Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:
 Azure CLI ml extension v1
Python SDK azureml v1
Azure CLI ml extension v1
Python SDK azureml v1
Learn how to deploy your machine learning or deep learning model as a web service in the Azure cloud.
Note
Azure Machine Learning Endpoints (v2) provide an improved, simpler deployment experience. Endpoints support both real-time and batch inference scenarios. Endpoints provide a unified interface to invoke and manage model deployments across compute types. See What are Azure Machine Learning endpoints?.
Workflow for deploying a model
The workflow is similar no matter where you deploy your model:
- Register the model.
- Prepare an entry script.
- Prepare an inference configuration.
- Deploy the model locally to ensure everything works.
- Choose a compute target.
- Deploy the model to the cloud.
- Test the resulting web service.
For more information on the concepts involved in the machine learning deployment workflow, see Manage, deploy, and monitor models with Azure Machine Learning.
Prerequisites
APPLIES TO:
Azure CLI ml extension v1
Important
The Azure CLI commands in this article require the azure-cli-ml, or v1, extension for Azure Machine Learning. Support for the v1 extension will end on September 30, 2025. You will be able to install and use the v1 extension until that date.
We recommend that you transition to the ml, or v2, extension before September 30, 2025. For more information on the v2 extension, see Azure ML CLI extension and Python SDK v2.
- An Azure Machine Learning workspace. For more information, see Create workspace resources.
- A model. The examples in this article use a pre-trained model.
- A machine that can run Docker, such as a compute instance.
Connect to your workspace
APPLIES TO:
Azure CLI ml extension v1
To see the workspaces that you have access to, use the following commands:
az login
az account set -s <subscription>
az ml workspace list --resource-group=<resource-group>
Register the model
A typical situation for a deployed machine learning service is that you need the following components:
- Resources representing the specific model that you want deployed (for example: a pytorch model file).
- Code that you will be running in the service, that executes the model on a given input.
Azure Machine Learnings allows you to separate the deployment into two separate components, so that you can keep the same code, but merely update the model. We define the mechanism by which you upload a model separately from your code as "registering the model".
When you register a model, we upload the model to the cloud (in your workspace's default storage account) and then mount it to the same compute where your webservice is running.
The following examples demonstrate how to register a model.
Important
You should use only models that you create or obtain from a trusted source. You should treat serialized models as code, because security vulnerabilities have been discovered in a number of popular formats. Also, models might be intentionally trained with malicious intent to provide biased or inaccurate output.
APPLIES TO:
Azure CLI ml extension v1
The following commands download a model and then register it with your Azure Machine Learning workspace:
wget https://aka.ms/bidaf-9-model -O model.onnx --show-progress
az ml model register -n bidaf_onnx \
-p ./model.onnx \
-g <resource-group> \
-w <workspace-name>
Set -p to the path of a folder or a file that you want to register.
For more information on az ml model register, see the reference documentation.
Register a model from an Azure ML training job
If you need to register a model that was created previously through an Azure Machine Learning training job, you can specify the experiment, run, and path to the model:
az ml model register -n bidaf_onnx --asset-path outputs/model.onnx --experiment-name myexperiment --run-id myrunid --tag area=qna
The --asset-path parameter refers to the cloud location of the model. In this example, the path of a single file is used. To include multiple files in the model registration, set --asset-path to the path of a folder that contains the files.
For more information on az ml model register, see the reference documentation.
Define a dummy entry script
The entry script receives data submitted to a deployed web service and passes it to the model. It then returns the model's response to the client. The script is specific to your model. The entry script must understand the data that the model expects and returns.
The two things you need to accomplish in your entry script are:
- Loading your model (using a function called
init()) - Running your model on input data (using a function called
run())
For your initial deployment, use a dummy entry script that prints the data it receives.
import json
def init():
print("This is init")
def run(data):
test = json.loads(data)
print(f"received data {test}")
return f"test is {test}"
Save this file as echo_score.py inside of a directory called source_dir. This dummy script returns the data you send to it, so it doesn't use the model. But it is useful for testing that the scoring script is running.
