Azure Functions Node.js 开发人员指南
本指南介绍了如何使用 JavaScript 或 TypeScript 开发 Azure Functions。 本文假定你已阅读 Azure Functions 开发人员指南。
重要
本文的内容根据你在此页顶部的选择器中选择的 Node.js 编程模型而异。 你选择的版本应与你在应用中使用的 @azure/functions npm 包的版本匹配。 如果在 package.json 中未列出该包,则默认值为 v3。 在迁移指南中详细了解 v3 和 v4 之间的差异。
作为 Node.js 开发人员,你可能还会对下列某篇文章感兴趣:
| 入门 | 概念 | 指导式学习 |
|---|---|---|
注意事项
注意
Node.js 编程模型的版本 4 目前为公共预览版。
- 在预览期间,v4 模型要求将应用设置
AzureWebJobsFeatureFlags设为EnableWorkerIndexing。 有关详细信息,请参阅启用 v4 编程模型。 - 不应将 Node.js“编程模型”与 Azure Functions“运行时”混淆。
- 编程模型:定义代码的创作方式,并特定于 JavaScript 和 TypeScript。
- 运行时:定义 Azure Functions 的基础行为,并在所有语言之间共享。
- 编程模型版本严格绑定到
@azure/functionsnpm 包的版本,并且独立于运行时进行版本控制。 运行时和编程模型都使用“4”作为其最新主版本,但这纯粹是巧合。 - 请记住,不能在同一函数应用中混用 v3 和 v4 编程模型。 在应用中注册一个 v4 函数后,
function.json文件中注册的任何 v3 函数都将被忽略。
支持的版本
下表显示了 Node.js 编程模型的每个版本及其支持的 Azure Functions 运行时版本和 Node.js。
| 编程模型版本 | 支持级别 | Functions 运行时版本 | Node.js 版本 | 说明 |
|---|---|---|---|---|
| 4.x | GA | 4.25+ | 20.x,、18.x | 支持灵活的文件结构和以代码为中心的触发器和绑定方法。 |
| 3.x | GA | 4.x | 20.x、18.x、16.x、14.x | 需要特定的文件结构,以及在“function.json”文件中声明的触发器和绑定 |
| 2.x | 不适用 | 3.x | 14.x、12.x、10.x | 已于 2022 年 12 月 13 日终止支持。 有关详细信息,请参阅 Functions 版本。 |
| 1.x | 不适用 | 2.x | 10.x、8.x | 已于 2022 年 12 月 13 日终止支持。 有关详细信息,请参阅 Functions 版本。 |
文件夹结构
JavaScript 项目所需的文件夹结构如下所示:
<project_root>/
| - .vscode/
| - node_modules/
| - myFirstFunction/
| | - index.js
| | - function.json
| - mySecondFunction/
| | - index.js
| | - function.json
| - .funcignore
| - host.json
| - local.settings.json
| - package.json
主项目文件夹 <project_root> 可以包含以下文件:
- .vscode/:(可选)包含存储的 Visual Studio Code 配置。 若要了解详细信息,请参阅 Visual Studio Code 设置。
- myFirstFunction/function.json:包含函数的触发器、输入和输出的配置。 目录名称决定了函数名称。
- myFirstFunction/index.js:存储函数代码。 要更改此默认文件路径,请参阅使用 scriptFile。
- .funcignore:(可选)声明不应发布到 Azure 的文件。 通常,此文件包含 .vscode/ 以忽略编辑器设置,包含 .venv/ 以忽略测试用例,包含 local.settings.json 以阻止发布本地应用设置。
- host.json:包含在函数应用实例中影响所有函数的配置选项。 此文件会被发布到 Azure。 本地运行时,并非所有选项都受支持。 若要了解详细信息,请参阅 host.json。
- local.settings.json:用于在本地运行时存储应用设置和连接字符串。 此文件不会被发布到 Azure。 若要了解详细信息,请参阅 local.settings.file。
- package.json:包含配置选项,例如包依赖项列表、主入口点和脚本。
JavaScript 项目的建议文件夹结构如以下示例所示:
<project_root>/
| - .vscode/
| - node_modules/
| - src/
| | - functions/
| | | - myFirstFunction.js
| | | - mySecondFunction.js
| - test/
| | - functions/
| | | - myFirstFunction.test.js
| | | - mySecondFunction.test.js
| - .funcignore
| - host.json
| - local.settings.json
| - package.json
主项目文件夹 <project_root> 可以包含以下文件:
- .vscode/:(可选)包含存储的 Visual Studio Code 配置。 若要了解详细信息,请参阅 Visual Studio Code 设置。
- src/functions/:所有函数及其相关触发器和绑定的默认位置。
- test/:(可选)包含函数应用的测试用例。
- .funcignore:(可选)声明不应发布到 Azure 的文件。 通常,此文件包含 .vscode/ 以忽略编辑器设置,包含 .venv/ 以忽略测试用例,包含 local.settings.json 以阻止发布本地应用设置。
- host.json:包含在函数应用实例中影响所有函数的配置选项。 此文件会被发布到 Azure。 本地运行时,并非所有选项都受支持。 若要了解详细信息,请参阅 host.json。
- local.settings.json:用于在本地运行时存储应用设置和连接字符串。 此文件不会被发布到 Azure。 若要了解详细信息,请参阅 local.settings.file。
- package.json:包含配置选项,例如包依赖项列表、主入口点和脚本。
注册函数
v3 模型基于两个文件的存在来注册函数。 首先,需要位于应用根目录下一级文件夹中的 function.json 文件。 其次,需要一个 JavaScript 文件来导出函数。 默认情况下,模型会在与 function.json 相同的文件夹中查找 index.js 文件。 如果使用 TypeScript,则必须使用 function.json 中的 scriptFile 属性来指向已编译的 JavaScript 文件。 要自定义函数的文件位置或导出名称,请参阅配置函数的入口点。
导出的函数在 v3 模型中应该始终声明为 async function。 可以导出同步函数,但必须调用 context.done() 以发出函数已完成的信号,这已弃用,也不建议使用。
函数被传递调用context作为第一个参数,输入作为剩余的参数。
以下示例是简单的函数,它记录了其已被触发并响应了 Hello, world!:
{
"bindings": [
{
"type": "httpTrigger",
"direction": "in",
"name": "req",
"authLevel": "anonymous",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "res"
}
]
}
module.exports = async function (context, request) {
context.log('Http function was triggered.');
context.res = { body: 'Hello, world!' };
};
编程模型会基于你的 package.json 中的 main 字段加载函数。 可以使用 glob 模式将 main 字段设为单个文件或多个文件。 下表所示为 main 字段的示例值:
| 示例 | 说明 |
|---|---|
src/index.js |
从单个根文件注册函数。 |
src/functions/*.js |
从其自己的文件中注册每个函数。 |
src/{index.js,functions/*.js} |
从其自己的文件中注册每个函数的组合,但仍有一个常规应用级代码的根文件。 |
