本文包含有关如何在专用 SQL 池中设计哈希分布式表和轮循机制分布式表的一些建议。
本文假定你熟悉专用 SQL 池中的数据分布和数据移动概念。 有关详细信息,请参阅 Azure Synapse Analytics 体系结构。
什么是分布式表?
分布式表显示为单个表,但表中的行实际存储在 60 个分布区中。 这些行使用哈希或轮循机制算法进行分布。
哈希分布可提高大型事实数据表的查询性能,本文会重点进行介绍。 轮循机制分布可用于提高加载速度。 这些设计选择对提高查询和加载性能具有重大影响。
另一个表存储选项是跨所有计算节点复制一个小型表。 有关详细信息,请参阅复制表的设计准则。 若要在这三个选项之间快速选择其一,请参阅表概述中的分布式表。
作为表设计的一部分,请尽可能多地去了解你的数据及其查询方式。 例如,请考虑以下问题:
- 表有多大?
- 表的刷新频率是多少?
- 专用 SQL 池中是否有事实数据表和维度表?
哈希分布
哈希分布表通过使用确定性的哈希函数将每一行分配给一个分布区,实现表行的跨计算节点分布。
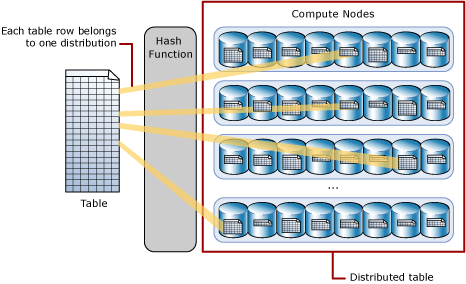
由于相同的值始终哈希处理到相同的分布区,因此,SQL Analytics 本身就具有行位置方面的信息。 可以在专用 SQL 池中根据此信息最大程度地减少查询期间的数据移动,提高查询性能。
哈希分布表适用于星型架构中的大型事实数据表。 它们可以包含大量行,但仍实现高性能。 你应该了解一些设计注意事项,它们有助于你获得分布式系统按设计应提供的性能。 本文所述的选择合适的分布列就是其中之一。
在以下情况下,考虑使用哈希分布表:
- 磁盘上的表大小超过 2 GB。
- 表具有频繁的插入、更新和删除操作。
轮循机制分布
轮循机制分布表将表行均衡分布在所有分布区中。 将行分配到分布区的过程是随机的。 与哈希分布表不同的是,值相等的行不一定分配到相同的分布区。
因此,系统有时候需要调用数据移动操作,以便在求解查询前更加合理地组织数据。 此附加步骤可能使查询变慢。 例如,联接轮循机制表通常需要对行重新进行数据重组,这会给性能带来影响。
在以下情况下,考虑对表使用轮循机制分布:
- 在最开始将其用作一个简单的起点,因为该分布是默认选项
- 没有明显的联接键时
- 没有合适的候选列对表进行哈希分布时
- 表没有与其他表共享通用的联接键时
- 该联接比查询中的其他联接更不重要时
- 表是临时过渡表时
教程加载纽约出租车数据提供了将数据加载到轮循机制临时表的示例。
选择分布列
哈希分布表中有一个分布列或一组列是哈希键。 例如,以下代码会创建一个以 ProductKey 作为分布列的哈希分布表。
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey])
);
可以对多列应用哈希分布,以便更均匀地分布基表。 利用多列分布,最多可以选择八列进行分布。 这不仅减少了一段时间内的数据倾斜,还提高了查询性能。 例如:
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey], [OrderDateKey], [CustomerKey] , [PromotionKey])
);
注意
通过使用此命令将数据库的兼容级别更改为 50,可以启用 Azure Synapse Analytics 中的多列分布。
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = 50; 有关设置数据库兼容性级别的详细信息,请参阅 ALTER DATABASE SCOPED CONFIGURATION。 有关多列分布的详细信息,请参阅 CREATE MATERIALIZED VIEW、CREATE TABLE 或 CREATE TABLE AS SELECT。
可以更新分布列中存储的数据。 对分布列中的数据进行更新可能导致数据无序操作。
选择分布列是一个重要的设计决策,因为此哈希列中的值确定行的分布方式。 最佳选择取决于多种因素,通常需要对各方面进行权衡。 选择分布列或列集后,将无法对其进行更改。 如果第一次未选择最合适的列,可以使用 CREATE TABLE AS SELECT (CTAS) 重新创建具有所需分布哈希键的表。
选择数据均衡分布的分布列