Define an inference configuration
An inference configuration describes the Docker container and files to use when initializing your web service. All of the files within your source directory, including subdirectories, will be zipped up and uploaded to the cloud when you deploy your web service.
The inference configuration below specifies that the machine learning deployment will use the file echo_score.py in the ./source_dir directory to process incoming requests and that it will use the Docker image with the Python packages specified in the project_environment environment.
You can use any Azure Machine Learning inference curated environments as the base Docker image when creating your project environment. We will install the required dependencies on top and store the resulting Docker image into the repository that is associated with your workspace.
Note
Azure machine learning inference source directory upload does not respect .gitignore or .amlignore
APPLIES TO:
Azure CLI ml extension v1
A minimal inference configuration can be written as:
{
"entryScript": "echo_score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "1"
}
}
Save this file with the name dummyinferenceconfig.json.
See this article for a more thorough discussion of inference configurations.
Define a deployment configuration
A deployment configuration specifies the amount of memory and cores your webservice needs in order to run. It also provides configuration details of the underlying webservice. For example, a deployment configuration lets you specify that your service needs 2 gigabytes of memory, 2 CPU cores, 1 GPU core, and that you want to enable autoscaling.
The options available for a deployment configuration differ depending on the compute target you choose. In a local deployment, all you can specify is which port your webservice will be served on.
APPLIES TO:
Azure CLI ml extension v1
The entries in the deploymentconfig.json document map to the parameters for LocalWebservice.deploy_configuration. The following table describes the mapping between the entities in the JSON document and the parameters for the method:
| JSON entity | Method parameter | Description |
|---|---|---|
computeType |
NA | The compute target. For local targets, the value must be local. |
port |
port |
The local port on which to expose the service's HTTP endpoint. |
This JSON is an example deployment configuration for use with the CLI:
{
"computeType": "local",
"port": 32267
}
Save this JSON as a file called deploymentconfig.json.
For more information, see the deployment schema.
Deploy your machine learning model
You are now ready to deploy your model.
APPLIES TO:
Azure CLI ml extension v1
Replace bidaf_onnx:1 with the name of your model and its version number.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic dummyinferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Call into your model
Let's check that your echo model deployed successfully. You should be able to do a simple liveness request, as well as a scoring request:
APPLIES TO:
Azure CLI ml extension v1
curl -v http://localhost:32267
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Define an entry script
Now it's time to actually load your model. First, modify your entry script:
import json
import numpy as np
import os
import onnxruntime
from nltk import word_tokenize
import nltk
def init():
nltk.download("punkt")
global sess
sess = onnxruntime.InferenceSession(
os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model.onnx")
)
def run(request):
print(request)
text = json.loads(request)
qw, qc = preprocess(text["query"])
cw, cc = preprocess(text["context"])
# Run inference
test = sess.run(
None,
{"query_word": qw, "query_char": qc, "context_word": cw, "context_char": cc},
)
start = np.asscalar(test[0])
end = np.asscalar(test[1])
ans = [w for w in cw[start : end + 1].reshape(-1)]
print(ans)
return ans
def preprocess(word):
tokens = word_tokenize(word)
# split into lower-case word tokens, in numpy array with shape of (seq, 1)
words = np.asarray([w.lower() for w in tokens]).reshape(-1, 1)
# split words into chars, in numpy array with shape of (seq, 1, 1, 16)
chars = [[c for c in t][:16] for t in tokens]
chars = [cs + [""] * (16 - len(cs)) for cs in chars]
chars = np.asarray(chars).reshape(-1, 1, 1, 16)
return words, chars
Save this file as score.py inside of source_dir.
Notice the use of the AZUREML_MODEL_DIR environment variable to locate your registered model. Now that you've added some pip packages.