若要注册函数,必须从 @azure/functions npm 模块导入 app 对象,并调用特定于触发器类型的方法。 注册函数时的第一个参数为函数名称。 第二个参数是一个 options 对象,该对象指定触发器、处理程序以及任何其他输入或输出的配置。 在某些情况下,如果不需要触发器配置,可以直接将处理程序作为第二个参数而不是 options 对象进行传递。
可以从项目中的任何文件注册函数,前提是该文件已基于 package.json 文件中的 main 字段加载(直接或间接)。 函数应在全局范围内注册,因为执行开始后无法注册函数。
以下示例是简单的函数,它记录了其已被触发并响应了 Hello, world!:
const { app } = require('@azure/functions');
app.http('helloWorld1', {
methods: ['POST', 'GET'],
handler: async (request, context) => {
context.log('Http function was triggered.');
return { body: 'Hello, world!' };
}
});
输入和输出
你的函数需要恰好有一个称为触发器的主输入。 它也可以具有辅助输入和/或输出。 输入和输出在 function.json 文件中进行配置,也称为绑定。
输入
输入是 direction 设置为 in 的绑定。 触发器和辅助输入之间的主要区别在于,触发器的 type 以 Trigger 结尾,例如类型 blobTrigger 与类型 blob。 大多数函数只使用触发器,不支持许多辅助输入类型。
可以通过以下几种方式访问输入:
[建议] 作为传递给函数的参数: 按照
function.json中定义的顺序使用参数。function.json中定义的name属性不需要与参数的名称匹配,尽管出于组织考虑建议使用该属性。module.exports = async function (context, myTrigger, myInput, myOtherInput) { ... };作为
context.bindings的属性:使用与function.json中定义的name属性匹配的键。module.exports = async function (context) { context.log("This is myTrigger: " + context.bindings.myTrigger); context.log("This is myInput: " + context.bindings.myInput); context.log("This is myOtherInput: " + context.bindings.myOtherInput); };
Outputs
输出是 direction 设置为 out 的绑定,可以通过多种方式进行设置:
[建议用于单个输出] 直接返回值:如果使用的是异步函数,则可以直接返回值。 必须将输出绑定的
name属性更改为function.json中的$return,如以下示例所示:{ "name": "$return", "type": "http", "direction": "out" }module.exports = async function (context, request) { return { body: "Hello, world!" }; }[建议用于多个输出] 返回包含所有输出的对象:如果使用的是异步函数,那么可以返回属性与
function.json中每个绑定的名称相匹配的对象。 以下示例使用名为“httpResponse”和“queueOutput”的输出绑定:{ "name": "httpResponse", "type": "http", "direction": "out" }, { "name": "queueOutput", "type": "queue", "direction": "out", "queueName": "helloworldqueue", "connection": "storage_APPSETTING" }module.exports = async function (context, request) { let message = 'Hello, world!'; return { httpResponse: { body: message }, queueOutput: message }; };在
context.bindings上设置值:如果没有使用异步函数或不想使用前面的选项,可以直接在context.bindings上设置值,其中键与绑定的名称相匹配。 以下示例使用名为“httpResponse”和“queueOutput”的输出绑定:{ "name": "httpResponse", "type": "http", "direction": "out" }, { "name": "queueOutput", "type": "queue", "direction": "out", "queueName": "helloworldqueue", "connection": "storage_APPSETTING" }module.exports = async function (context, request) { let message = 'Hello, world!'; context.bindings.httpResponse = { body: message }; context.bindings.queueOutput = message; };
绑定数据类型
可以在输入绑定上使用 dataType 属性来更改输入的类型,但它有一些限制:
- 在 Node.js 中,仅支持
string和binary(不支持stream) - 对于 HTTP 输入,将忽略
dataType属性。 相反,使用request对象的属性以获得所需格式的正文。 有关详细信息,请参阅 HTTP 请求。
在下面的存储队列触发器示例中,myQueueItem 的默认类型为 string,但如果将 dataType 设置为 binary,则类型将更改为 Node.jsBuffer。
{
"name": "myQueueItem",
"type": "queueTrigger",
"direction": "in",
"queueName": "helloworldqueue",
"connection": "storage_APPSETTING",
"dataType": "binary"
}
const { Buffer } = require('node:buffer');
module.exports = async function (context, myQueueItem) {
if (typeof myQueueItem === 'string') {
context.log('myQueueItem is a string');
} else if (Buffer.isBuffer(myQueueItem)) {
context.log('myQueueItem is a buffer');
}
};
你的函数需要恰好有一个称为触发器的主输入。 它还可能具有辅助输入、称为返回输出的主输出和/或辅助输出。 输入和输出也称为 Node.js 编程模型上下文之外的绑定。 在模型 v4 之前,这些绑定是在 function.json 文件中配置的。
触发器输入
触发器是唯一必需的输入或输出。 对于大多数触发器类型,可以在以触发器类型命名的 app 对象上使用方法注册函数。 可以直接在 options 参数上指定特定于触发器的配置。 例如,HTTP 触发器允许指定路由。 在执行期间,与此触发器对应的值作为第一个参数传入处理程序。
const { app } = require('@azure/functions');
app.http('helloWorld1', {
route: 'hello/world',
handler: async (request, context) => {
...
}
});
返回输出
返回输出是可选的,在某些情况下是默认配置的。 例如,向 app.http 注册的 HTTP 触发器配置为自动返回 HTTP 响应输出。 对于大多数输出类型,请借助从 @azure/functions 模块导出的 output 对象,在 options 参数上指定返回配置。 在执行期间,可以通过从处理程序返回此输出来设置它。
const { app, output } = require('@azure/functions');
app.timer('timerTrigger1', {
schedule: '0 */5 * * * *',
return: output.storageQueue({
connection: 'storage_APPSETTING',
...