为了获得最佳性能,所有分布区都应当具有大致相同的行数。 当一个或多个分布区的行数不相称时,某些分布区会先于其他分布区完成其并行查询部分。 由于必须等到所有分布区都完成处理,才能完成查询,因此,每个查询的速度取决于最慢分布区的速度。
- 数据倾斜意味着数据未均衡分布在分布区中
- 处理倾斜意味着在运行并行查询时,某些分布区所用的时间比其他分布区长。 数据倾斜时可能会出现这种情况。
若要均衡并行处理,请选择符合以下条件的分布列或列集:
- 具有许多唯一值。 一个或多个分布列可能包含重复值。 具有相同值的所有行都会分配到同一分布区。 由于有 60 个分布区,因此一些分布区可能包含多个唯一值,而其他分布区可能以零值结尾。
- 没有 NULL 值,或者只有几个 NULL 值。 在极端示例中,如果分布列中的所有值均为 NULL,则所有行都将分配到相同的分布区。 因此,查询处理会向一个分布区倾斜,无法从并行处理中受益。
- 不是日期列。 同一日期的所有数据将位于同一分布区中,或将按日期对记录进行聚类。 如果几个用户都根据同一日期(例如今天的日期)进行筛选,那么 60 个分布区中只有 1 个执行所有处理工作。
选择能最大程度减少数据移动的分布列
为了获取正确的查询结果,查询可能将数据从一个计算节点移至另一个计算节点。 当查询对分布式表执行联接和聚合操作时,通常会发生数据移动。 选择一个能最大程度减少数据移动的分布列或列集,这是优化专用 SQL 池性能的最重要策略之一。
若要最大程度减少数据移动,请选择符合以下条件的分布列或列集:
- 用于
JOIN、GROUP BY、DISTINCT、OVER和HAVING子句。 当两个大型事实数据表频繁联接时,如果将这两个表分布在某个联接列上,查询性能将得到提升。 如果某个表不进行联接操作,则考虑将该表分布在经常出现在GROUP BY子句中的列或列集上。 - 不用于
WHERE子句。 当查询的WHERE子句和表的分配列在同一列上时,查询可能会遇到高数据偏斜,导致处理负载只落在少数分配上。 这会影响查询性能,理想情况下,许多分配应该共同承担处理负载。 - 不是日期列。
WHERE子句通常按日期进行筛选。 当这种情况发生时,所有处理都只能在影响查询性能的少数几个分配上运行。 理想情况下,许多分配应该共同承担处理负载。
完成哈希分布表的设计后,下一步就是将数据加载到表。 有关加载指南,请参阅加载概述。
如何判断分布区是否合适
将数据加载到哈希分布表之后,查看行在 60 个分布区中分布的均衡程度。 如果每个分布区的行数相差不超过 10%,性能不会受到明显影响。
请考虑通过以下方式来评估分布列。
确定表是否有数据倾斜现象
一种快速的数据倾斜检查方法是使用 DBCC PDW_SHOWSPACEUSED。 以下 SQL 代码返回 60 个分布区中每个分布区存储的表行数。 为了获得平衡的性能,分布式表中的行应该均衡分布在所有分布区中。
-- Find data skew for a distributed table
DBCC PDW_SHOWSPACEUSED('dbo.FactInternetSales');
若要确定哪些表的数据倾斜率超过 10%,请执行以下操作:
- 创建表概述一文所示的
dbo.vTableSizes视图。 - 运行以下查询:
select *
from dbo.vTableSizes
where two_part_name in
(
select two_part_name
from dbo.vTableSizes
where row_count > 0
group by two_part_name
having (max(row_count * 1.000) - min(row_count * 1.000))/max(row_count * 1.000) >= .10
)
order by two_part_name, row_count;
检查查询计划中是否有数据移动
合适的分布列集可最大程度减少联接和聚合操作中的数据移动。 这会影响联接的编写方式。 若要在联接两个哈希分布表时最大程度减少数据移动,联接列之一需要在分布列中。 当两个哈希分布表在一个数据类型相同的分布列上联接时,该联接不需要移动数据。 联接可以使用附加列,而不发生数据移动。
若要避免在联接过程中移动数据,应遵循以下做法:
- 参与联接的列的相关表必须哈希分布在一个联接列中。
- 两个表之间联接列的数据类型必须匹配。
- 必须使用 equals 运算符联接列。
- 联接类型不能是
CROSS JOIN。
若要了解查询是否正在移动数据,可以查看查询计划。