APPLIES TO:
Azure CLI ml extension v1
{
"entryScript": "score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults",
"nltk",
"numpy",
"onnxruntime"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "2"
}
}
Save this file as inferenceconfig.json
Deploy again and call your service
Deploy your service again:
APPLIES TO:
Azure CLI ml extension v1
Replace bidaf_onnx:1 with the name of your model and its version number.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Then ensure you can send a post request to the service:
APPLIES TO:
Azure CLI ml extension v1
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Choose a compute target
The compute target you use to host your model will affect the cost and availability of your deployed endpoint. Use this table to choose an appropriate compute target.
| Compute target | Used for | GPU support | Description |
|---|---|---|---|
| Local web service | Testing/debugging | Use for limited testing and troubleshooting. Hardware acceleration depends on use of libraries in the local system. | |
| Azure Machine Learning endpoints (SDK/CLI v2 only) | Real-time inference Batch inference |
Yes | Fully managed computes for real-time (managed online endpoints) and batch scoring (batch endpoints) on serverless compute. |
| Azure Machine Learning Kubernetes | Real-time inference Batch inference |
Yes | Run inferencing workloads on on-premises, cloud, and edge Kubernetes clusters. |
| Azure Container Instances (SDK/CLI v1 only) | Real-time inference Recommended for dev/test purposes only. |
Use for low-scale CPU-based workloads that require less than 48 GB of RAM. Doesn't require you to manage a cluster. Supported in the designer. |
Note
When choosing a cluster SKU, first scale up and then scale out. Start with a machine that has 150% of the RAM your model requires, profile the result and find a machine that has the performance you need. Once you've learned that, increase the number of machines to fit your need for concurrent inference.
Note
Container instances require the SDK or CLI v1 and are suitable only for small models less than 1 GB in size.
Deploy to cloud
Once you've confirmed your service works locally and chosen a remote compute target, you are ready to deploy to the cloud.
Change your deploy configuration to correspond to the compute target you've chosen, in this case Azure Container Instances:
APPLIES TO:
Azure CLI ml extension v1
The options available for a deployment configuration differ depending on the compute target you choose.
{
"computeType": "aci",
"containerResourceRequirements":
{
"cpu": 0.5,
"memoryInGB": 1.0
},
"authEnabled": true,
"sslEnabled": false,
"appInsightsEnabled": false
}
Save this file as re-deploymentconfig.json.
For more information, see this reference.
Deploy your service again:
APPLIES TO:
Azure CLI ml extension v1
Replace bidaf_onnx:1 with the name of your model and its version number.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc re-deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
To view the service logs, use the following command:
az ml service get-logs -n myservice \
-g <resource-group> \
-w <workspace-name>
Call your remote webservice
When you deploy remotely, you may have key authentication enabled. The example below shows how to get your service key with Python in order to make an inference request.
import requests
import json
from azureml.core import Webservice
service = Webservice(workspace=ws, name="myservice")
scoring_uri = service.scoring_uri
# If the service is authenticated, set the key or token
key, _ = service.get_keys()
# Set the appropriate headers
headers = {"Content-Type": "application/json"}
headers["Authorization"] = f"Bearer {key}"
# Make the request and display the response and logs
data = {
"query": "What color is the fox",
"context": "The quick brown fox jumped over the lazy dog.",
}
data = json.dumps(data)
resp = requests.post(scoring_uri, data=data, headers=headers)
print(resp.text)
print(service.get_logs())
See the article on client applications to consume web services for more example clients in other languages.
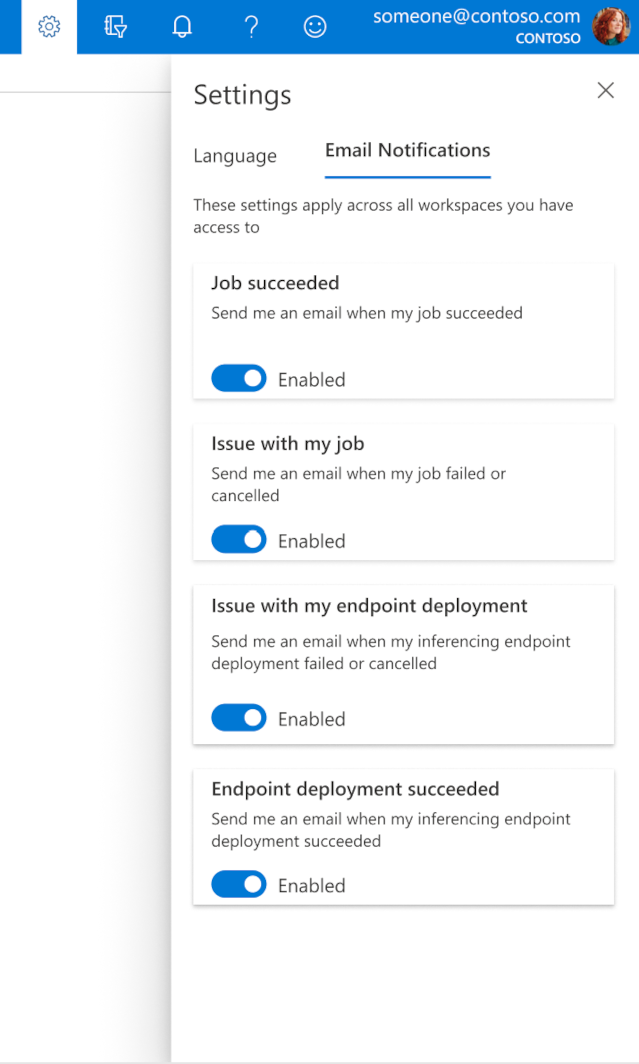
How to configure emails in the studio
To start receiving emails when your job, online endpoint, or batch endpoint is complete or if there's an issue (failed, canceled), use the following steps:
- In Azure ML studio, go to settings by selecting the gear icon.
- Select the Email notifications tab.
- Toggle to enable or disable email notifications for a specific event.
Understanding service state
During model deployment, you may see the service state change while it fully deploys.
The following table describes the different service states:
| Webservice state | Description | Final state? |
|---|---|---|
| Transitioning | The service is in the process of deployment. | No |
| Unhealthy | The service has deployed but is currently unreachable. | No |
| Unschedulable | The service cannot be deployed at this time due to lack of resources. | No |
| Failed | The service has failed to deploy due to an error or crash. | Yes |
| Healthy | The service is healthy and the endpoint is available. | Yes |
Tip
When deploying, Docker images for compute targets are built and loaded from Azure Container Registry (ACR). By default, Azure Machine Learning creates an ACR that uses the basic service tier. Changing the ACR for your workspace to standard or premium tier may reduce the time it takes to build and deploy images to your compute targets. For more information, see Azure Container Registry service tiers.
Note
If you are deploying a model to Azure Kubernetes Service (AKS), we advise you enable Azure Monitor for that cluster. This will help you understand overall cluster health and resource usage.
If you are trying to deploy a model to an unhealthy or overloaded cluster, it is expected to experience issues. If you need help troubleshooting AKS cluster problems please contact AKS Support.
Delete resources
APPLIES TO:
Azure CLI ml extension v1
# Get the current model id
import os
stream = os.popen(
'az ml model list --model-name=bidaf_onnx --latest --query "[0].id" -o tsv'
)
MODEL_ID = stream.read()[0:-1]
MODEL_ID
az ml service delete -n myservice
az ml service delete -n myaciservice
az ml model delete --model-id=<MODEL_ID>
To delete a deployed webservice, use az ml service delete <name of webservice>.
To delete a registered model from your workspace, use az ml model delete <model id>
Read more about deleting a webservice and deleting a model.
Next steps
- Troubleshoot a failed deployment
- Update web service
- One click deployment for automated ML runs in the Azure Machine Learning studio
- Use TLS to secure a web service through Azure Machine Learning
- Monitor your Azure Machine Learning models with Application Insights
- Create event alerts and triggers for model deployments