}),
handler: (myTimer, context) => {
return { hello: 'world' }
}
});
额外输入和输出
除了触发器和返回之外,还可以在注册函数时在 options 参数上指定额外的输入或输出。 从 @azure/functions 模块导出的 input 和 output 对象提供特定于类型的方法来帮助构造配置。 在执行期间,使用 context.extraInputs.get 或 context.extraOutputs.set 获取或设置值,将原始配置对象作为第一个参数传入。
以下示例是由存储队列触发的函数,具有额外的存储 blob 输入,该输入被复制到额外存储 blob 输出。 队列消息应该是文件的名称,并在绑定表达式的帮助下将 {queueTrigger} 替换为要复制的 blob 名称。
const { app, input, output } = require('@azure/functions');
const blobInput = input.storageBlob({
connection: 'storage_APPSETTING',
path: 'helloworld/{queueTrigger}',
});
const blobOutput = output.storageBlob({
connection: 'storage_APPSETTING',
path: 'helloworld/{queueTrigger}-copy',
});
app.storageQueue('copyBlob1', {
queueName: 'copyblobqueue',
connection: 'storage_APPSETTING',
extraInputs: [blobInput],
extraOutputs: [blobOutput],
handler: (queueItem, context) => {
const blobInputValue = context.extraInputs.get(blobInput);
context.extraOutputs.set(blobOutput, blobInputValue);
}
});
泛型输入和输出
模块 @azure/functions 导出的 app、trigger、input 和 output 对象为大多数类型提供特定于类型的方法。 对于不支持的所有类型,可通过 generic 方法手动指定配置。 如果要更改特定于类型的方法提供的默认设置,也可以使用 generic 方法。
以下示例是使用泛型方法而不是特定于类型的方法的简单 HTTP 触发器函数。
const { app, output, trigger } = require('@azure/functions');
app.generic('helloWorld1', {
trigger: trigger.generic({
type: 'httpTrigger',
methods: ['GET', 'POST']
}),
return: output.generic({
type: 'http'
}),
handler: async (request, context) => {
context.log(`Http function processed request for url "${request.url}"`);
return { body: `Hello, world!` };
}
});
调用上下文
函数的每次调用都会传递调用 context 对象,用于读取输入、设置输出、写入日志和读取各种元数据。 在 v3 模型中,上下文对象始终是传递给处理程序的第一个参数。
context 对象具有以下属性:
| 属性 | 说明 |
|---|---|
invocationId |
当前函数调用的 ID。 |
executionContext |
请参阅执行上下文。 |
bindings |
请参阅绑定。 |
bindingData |
关于此调用的触发器输入的元数据,不包括值本身。 例如,事件中心触发器具有 enqueuedTimeUtc 属性。 |
traceContext |
分布式跟踪的上下文。 有关详细信息,请参阅 Trace Context。 |
bindingDefinitions |
输入和输出的配置,如 function.json 中所定义。 |
req |
请参阅 HTTP 请求。 |
res |
请参阅 HTTP 响应。 |
context.executionContext
context.executionContext 对象具有以下属性:
| 属性 | 说明 |
|---|---|
invocationId |
当前函数调用的 ID。 |
functionName |
正在调用的函数的名称。 包含 function.json 文件的文件夹的名称决定了函数的名称。 |
functionDirectory |
包含 function.json 文件的文件夹。 |
retryContext |
请参阅重试上下文。 |
context.executionContext.retryContext
context.executionContext.retryContext 对象具有以下属性:
| 属性 | 说明 |
|---|---|
retryCount |
表示当前重试尝试的数字。 |
maxRetryCount |
重试执行的最大次数。 值为 -1 表示重试无限次数。 |
exception |
导致重试的异常。 |
context.bindings
context.bindings 对象用于读取输入或设置输出。 以下示例是存储队列触发器,其使用 context.bindings 将存储 blob 输入复制到存储 blob 输出。 在绑定表达式的帮助下,队列消息的内容将 {queueTrigger} 替换为要复制的文件名。
{
"name": "myQueueItem",
"type": "queueTrigger",
"direction": "in",
"connection": "storage_APPSETTING",
"queueName": "helloworldqueue"
},
{
"name": "myInput",
"type": "blob",
"direction": "in",
"connection": "storage_APPSETTING",
"path": "helloworld/{queueTrigger}"
},
{
"name": "myOutput",
"type": "blob",
"direction": "out",
"connection": "storage_APPSETTING",
"path": "helloworld/{queueTrigger}-copy"
}
module.exports = async function (context, myQueueItem) {
const blobValue = context.bindings.myInput;
context.bindings.myOutput = blobValue;
};
context.done
context.done 方法已弃用。 在支持异步函数之前,将通过调用 context.done() 来发出函数已完成的信号:
module.exports = function (context, request) {
context.log("this pattern is now deprecated");
context.done();
};
现在,建议删除对 context.done() 的调用,并将函数标记为异步,以便它返回承诺(即使不 await)。 函数完成后(换句话说,返回的承诺已解析),v3 模型就知道函数已经完成。
module.exports = async function (context, request) {
context.log("you don't need context.done or an awaited call")
};
函数的每次调用都会传递调用 context 对象,其中包含有关调用和用于日志记录方法的信息。 在 v4 模型中,context 对象通常是传递给处理程序的第二个参数。
InvocationContext 类具有以下属性:
| properties | 说明 |
|---|---|
invocationId |
当前函数调用的 ID。 |
functionName |
函数的名称。 |
extraInputs |
用于获取额外输入的值。 有关更多信息,请参阅额外的输入和输出。 |
extraOutputs |
用于设置额外输出的值。 有关更多信息,请参阅额外的输入和输出。 |
retryContext |
请参阅重试上下文。 |
traceContext |
分布式跟踪的上下文。 有关详细信息,请参阅 Trace Context。 |
triggerMetadata |
关于此调用的触发器输入的元数据,不包括值本身。 例如,事件中心触发器具有 enqueuedTimeUtc 属性。 |
options |
在验证函数后注册函数时使用的选项,并显式指定了默认值。 |
重试上下文
retryContext 对象具有以下属性:
| 属性 | 说明 |
|---|---|
retryCount |
表示当前重试尝试的数字。 |
maxRetryCount |
重试执行的最大次数。 值为 -1 表示重试无限次数。 |
exception |
导致重试的异常。 |
有关详细信息,请参阅 retry-policies。
Logging
在 Azure Functions 中,建议使用 context.log() 来写入日志。 Azure Functions 与 Azure Application Insights 相集成,从而能够更好地捕获函数应用日志。 Application Insights 是 Azure Monitor 的一部分,提供对应用程序日志和跟踪输出进行收集、视觉呈现和分析的工具。 若要了解详细信息,请参阅监视 Azure Functions。
注意
如果使用替代的 Node.js console.log 方法,则会在应用级别跟踪这些日志,并且不会与任何特定函数相关联。 强烈建议使用 context 进行日志记录而不是 console,以便所有日志都与特定函数相关联。
以下示例以默认的“信息”级别写入日志,包括调用 ID:
context.log(`Something has happened. Invocation ID: "${context.invocationId}"`);
日志级别
除了默认 context.log 方法外,还提供了以下方法,可以在特定级别写入日志:
| 方法 | 说明 |
|---|---|
context.log.error() |
将错误级别的事件写入到日志。 |
context.log.warn() |
将警告级别的事件写入到日志。 |
context.log.info() |
将信息级别的事件写入到日志。 |
context.log.verbose() |
将跟踪级别事件写入日志。 |
| 方法 | 说明 |
|---|---|
context.trace() |
将跟踪级别事件写入日志。 |
context.debug() |
将调试级别的事件写入日志。 |
context.info() |
将信息级别的事件写入到日志。 |
context.warn() |
将警告级别的事件写入到日志。 |
context.error() |
将错误级别的事件写入到日志。 |
配置日志级别
Azure Functions 允许定义跟踪和查看日志时要使用的阈值级别。 若要设置阈值,请使用 host.json 文件中的 logging.logLevel 属性。 此属性允许定义应用于所有函数的默认级别,或每个单独函数的阈值。 若要了解详细信息,请参阅如何配置对 Azure Functions 的监视。
跟踪自定义数据
默认情况下,Azure Functions 会将输出作为跟踪写入到 Application Insights。 为了加强控制,可以改用 Application Insights Node.js SDK 将自定义数据发送到 Application Insights 实例。
const appInsights = require("applicationinsights");
appInsights.setup();
const client = appInsights.defaultClient;
module.exports = async function (context, request) {
// Use this with 'tagOverrides' to correlate custom logs to the parent function invocation.