解决分布列问题
无需解决所有数据倾斜问题。 分布数据就是为了找出将数据倾斜降至最低与将数据移动降至最低两者之间的适当平衡。 因为现实中无法每次都做到将数据倾斜和数据移动同时降至最低。 有时,最少的数据移动带来的好处可能胜过数据倾斜造成的影响。
要确定是否应该解决表中的数据偏斜,应该尽可能了解工作负荷中的数据卷和查询。 可以按照查询监视一文中的步骤监视倾斜对查询性能的影响。 具体而言,就是了解在各个分布区上完成大型查询所需的时间。
由于不能更改现有表中的分布列,因此,解决数据倾斜的典型方法是重新创建具有不同分布列的表。
使用新的分布列集重新创建表
本示例使用 CREATE TABLE AS SELECT 重新创建具有不同哈希分布列的表。
首先使用 CREATE TABLE AS SELECT (CTAS) 创建具有新键的新表。 然后重新创建统计信息,最后通过重新命名表来交换表。
CREATE TABLE [dbo].[FactInternetSales_CustomerKey]
WITH ( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([CustomerKey])
, PARTITION ( [OrderDateKey] RANGE RIGHT FOR VALUES ( 20000101, 20010101, 20020101, 20030101
, 20040101, 20050101, 20060101, 20070101
, 20080101, 20090101, 20100101, 20110101
, 20120101, 20130101, 20140101, 20150101
, 20160101, 20170101, 20180101, 20190101
, 20200101, 20210101, 20220101, 20230101
, 20240101, 20250101, 20260101, 20270101
, 20280101, 20290101
)
)
)
AS
SELECT *
FROM [dbo].[FactInternetSales]
OPTION (LABEL = 'CTAS : FactInternetSales_CustomerKey')
;
--Create statistics on new table
CREATE STATISTICS [ProductKey] ON [FactInternetSales_CustomerKey] ([ProductKey]);
CREATE STATISTICS [OrderDateKey] ON [FactInternetSales_CustomerKey] ([OrderDateKey]);
CREATE STATISTICS [CustomerKey] ON [FactInternetSales_CustomerKey] ([CustomerKey]);
CREATE STATISTICS [PromotionKey] ON [FactInternetSales_CustomerKey] ([PromotionKey]);
CREATE STATISTICS [SalesOrderNumber] ON [FactInternetSales_CustomerKey] ([SalesOrderNumber]);
CREATE STATISTICS [OrderQuantity] ON [FactInternetSales_CustomerKey] ([OrderQuantity]);
CREATE STATISTICS [UnitPrice] ON [FactInternetSales_CustomerKey] ([UnitPrice]);
CREATE STATISTICS [SalesAmount] ON [FactInternetSales_CustomerKey] ([SalesAmount]);
--Rename the tables
RENAME OBJECT [dbo].[FactInternetSales] TO [FactInternetSales_ProductKey];
RENAME OBJECT [dbo].[FactInternetSales_CustomerKey] TO [FactInternetSales];
相关内容
若要创建分布式表,请使用以下语句之一: