在 Azure Synapse Analytics 中优化 Apache Spark 作业
了解如何为特定工作负荷优化 Apache Spark 群集配置。 最常面临的难题是内存压力,这归因于不正确的配置(尤其是大小不合的执行程序)、长时间运行的操作以及导致笛卡尔操作的任务。 可通过以下方式为作业提速:使用适当的缓存,并允许数据倾斜。 若要实现最佳性能,应监视和查看长时间运行并耗用资源的 Spark 作业执行。
以下部分介绍常用的 Spark 作业优化方法和建议。
选择数据抽象
早期的 Spark 版本使用 RDD 提取数据,Spark 1.3 和 1.6 分别引入了 DataFrame 和 DataSet。 请仔细衡量下列优缺点:
- DataFrame
- 大多数情况下的最佳选择。
- 通过 Catalyst 提供查询优化。
- 全阶段代码生成。
- 直接内存访问。
- 垃圾回收 (GC) 开销低。
- 不像数据集那样易于开发者使用,因为没有编译时检查或域对象编程。
- DataSet
- 适合可容忍性能受影响的复杂 ETL 管道。
- 不适合需要考虑性能受影响的聚合。
- 通过 Catalyst 提供查询优化。
- 提供域对象编程和编译时检查,适合开发。
- 增加序列化/反序列化开销。
- GC 开销高。
- 中断全阶段代码生成。
- RDD
- 不必使用 RDD,除非需要生成新的自定义 RDD。
- 不能通过 Catalyst 提供查询优化。
- 不提供全阶段代码生成。
- GC 开销高。
- 必须使用 Spark 1.x 旧版 API。
使用最佳数据格式
Spark 支持多种格式,比如 csv、json、xml、parquet、orc 和 avro。 Spark 可以借助外部数据源进行扩展,以支持更多格式 — 有关详细信息,请参阅 Apache Spark 包。
最能提高性能的格式是采用 Snappy 压缩的 Parquet,这是 Spark 2.x 中的默认格式。 Parquet 以分列格式存储数据,并在 Spark 中得到了高度优化。 此外,在进行 snappy 压缩时,可能会生成较大的文件(例如,比使用 gzip 压缩时生成的文件更大)。 由于这些文件具有可拆分特性,它们的解压缩速度会更快。
使用缓存
Spark 提供自己的本机缓存机制,可通过各种方法(比如 .persist()、.cache() 和 CACHE TABLE)使用。 这种本机缓存适用于小型数据集以及需要缓存中间结果的 ETL 管道。 但是,Spark 本机缓存目前并非很适用于分区,因为缓存表不保留分区数据。
有效利用内存
Spark 在运行时会将数据放在内存中,因此,管理内存资源是优化 Spark 作业执行的一个重要方面。 可通过以下几种方法来有效地利用群集内存。
为分区策略中的数据大小、类型和分布优先选择较小的数据分区和帐户。
在 Synapse Spark(运行时 3.1 或更高版本)中,通过默认的 Kryo 数据序列化功能启用 Kryo 数据序列化。
可以根据工作负荷要求使用 Spark 配置自定义 kryoserializer 缓冲区大小:
// Set the desired property spark.conf.set("spark.kryoserializer.buffer.max", "256m")监视和优化 Spark 配置设置。
下图展示了 Spark 内存结构和一些键执行程序内存参数供用户参考。
Spark 内存注意事项
Azure Synapse 中的 Apache Spark 使用 YARN (Apache Hadoop YARN)。YARN 控制每个 Spark 节点上的所有容器使用的最大内存总和。 下图展示了一些键对象及其关系。
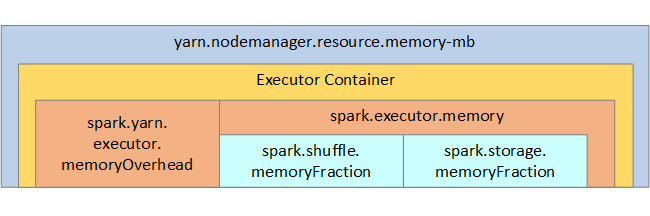
若要解决显示“内存不足”消息的问题,请尝试:
- 查看 DAG 管理数据重组。 通过映射端化简减少内存使用,对源数据进行预分区(或 Bucket 存储化),最大化单个数据重组,以及减少发送的数据量。
- 首选具有固定内存限制的
ReduceByKey,而不是GroupByKey,后者提供聚合、窗口化和其他功能,但内存不受限制。 - 首选在执行程序或分区上执行更多工作的
TreeReduce,而不是在驱动程序上执行所有工作的Reduce。 - 使用 DataFrame,而不是级别较低的 RDD 对象。
- 创建用于封装操作(比如“Top N”、各种聚合或窗口化操作)的 ComplexType。
优化数据序列化
Spark 作业是分布式作业,因此,适当的数据序列化对实现最佳性能很重要。 Spark 有两个序列化选项:
- Java 序列化
- Kryo 序列化是默认选项。 它是一种较新的格式,可带来比 Java 更快、更紧凑的序列化。 Kryo 要求在程序中注册类,并且尚不支持所有的可序列化类型。
使用 Bucket 存储
Bucket 存储类似于数据分区,但每个 Bucket 都可以保存一组列值,而不只是一个列值。 Bucket 存储适合对大量(数以百万计或更多)值分区,比如产品标识符。 通过哈希行的 Bucket 键可以确定 Bucket。 由 Bucket 存储的表可提供独一无二的优化,因为它们存储了有关其 Bucket 存储方式和排序方式的元数据。