var operationIdOverride = {"ai.operation.id":context.traceContext.traceparent};
client.trackEvent({name: "my custom event", tagOverrides:operationIdOverride, properties: {customProperty2: "custom property value"}});
client.trackException({exception: new Error("handled exceptions can be logged with this method"), tagOverrides:operationIdOverride});
client.trackMetric({name: "custom metric", value: 3, tagOverrides:operationIdOverride});
client.trackTrace({message: "trace message", tagOverrides:operationIdOverride});
client.trackDependency({target:"http://dbname", name:"select customers proc", data:"SELECT * FROM Customers", duration:231, resultCode:0, success: true, dependencyTypeName: "ZSQL", tagOverrides:operationIdOverride});
client.trackRequest({name:"GET /customers", url:"http://myserver/customers", duration:309, resultCode:200, success:true, tagOverrides:operationIdOverride});
};
tagOverrides 参数将 operation_Id 设置为函数的调用 ID。 通过此设置,可为给定的函数调用关联所有自动生成的日志和自定义日志。
HTTP 触发器
HTTP 和 Webhook 触发器使用请求和响应对象来表示 HTTP 消息。
HTTP 请求
可以通过以下几种方式访问请求:
作为函数的第二个参数:
module.exports = async function (context, request) { context.log(`Http function processed request for url "${request.url}"`);从
context.req属性:module.exports = async function (context, request) { context.log(`Http function processed request for url "${context.req.url}"`);从命名的输入绑定:此选项与任何非 HTTP 绑定的工作原理相同。
function.json中的绑定名称必须与context.bindings上的键或以下示例中的“request1”匹配:{ "name": "request1", "type": "httpTrigger", "direction": "in", "authLevel": "anonymous", "methods": [ "get", "post" ] }module.exports = async function (context, request) { context.log(`Http function processed request for url "${context.bindings.request1.url}"`);
HttpRequest 对象具有以下属性:
| 属性 | 类型 | 说明 |
|---|---|---|
method |
string |
用于调用此函数的 HTTP 请求方法。 |
url |
string |
请求 URL。 |
headers |
Record<string, string> |
HTTP 请求头。 此对象区分大小写。 建议使用不区分大小写的 request.getHeader('header-name')。 |
query |
Record<string, string> |
从 URL 中查询字符串参数键和值。 |
params |
Record<string, string> |
路由参数键和值。 |
user |
HttpRequestUser | null |
表示已登录用户的对象,可以通过 Functions 身份验证、SWA 身份验证或(在没有此类用户登录时)null。 |
body |
Buffer | string | any |
如果媒体类型是“application/octet-stream”或“multipart/*”,则 body 是缓冲区。 如果值是 JSON 可解析字符串,那么 body 就是已分析的对象。 否则,body 是字符串。 |
rawBody |
string |
正文作为字符串。 尽管名称如此,但此属性不返回缓冲区。 |
bufferBody |
Buffer |
正文作为缓冲区。 |
可以将请求作为 HTTP 触发器函数的处理程序的第一个参数进行访问。
async (request, context) => {
context.log(`Http function processed request for url "${request.url}"`);
HttpRequest 对象具有以下属性:
| 属性 | 类型 | 说明 |
|---|---|---|
method |
string |
用于调用此函数的 HTTP 请求方法。 |
url |
string |
请求 URL。 |
headers |
Headers |
HTTP 请求头。 |
query |
URLSearchParams |
从 URL 中查询字符串参数键和值。 |
params |
Record<string, string> |
路由参数键和值。 |
user |
HttpRequestUser | null |
表示已登录用户的对象,可以通过 Functions 身份验证、SWA 身份验证或(在没有此类用户登录时)null。 |
body |
ReadableStream | null |
正文作为可读流。 |
bodyUsed |
boolean |
布尔值,指示正文是否已被读取。 |
为了访问请求或响应的正文,可以使用以下方法:
| 方法 | 返回类型 |
|---|---|
arrayBuffer() |
Promise<ArrayBuffer> |
blob() |
Promise<Blob> |
formData() |
Promise<FormData> |
json() |
Promise<unknown> |
text() |
Promise<string> |
注意
正文函数只能运行一次;后续调用将使用空字符串/ArrayBuffers 解析。
HTTP 响应
可以通过以下几种方式设置响应:
设置
context.res属性:module.exports = async function (context, request) { context.res = { body: `Hello, world!` };返回响应:如果函数是异步的,并且在
function.json中将绑定名称设置为$return,则可以直接返回响应,而不是在context上设置它。{ "type": "http", "direction": "out", "name": "$return" }module.exports = async function (context, request) { return { body: `Hello, world!` };设置命名输出绑定:此选项与任何非 HTTP 绑定的工作原理相同。
function.json中的绑定名称必须与context.bindings上的键或以下示例中的“response1”匹配:{ "type": "http", "direction": "out", "name": "response1" }module.exports = async function (context, request) { context.bindings.response1 = { body: `Hello, world!` };调用
context.res.send():此选项已弃用。 它隐式调用context.done(),不能在异步函数中使用。module.exports = function (context, request) { context.res.send(`Hello, world!`);
如果在设置响应时创建新对象,则该对象必须与具有以下属性的 HttpResponseSimple 接口匹配:
| 属性 | 类型 | 说明 |
|---|---|---|
headers |
Record<string, string>(可选) |
HTTP 响应头。 |
cookies |
Cookie[](可选) |
HTTP 响应 Cookie。 |
body |
any(可选) |
HTTP 响应正文。 |
statusCode |
number(可选) |
HTTP 响应状态代码。 如果未设置,则默认为 200。 |
status |
number(可选) |
与 statusCode 相同。 如果设置了 statusCode,则忽略此属性。 |
也可以在不覆盖对象的情况下修改 context.res 对象。 默认 context.res 对象使用 HttpResponseFull 接口,该接口除了支持 HttpResponseSimple 属性外,还支持以下方法:
| 方法 | 说明 |
|---|---|
status() |
设置状态。 |
setHeader() |
设置标头字段。 注意:res.set() 和 res.header() 也受支持,并执行相同的操作。 |
getHeader() |
获取标头字段。 注意:res.get() 也受支持,并执行相同的操作。 |
removeHeader() |
移除标头。 |
type() |
设置“content-type”标头。 |
send() |
不推荐使用此方法。 它设置正文并调用 context.done() 以指示同步功能已完成。 注意:res.end() 也受支持,并执行相同的操作。 |
sendStatus() |
不推荐使用此方法。 它设置状态代码并调用 context.done() 以指示同步功能已完成。 |
json() |
不推荐使用此方法。 它将“content-type”设置为“application/json”,设置正文,并调用 context.done() 来指示同步函数已完成。 |
可以通过以下几种方式设置响应:
作为类型
HttpResponseInit的简单接口:此选项是返回响应的最简洁方式。return { body: `Hello, world!` };HttpResponseInit接口具有以下属性:属性 类型 说明 bodyBodyInit(可选)HTTP 响应正文,作为 ArrayBuffer、AsyncIterable<Uint8Array>、Blob、FormData、Iterable<Uint8Array>、NodeJS.ArrayBufferView、URLSearchParams、null或string中的一个。jsonBodyany(可选)JSON 可序列化的 HTTP 响应正文。 如果已设置,将忽略 HttpResponseInit.body属性并使用此属性。statusnumber(可选)HTTP 响应状态代码。 如果未设置,则默认为 200。headersHeadersInit(可选)HTTP 响应头。 cookiesCookie[](可选)HTTP 响应 Cookie。 作为
HttpResponse类型的类:此选项提供用于读取和修改响应的各个部分(如标头)的帮助程序方法。const response = new HttpResponse({ body: `Hello, world!` }); response.headers.set('content-type', 'application/json'); return response;HttpResponse类接受可选的HttpResponseInit作为其构造函数的参数,并具有以下属性:属性 类型 说明 statusnumberHTTP 响应状态代码。 headersHeadersHTTP 响应头。 cookiesCookie[]HTTP 响应 Cookie。 bodyReadableStream | null正文作为可读流。 bodyUsedboolean布尔值,指示正文是否已经被读取。
HTTP 流
HTTP 流是一项功能,可更轻松地处理大型数据、流式传输 OpenAI 响应、提供动态内容并支持其他核心 HTTP 方案。 它允许在 Node.js 函数应用中流式传输对 HTTP 终结点的请求和响应。 HTTP 流适用于应用需要通过 HTTP 进行客户端和服务器之间的实时交换和交互的情况。 HTTP 流还可以用于在使用 HTTP 时获取应用的最佳性能和可靠性。
重要
v3 模型中不支持 HTTP 流。 升级到 v4 模型以使用 HTTP 流式处理功能。
编程模型 v4 中的现有 HttpRequest 和 HttpResponse 类型已支持处理消息正文的各种方法,包括以流的形式处理。
先决条件
@azure/functionsnpm 包版本 4.3.0 或更高版本。- Azure Functions 运行时版本 4.28 或更高版本。
- Azure Functions Core Tools 版本 4.0.5530 或更高版本,其中包含正确的运行时版本。
启用流
使用以下步骤在 Azure 和本地项目的函数应用中启用 HTTP 流:
如果计划流式传输大量数据,请修改 Azure 中的
FUNCTIONS_REQUEST_BODY_SIZE_LIMIT设置。 允许的默认最大正文大小是104857600,这会将请求限制为大约 100 MB。对于本地开发,还需要将
FUNCTIONS_REQUEST_BODY_SIZE_LIMIT添加到 local.settings.json 文件。将以下代码添加到主字段包含的任何文件中的应用。
const { app } = require('@azure/functions'); app.setup({ enableHttpStream: true });
