例将预配计算常规用途数据库移动到无服务器计算层级:
az sql db update -g $resourceGroupName -s $serverName -n $databaseName `
--edition GeneralPurpose --compute-model Serverless --family Gen5 `
--min-capacity 1 --capacity 4 --auto-pause-delay 1440
使用 Transact-SQL (T-SQL)
使用 T-SQL 在计算层级之间移动数据库时,将针对最小 vCore 和自动暂停延迟应用默认值。 随后,可以从 Azure 门户或通过 PowerShell、Azure CLI 和 REST 等 API 更改其值。 有关详细信息,请参阅 ALTER DATABASE。
使用以下 T-SQL 示例将预配计算常规用途数据库移动到无服务器计算层级:
ALTER DATABASE testdb
MODIFY ( SERVICE_OBJECTIVE = 'GP_S_Gen5_1') ;
修改无服务器配置
使用 PowerShell
使用 Set-AzSqlDatabase 修改最大或最小 vCore 数和自动暂停延迟。 使用 MaxVcore、MinVcore 和 AutoPauseDelayInMinutes 参数。 超大规模层级当前不支持无服务器自动暂停,因此自动暂停延迟参数仅适用于常规用途层级。
使用 Azure CLI
使用 az sql db update 修改最大或最小 vCore 数和自动暂停延迟。 使用 capacity、min-capacity 和 auto-pause-delay 参数。 超大规模层级当前不支持无服务器自动暂停,因此自动暂停延迟参数仅适用于常规用途层级。
监视器
已使用和计费的资源
无服务器数据库的资源包括应用包、SQL 实例和用户资源池实体。
应用包
应用包是数据库最外层的资源管理边界,无论数据库位于无服务器计算层还是预配计算层中。 应用包包含 SQL 实例,此外还包含全文搜索之类的外部服务,这二者共同限定了所有用户以及 SQL 数据库中数据库使用的系统资源的范围。 SQL 实例通常决定整个应用包的整体资源利用率。
用户资源池
用户资源池是数据库内层的资源管理边界,无论数据库位于无服务器计算层中还是预配的计算层中。 用户资源池限定由 DDL(CREATE 和 ALTER)和 DML(INSERT、UPDATE、DELETE、MERGE 和 SELECT)查询生成的用户工作负荷的 CPU 和 IO 的范围。 这些查询通常表示应用包中最重要的使用率比例。
指标
下表列出了用于监视无服务器数据库(包括任何异地副本)的应用包和用户资源池的资源使用情况指标:
| 实体 | 指标 | 说明 | Units |
|---|---|---|---|
| 应用包 | app_cpu_percent | 应用使用的 vCore 数相对于应用允许的最大 vCore 数的百分比。 对于无服务器超大规模,此指标针对所有主要副本、命名副本和异地副本公开。 | 百分比 |
| 应用包 | app_cpu_billed | 报告期内收取的应用计算费用。 在此期间支付的金额是此指标和 vCore 单位价格的乘积。 此指标的值是通过将每秒使用的最大 CPU 和内存使用量汇总来得到的。 如果使用的量小于按照最小 vCore 数和最小内存量预配的最小量,则按照预配的最小量进行计费。 为了比较 CPU 与内存以进行计费,可通过将内存量 (GB) 按照每个 vCore 3 GB 进行重新缩放,将内存归一化为以 vCore 数为单位。 对于无服务器超大规模,此指标针对主要副本和任何命名副本公开。 |
vCore 秒 |
| 应用包 | app_memory_percent | 应用使用的内存相对于应用允许的最大内存的百分比。 对于无服务器超大规模,此指标针对所有主要副本、命名副本和异地副本公开。 | 百分比 |
| 用户资源池 | cpu_percent | 用户工作负荷使用的 vCore 数相对于用户工作负荷允许的最大 vCore 数的百分比。 | 百分比 |
| 用户资源池 | data_IO_percent | 用户工作负荷使用的数据 IOPS 相对于用户工作负荷允许的最大数据 IOPS 的百分比。 | 百分比 |
| 用户资源池 | log_IO_percent | 用户工作负荷使用的日志 MB/s 相对于用户工作负荷允许的最大日志 MB/s 的百分比。 | 百分比 |
| 用户资源池 | workers_percent | 用户工作负荷使用的工作进程数相对于用户工作负荷允许的最大工作进程数的百分比。 | 百分比 |
| 用户资源池 | sessions_percent | 用户工作负荷使用的会话数相对于用户工作负荷允许的最大会话数的百分比。 | 百分比 |
暂停和恢复状态
对于启用了自动暂停的无服务器数据库,其报告的状态包括以下值:
| 状态 | 说明 |
|---|---|
| 联机 | 数据库处于联机状态。 |
| 正在暂停 | 数据库正在从联机状态过渡到暂停状态。 |
| 已暂停 | 数据库已暂停。 |
| 正在恢复 | 数据库正在从暂停状态过渡到联机状态。 |
使用 Azure 门户
在 Azure 门户中,数据库状态显示在数据库的概述页面和其服务器的概述页面中。 此外,在 Azure 门户中,可以在活动日志中查看无服务器数据库的暂停和恢复事件的历史记录。
使用 PowerShell
使用以下 PowerShell 示例查看当前数据库状态:
Get-AzSqlDatabase -ResourceGroupName $resourcegroupname -ServerName $servername -DatabaseName $databasename `
| Select -ExpandProperty "Status"
使用 Azure CLI
使用以下 Azure CLI 示例查看当前数据库状态:
az sql db show --name $databasename --resource-group $resourcegroupname --server $servername --query 'status' -o json
资源限制
有关资源限制的信息,请参阅无服务器计算层。
计费
对无服务器数据库计费的计算量是每秒使用的最大 CPU 和内存量。 如果所用的 CPU 和内存量分别少于为每个资源预配的最小量,则对预配量进行计费。 为了比较 CPU 与内存以进行计费,可通过将 GB 数按照每个 vCore 3 GB 进行重新缩放,将内存归一化为以 vCore 数为单位。
- 计费的资源:CPU 和内存
- 计费量:vCore 单位价格 * 最大值(最小 vCore 数、使用的 vCore 数、最小内存量 (GB) * 1/3、使用的内存量量 (GB) * 1/3)
- 计费频率:每秒
vCore 单位价格是每个 vCore 每秒的费用。
请参考 Azure SQL 数据库定价页,获取给定区域的特定单位价格。
对常规用途数据库的无服务器或超大规模主要副本或命名副本计费的计算量按以下指标公开:
- 指标:app_cpu_billed(vCore 秒)
- 定义:最大值(最小 vCore 数、使用的 vCore 数、最小内存量(GB) * 1/3、使用的内存量 * 1/3)
- 报告频率:每分钟(基于 1 分钟内聚合的每秒度量值)。
最小计算费用
如果暂停无服务器数据库,则计算费用将为零。 如果不暂停无服务器数据库,则最小计算费用不少于基于最大值(最小 vCore 数,最小内存 GB * 1/3)的 vCore 数的费用。
示例:
- 假设常规用途层级中的无服务器数据库没有暂停,并配置有 8 个最大 vCore 和 1 个最小 vCore(对应于 3.0 GB 的最小内存)。 那么,最小计算费用将基于最大值(1 vCore,3.0 GB * 1 vCore / 3 GB)= 1 vCore。
- 假设常规用途层级中的无服务器数据库没有暂停,并配置有 4 个最大 vCore 和 0.5 个最小 vCore(对应于 2.1 GB 的最小内存)。 那么,最小计算费用基于最大值(0.5 vCore,2.1 GB * 1 vCore / 3 GB)= 0.7 vCore。
- 假设超大规模层级中的无服务器数据库包含一个具有一个 HA 副本的主要副本和一个没有 HA 副本的命名副本。 假设每个副本配置有 8 个最大 vCore 和 1 个最小 vCore(对应于 3 GB 的最小内存)。 然后,主要副本、HA 副本和命名副本的最低计算费用分别基于最大值(1 个 vCore、3 GB * 1 个 vCore / 3 GB)= 1 个 vCore。
无服务器的 Azure SQL 数据库定价计算器可用于根据配置的最大和最小 vCore 数来确定可配置的最小内存。 通常,如果配置的最小 vCore 数大于 0.5 个 vCore,则最小计算费用与配置的最小内存无关,仅基于配置的最小 vCore 数。
场景示例
假设为常规用途层级中的某个无服务器数据库配置了最小 vCore 数 1 和最大 vCore 数 4。 此配置相当于最小内存大约为 3 GB,最大内存大约为 12 GB。 假设自动暂停延迟设置为 6 小时,数据库工作负荷在 24 小时内的前 2 小时处于活动状态,在其他时间处于非活动状态。
在这种情况下,将会计收数据库在前 8 小时内的计算和存储费用。 尽管数据库在 2 小时后处于非活动状态,但仍会根据预配的最小计算资源,计收数据库联机时的后续 6 小时的计算费用。 当数据库暂停时,只会计收 24 小时时段的剩余时间内的存储费用。
更具体地说,此示例中的计算费用的计算方式如下:
| 时间间隔 | 每秒使用的 vCore 数 | 每秒使用的 GB 量 | 计费的计算维度 | 时间间隔内计费的 vCore 秒数 |
|---|---|---|---|---|
| 0:00-1:00 | 4 | 9 | 使用的 vCore 数 | 4 个 vCore * 3600 秒 = 14400 vCore 秒 |
| 1:00-2:00 | 1 | 12 | 使用的内存量 | 12 GB * 1/3 * 3600 秒 = 14400 vCore 秒 |
| 2:00-8:00 | 0 | 0 | 预配的最小内存 | 3 GB * 1/3 * 21600 秒 = 21600 vCore 秒 |
| 8:00-24:00 | 0 | 0 | 暂停时不计收计算费用 | 0 vCore 秒 |
| 24 小时内计费的总 vCore 秒 | 50400 vCore 秒 |
假设计算单位的价格为 ¥0.001087/vCore/秒。 那么,此 24 小时时段内的计算费用是计算单位价格和计费 vCore 秒数的积:¥0.001087/vCore/秒 * 50400 vCore 秒 = ¥54.81。
Azure 混合权益
Azure 混合权益 (AHB) 不适用于无服务器计算层。
可用区域
最多支持 40 个最大 vCore 的常规用途和超大规模无服务器计算层在全球可用,但以下区域除外:
- 中国东部
- 中国北部
相关内容
- 有关入门指南,请参阅快速入门:创建单一数据库 - Azure SQL 数据库。
- 有关无服务器服务层级选择,请参阅常规用途和超大规模。