下面是一些高级 Bucket 存储功能:
- 基于 Bucket 存储元信息的查询优化。
- 优化的聚合。
- 优化的联接。
可以同时使用分区和 Bucket 存储。
优化联接和数据重组
如果某个联接和数据重组操作上有速度较慢的作业,可能是由数据倾斜引起的,即作业数据不对称。 例如,运行映射作业可能需要 20 秒,但运行对数据进行联接或重组的作业则需数小时。 若要解决数据倾斜问题,应对整个键进行加盐加密,或对仅仅一部分键使用独立的加密盐。 如果使用独立的加密盐,应进一步进行筛选,将映射联接中已进行加盐加密的键的子集隔离出来。 另一种做法是引入 Bucket 列,先在 Bucket 中进行预聚合。
导致联接变慢的另一个因素可能是联接类型。 默认情况下,Spark 使用 SortMerge 联接类型。 这种联接最适合大型数据集,但另一方面又会占用大量计算资源,因为它必须先对数据的左右两侧进行排序,然后才进行合并。
Broadcast 联接最适合小型数据集,或者联接的一侧比另一侧小得多的情况。 这种联接会将一侧数据广播到所有执行程序,因此通常需要为广播提供更多内存。
可以通过设置 spark.sql.autoBroadcastJoinThreshold 来更改配置中的联接类型,也可以使用 DataFrame API (dataframe.join(broadcast(df2))) 来设置联接提示。
// Option 1
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 1*1024*1024*1024)
// Option 2
val df1 = spark.table("FactTableA")
val df2 = spark.table("dimMP")
df1.join(broadcast(df2), Seq("PK")).
createOrReplaceTempView("V_JOIN")
sql("SELECT col1, col2 FROM V_JOIN")
如果使用由 Bucket 存储的表,则有第三种联接类型,即 Merge 联接。 已进行正确预分区和预排序的数据集将跳过 SortMerge 联接中成本高昂的排序阶段。
联接的顺序至关重要,尤其是在较为复杂的查询中。 应先从最严格的联接开始。 此外,尽可能移动在聚合后增加行数的联接。
若要管理笛卡尔联接的并行度,可以添加嵌套结构,进行窗口化,以及在可能的情况下跳过 Spark 作业中的一个或多个步骤。
选择正确的执行程序大小
在决定执行程序配置时,请考虑 Java 垃圾回收 (GC) 开销。
通过以下方式减小执行程序大小:
- 将堆大小减至 32 GB 以下,使 GC 开销 < 10%。
- 减少内核数,使 GC 开销 < 10%。
通过以下方式增加执行程序大小:
- 减少执行程序之间的通信开销。
- 在较大的群集(> 100 个执行程序)上减少执行程序 (N2) 之间打开的连接数。
- 增加堆大小,以容纳占用大量内存的任务。
- 可选:减少每个执行程序的内存开销。
- 可选:通过超额订阅 CPU 来增加利用率和并发。
选择执行程序大小时,一般遵循以下做法:
- 最开始,每个执行程序 30 GB,并分发可用的计算机内核。
- 对于较大的群集(> 100 个执行程序),增加执行程序内核数。
- 基于试运行和上述因素(比如 GC 开销)修改大小。
运行并发查询时,考虑以下做法:
- 最开始,每个执行程序 30 GB,并分发所有计算机内核。
- 通过超额订阅 CPU,创建多个并行 Spark 应用程序(延迟缩短大约 30%)。
- 跨并行应用程序分布查询。
- 基于试运行和上述因素(比如 GC 开销)修改大小。
通过查看时间线视图、SQL 图、作业统计信息等等,监视查询性能中的离群值或其他性能问题。 有时,一个或几个执行程序的速度比其他执行程序要慢,执行任务时花费的时间也长得多。 这通常发生在较大的群集(> 30 个节点)上。 在这种情况下,应将工作划分成更多任务,以便计划程序可以补偿速度较慢的任务。
例如,任务数量应至少为应用程序中执行程序内核数的两倍。 也可以使用 conf: spark.speculation = true 对任务启用推理执行。
优化作业执行
- 根据需要进行缓存,例如,如果数据要使用两次,则缓存它。
- 将变量广播到所有执行程序。 只对变量执行一次序列化,以便加快查找速度。
- 使用驱动程序上的线程池,这会加快许多任务的操作速度。
Spark 2.x 查询性能的关键在于 Tungsten 引擎,这取决于全程代码生成。 在某些情况下,可能会禁用全程代码生成。
例如,如果在聚合表达式中使用非可变类型 (string),则会显示 SortAggregate,而不是 HashAggregate。 例如,为了提高性能,可尝试运行以下命令,然后重新启用代码生成:
MAX(AMOUNT) -> MAX(cast(AMOUNT as DOUBLE))
后续步骤
- 适用于 Apache Spark 的 Azure Synapse 运行时
- 优化 Apache Spark
- How to Actually Tune Your Apache Spark Jobs So They Work(如何真正优化 Apache Spark 作业以使其正常运行)
- Kryo 序列化