流示例
此示例演示了 HTTP 触发的函数,该函数通过 HTTP POST 请求接收数据,并将此数据流式传输到指定的输出文件:
const { app } = require('@azure/functions');
const { createWriteStream } = require('fs');
const { Writable } = require('stream');
app.http('httpTriggerStreamRequest', {
methods: ['POST'],
authLevel: 'anonymous',
handler: async (request, context) => {
const writeStream = createWriteStream('<output file path>');
await request.body.pipeTo(Writable.toWeb(writeStream));
return { body: 'Done!' };
},
});
此示例显示 HTTP 触发的函数,该函数将文件的内容作为对传入 HTTP GET 请求的响应进行流式传输:
const { app } = require('@azure/functions');
const { createReadStream } = require('fs');
app.http('httpTriggerStreamResponse', {
methods: ['GET'],
authLevel: 'anonymous',
handler: async (request, context) => {
const body = createReadStream('<input file path>');
return { body };
},
});
有关使用流准备运行的示例应用,请查看 GitHub 上的此示例。
流注意事项
- 利用
request.body可以在使用流的过程中获取最大优势。 你仍然可以继续使用request.text()等方法,始终以字符串的形式返回正文。
挂钩
v3 模型中不支持挂钩。 升级到 v4 模型即可使用挂钩。
使用挂钩在 Azure Functions 生命周期的不同点执行代码。 挂钩按注册顺序执行,并且可以从应用中的任何文件注册。 目前有两个挂钩作用域:“应用”级别和“调用”级别。
调用挂钩
每次调用函数时都会执行一次调用挂钩,在 preInvocation 挂钩之前或在 postInvocation 挂钩之后执行。 默认情况下,挂钩针对所有触发器类型执行,但也可以按类型进行筛选。 以下示例所示为如何按触发器类型注册调用挂钩及进行筛选:
const { app } = require('@azure/functions');
app.hook.preInvocation((context) => {
if (context.invocationContext.options.trigger.type === 'httpTrigger') {
context.invocationContext.log(
`preInvocation hook executed for http function ${context.invocationContext.functionName}`
);
}
});
app.hook.postInvocation((context) => {
if (context.invocationContext.options.trigger.type === 'httpTrigger') {
context.invocationContext.log(
`postInvocation hook executed for http function ${context.invocationContext.functionName}`
);
}
});
挂钩处理程序的第一个参数是特定于该挂钩类型的上下文对象。
PreInvocationContext 对象具有以下属性:
| 属性 | 说明 |
|---|---|
inputs |
传递给调用的参数。 |
functionHandler |
调用的函数处理程序。 对此值的更改会影响函数本身。 |
invocationContext |
传递给函数的调用上下文对象。 |
hookData |
建议在同一作用域中的挂钩之间存储和共享数据的位置。 应使用唯一的属性名称,以免与其他挂钩的数据冲突。 |
PostInvocationContext 对象具有以下属性:
| 属性 | 说明 |
|---|---|
inputs |
传递给调用的参数。 |
result |
函数的结果。 对此值的更改会影响函数的整体结果。 |
error |
函数引发的错误,如果没有错误则为 null/undefined。 对此值的更改会影响函数的整体结果。 |
invocationContext |
传递给函数的调用上下文对象。 |
hookData |
建议在同一作用域中的挂钩之间存储和共享数据的位置。 应使用唯一的属性名称,以免与其他挂钩的数据冲突。 |
应用挂钩
应用挂钩在应用的每个实例中执行一次,无论是在 appStart 挂钩中启动期间还是在 appTerminate 挂钩中终止期间。 应用终止挂钩的执行时间有限,并且并非在所有情况下都执行。
Azure Functions 运行时当前不支持调用以外的上下文日志记录。 使用 Application Insights npm 包在应用级别挂钩期间记录数据。
下面的示例注册了应用挂钩:
const { app } = require('@azure/functions');
app.hook.appStart((context) => {
// add your logic here
});
app.hook.appTerminate((context) => {
// add your logic here
});
挂钩处理程序的第一个参数是特定于该挂钩类型的上下文对象。
AppStartContext 对象具有以下属性:
| 属性 | 说明 |
|---|---|
hookData |
建议在同一作用域中的挂钩之间存储和共享数据的位置。 应使用唯一的属性名称,以免与其他挂钩的数据冲突。 |
AppTerminateContext 对象具有以下属性:
| 属性 | 说明 |
|---|---|
hookData |
建议在同一作用域中的挂钩之间存储和共享数据的位置。 应使用唯一的属性名称,以免与其他挂钩的数据冲突。 |
缩放和并发
默认情况下,Azure Functions 会自动监视应用程序的负载,并根据需要为 Node.js 创建更多主机实例。 Azure Functions 针对不同触发器类型使用内置(用户不可配置)阈值来确定何时添加实例,例如消息的年龄和 QueueTrigger 的队列大小。 有关详细信息,请参阅消耗计划和高级计划的工作原理。
此缩放行为足以满足多个 Node.js 应用程序的需求。 对于占用大量 CPU 的应用程序,可使用多个语言工作进程进一步提高性能。 通过使用 FUNCTIONS_WORKER_PROCESS_COUNT 应用程序设置,可以将每个主机的辅助角色数从默认值 1 增加到最大值 10。 然后,Azure Functions 会尝试在这些工作进程之间平均分配同步函数调用。 此行为降低了 CPU 密集型函数阻止其他函数运行的可能性。 设置适用于 Azure Functions 在扩展应用程序来满足需求时创建的每一个主机。
警告
请慎用 FUNCTIONS_WORKER_PROCESS_COUNT 设置。 在同一实例中运行的多个进程可能会导致不可预测的行为,并增加函数加载时间。 如果使用此设置,强烈建议通过从包文件运行来抵消这些缺点。
Node 版本
可以通过从任何函数中记录 process.version 来查看运行时使用的当前版本。 有关每个编程模型支持的 Node.js 版本的列表,请参阅 supported versions。
设置 Node 版本
升级 Node.js 版本的方式取决于运行函数应用的操作系统。
在 Windows 上运行时,Node.js 版本由 WEBSITE_NODE_DEFAULT_VERSION 应用程序设置设置。 可以使用 Azure CLI 或在 Azure 门户中更新此设置。
有关 Node.js 版本的详细信息,请参阅受支持的版本。
在升级 Node.js 版本之前,请确保函数应用在最新版本的 Azure Functions 运行时上运行。 如果需要升级运行时版本,请参阅将应用从 Azure Functions 版本 3.x 迁移到版本 4.x。
运行 Azure CLI az functionapp config appsettings set 命令,更新在 Windows 上运行的函数应用的 Node.js 版本:
az functionapp config appsettings set --settings WEBSITE_NODE_DEFAULT_VERSION=~20 \
--name <FUNCTION_APP_NAME> --resource-group <RESOURCE_GROUP_NAME>
这会将 WEBSITE_NODE_DEFAULT_VERSION 应用程序设置设置为支持的 LTS 版本 ~20。
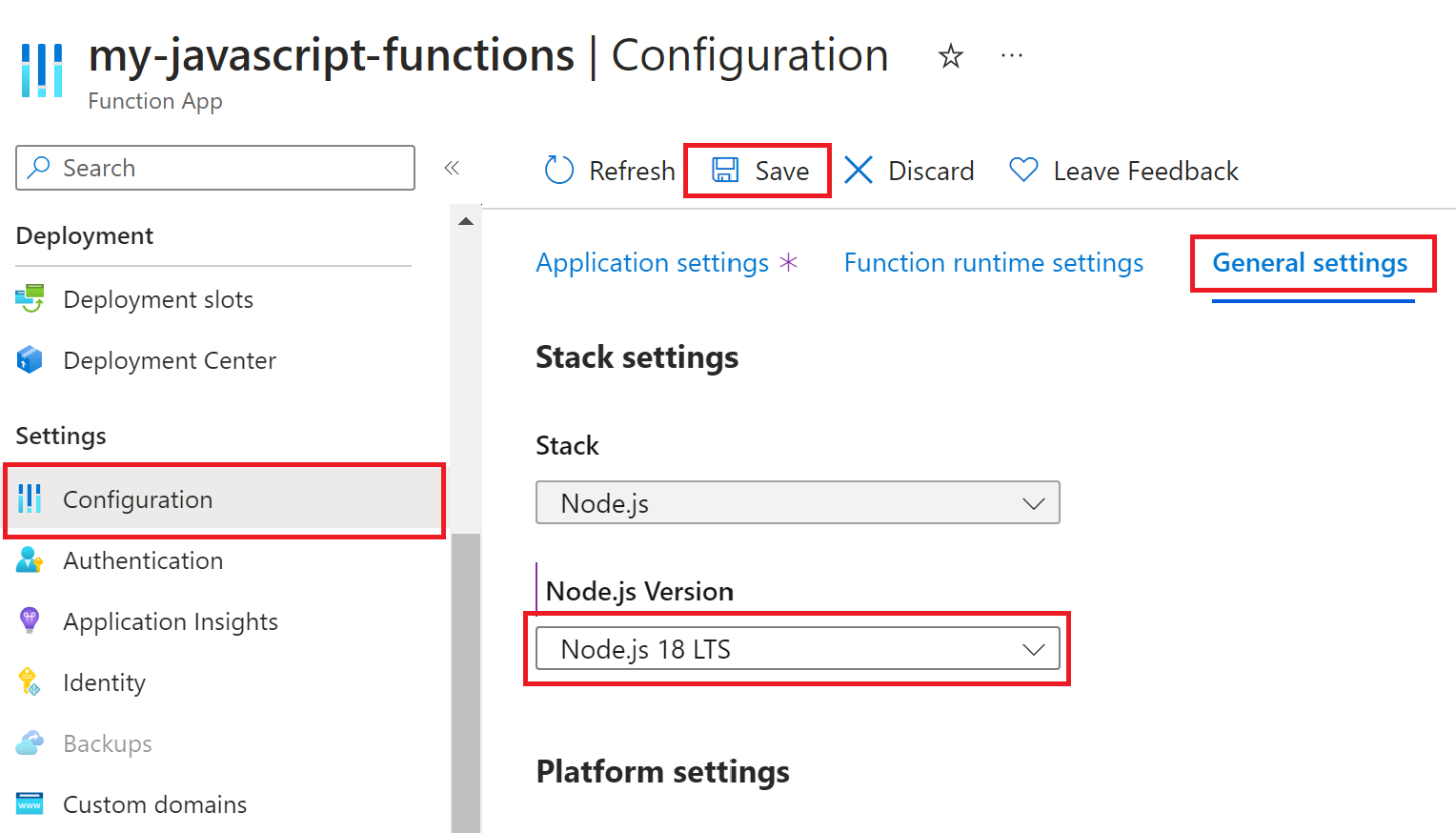
进行更改后,函数应用将重启。 若要详细了解 Functions 对 Node.js 的支持,请参阅语言运行时支持策略。
环境变量
环境变量可用于操作机密(连接字符串、键、终结点等)或环境设置(如分析变量)。 可以在本地和云环境中添加环境变量,并通过函数代码中的 process.env 访问它们。
以下示例记录 WEBSITE_SITE_NAME 环境变量:
module.exports = async function (context) {
context.log(`WEBSITE_SITE_NAME: ${process.env["WEBSITE_SITE_NAME"]}`);
}
async function timerTrigger1(myTimer, context) {
context.log(`WEBSITE_SITE_NAME: ${process.env["WEBSITE_SITE_NAME"]}`);
}
在本地开发环境中
在本地运行时,函数项目包括一个 local.settings.json 文件,你可以在该文件中将环境变量存储到 Values 对象中。
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "",
"FUNCTIONS_WORKER_RUNTIME": "node",
"CUSTOM_ENV_VAR_1": "hello",
"CUSTOM_ENV_VAR_2": "world"
}
}
在 Azure 云环境中
在 Azure 中运行时,函数应用支持设置和使用应用程序设置(例如服务连接字符串),并在执行期间将这些设置作为环境变量公开。
可以通过以下几种方法添加、更新和删除函数应用设置:
如果更改函数应用设置,则需要重启函数应用。
辅助角色环境变量
Node.js 有几个特定的函数环境变量:
languageWorkers__node__arguments
此设置允许在启动 Node.js 进程时指定自定义参数。 它最常用于在本地以调试模式启动工作程序,但如果需要自定义参数,也可以在 Azure 中使用。
警告
如果可能的话,避免在 Azure 中使用 languageWorkers__node__arguments,因为它可能会对冷启动时间产生负面影响。 运行时必须使用自定义参数从头开始启动新辅助角色,而不是使用预先预热的辅助角色。
logging__logLevel__Worker
此设置调整特定于 Node.js 的辅助角色日志的默认日志级别。 默认情况下,只显示警告或错误日志,但可以将其设置为 information 或 debug 以帮助诊断 Node.js 辅助角色的问题。 有关详细信息,请参阅配置日志级别。
ECMAScript 模块(预览)
注意
由于 ECMAScript 模块目前是 Azure Functions 中 Node.js 14 或更高版本的一项预览功能。
ECMAScript 模块(ES 模块)是 Node.js 的新官方标准模块系统。 到目前为止,本文中的代码示例使用 CommonJS 语法。 在 Node.js 14 或更高版本中运行 Azure Functions 时,可以选择使用 ES 模块语法编写函数。
若要在函数中使用 ES 模块,请将其文件名更改为使用 .mjs 扩展名。 下面的 index.mjs 文件示例是一个 HTTP 触发函数,它使用 ES 模块语法导入 库并返回值。
import { v4 as uuidv4 } from 'uuid';
async function httpTrigger1(context, request) {
context.res.body = uuidv4();
};
export default httpTrigger;
import { v4 as uuidv4 } from 'uuid';
async function httpTrigger1(request, context) {
return { body: uuidv4() };
};
app.http('httpTrigger1', {
methods: ['GET', 'POST'],
handler: httpTrigger1
});
配置函数入口点
function.json 属性 scriptFile 和 entryPoint 可用于配置导出函数的位置和名称。 使用 TypeScript 时,scriptFile 属性是必需的,应指向已编译的 JavaScript。
使用 scriptFile
默认情况下通过 index.js(与其对应的 function.json 共享相同父目录的文件)执行 JavaScript 函数。
scriptFile 可用于获取以下示例所示的文件夹结构:
<project_root>/
| - node_modules/
| - myFirstFunction/
| | - function.json
| - lib/
| | - sayHello.js
| - host.json
| - package.json
myFirstFunction 的 function.json 应包含 scriptFile 属性,该属性指向包含要运行的导出函数的文件。
{
"scriptFile": "../lib/sayHello.js",
"bindings": [
...
]
}
使用 entryPoint
在 v3 模型中,必须使用 module.exports 导出函数才能找到并运行它。 默认情况下,触发时执行的函数是该文件的唯一导出(导出名为 run 或 index)。 以下示例将 function.json 中的 entryPoint 设置为自定义值“logHello”:
{
"entryPoint": "logHello",
"bindings": [
...
]
}
async function logHello(context) {
context.log('Hello, world!');
}
module.exports = { logHello };
本地调试
建议使用 VS Code 进行本地调试,它会在调试模式下自动启动 Node.js 进程,并附加到该进程。 有关详细信息,请参阅在本地运行函数。
如果正在使用不同的工具进行调试,或者希望手动以调试模式启动 Node.js 进程,请在 local.settings.json 中的 Values 下添加 "languageWorkers__node__arguments": "--inspect"。 --inspect 参数告诉 Node.js 在默认情况下在端口 9229 上侦听调试客户端。 有关详细信息,请参阅 Node.js 调试指南。
建议
本节介绍了 Node.js 应用的几种有影响力的模式,建议遵循这些模式。
选择单 vCPU 应用服务计划
创建使用应用服务计划的函数应用时,建议选择单 vCPU 计划,而不是选择具有多个 vCPU 的计划。 目前,Functions 在单 vCPU VM 上运行 Node.js 函数更为高效;使用更大的 VM 不会产生预期的性能提高。 需要时,可以通过添加更多单 vCPU VM 实例来手动横向扩展,也可以启用自动缩放。 有关详细信息,请参阅手动或自动缩放实例计数。
从包文件运行
在无服务器托管模型中开发 Azure Functions 时,冷启动已成为现实。 冷启动是指在函数应用处于非活动状态一段时间后的首次启动,这会需要较长时间才能启动。 特别是对于具有大型依赖关系树的 Node.js 应用,冷启动可能非常重要。 为了加快冷启动过程,请尽量以包文件的形式运行函数。 许多部署方法默认使用此模型,但如果遇到大型冷启动,则应进行检查以确保以此方式运行。
使用单个静态客户端
在 Azure Functions 应用程序中使用特定于服务的客户端时,不要在每次函数调用时都创建新的客户端,因为可能会达到连接限制。 而是,应在全局范围内创建单个静态客户端。 有关详细信息,请参阅在 Azure Functions 中管理连接。
使用 async 和 await
在 Node.js 中编写 Azure Functions 时,应使用 async 和 await 关键字编写代码。 使用 async 和 await 编写代码,而不是使用回调或者结合约定使用 .then 和 .catch,将有助于避免两个常见问题:
- 引发未经捕获的异常,从而导致 Node.js 进程崩溃,并可能影响其他函数的执行。
- 未正确等待的异步调用导致的意外行为,例如
context.log中缺少日志。
以下示例使用了错误优先回调函数作为第二个参数调用异步方法 fs.readFile。 此代码会同时导致上述两个问题。 没有显式捕获到正确范围内的异常可能会导致整个进程崩溃(问题 #1)。 在不确保回调完成的情况下返回意味着 http 响应有时会有一个空正文(问题 #2)。
// DO NOT USE THIS CODE
const { app } = require('@azure/functions');
const fs = require('fs');
app.http('httpTriggerBadAsync', {
methods: ['GET', 'POST'],
authLevel: 'anonymous',
handler: async (request, context) => {
let fileData;
fs.readFile('./helloWorld.txt', (err, data) => {
if (err) {
context.error(err);
// BUG #1: This will result in an uncaught exception that crashes the entire process
throw err;
}
fileData = data;
});
// BUG #2: fileData is not guaranteed to be set before the invocation ends
return { body: fileData };
},
});
以下示例使用了错误优先回调函数作为第二个参数调用异步方法 fs.readFile。 此代码会同时导致上述两个问题。 没有显式捕获到正确范围内的异常可能会导致整个进程崩溃(问题 #1)。 在回调范围之外调用弃用的 context.done() 方法可以在读取文件之前发出函数完成的信号(问题 #2)。 在此示例中,过早调用 context.done() 导致缺少以 Data from file: 开头的日志条目。
// NOT RECOMMENDED PATTERN
const fs = require('fs');
module.exports = function (context) {
fs.readFile('./hello.txt', (err, data) => {
if (err) {
context.log.error('ERROR', err);
// BUG #1: This will result in an uncaught exception that crashes the entire process
throw err;
}
context.log(`Data from file: ${data}`);
// context.done() should be called here
});
// BUG #2: Data is not guaranteed to be read before the Azure Function's invocation ends
context.done();
}
使用 async 和 await 关键字可以帮助避免这两个问题。 Node.js 生态系统中的大多数 API 都已转换为以某种形式支持承诺。 例如,从 v14 开始,Node.js 提供 fs/promises API 来替换 fs 回调 API。
在以下示例中,在函数执行期间引发的任何未经处理的异常将仅导致引发异常的单个调用失败。 await 关键字表示 readFile 后续步骤只有在完成后才能执行。
// Recommended pattern
const { app } = require('@azure/functions');
const fs = require('fs/promises');
app.http('httpTriggerGoodAsync', {
methods: ['GET', 'POST'],
authLevel: 'anonymous',
handler: async (request, context) => {
try {
const fileData = await fs.readFile('./helloWorld.txt');
return { body: fileData };
} catch (err) {
context.error(err);
// This rethrown exception will only fail the individual invocation, instead of crashing the whole process
throw err;
}
},
});
此外,如果使用 async 和 await,则无需调用 context.done() 回调。
// Recommended pattern
const fs = require('fs/promises');
module.exports = async function (context) {
let data;
try {
data = await fs.readFile('./hello.txt');
} catch (err) {
context.log.error('ERROR', err);
// This rethrown exception will be handled by the Functions Runtime and will only fail the individual invocation
throw err;
}
context.log(`Data from file: ${data}`);
}
疑难解答
请参阅 Node.js 故障排除指南。
后续步骤
有关详细信息,请参阅以下资源: