为方便在体验中查看受影响的资源,服务运行状况提供了一项新功能:
- 显示受计划内维护事件影响的资源。
- 通过服务运行状况门户提供计划内维护受影响的资源信息。
本文详细介绍向用户传达的内容,以及他们可以在何处查看有关其受影响资源的信息。
注意
此功能分阶段推出。 最初,仅针对 SQL 资源显示受影响的资源,并提供预先的通知客户和计算资源的重新启动更新。计划内维护受影响的资源覆盖范围会扩展到未来的其他资源类型和方案。
在服务运行状况门户中查看计划内维护事件受影响的资源
在 Azure 门户中,“服务运行状况”>“计划内维护”下的“受影响的资源”选项卡显示了受计划内维护事件影响的资源。 以下示例显示了具有受影响资源的计划内维护事件。
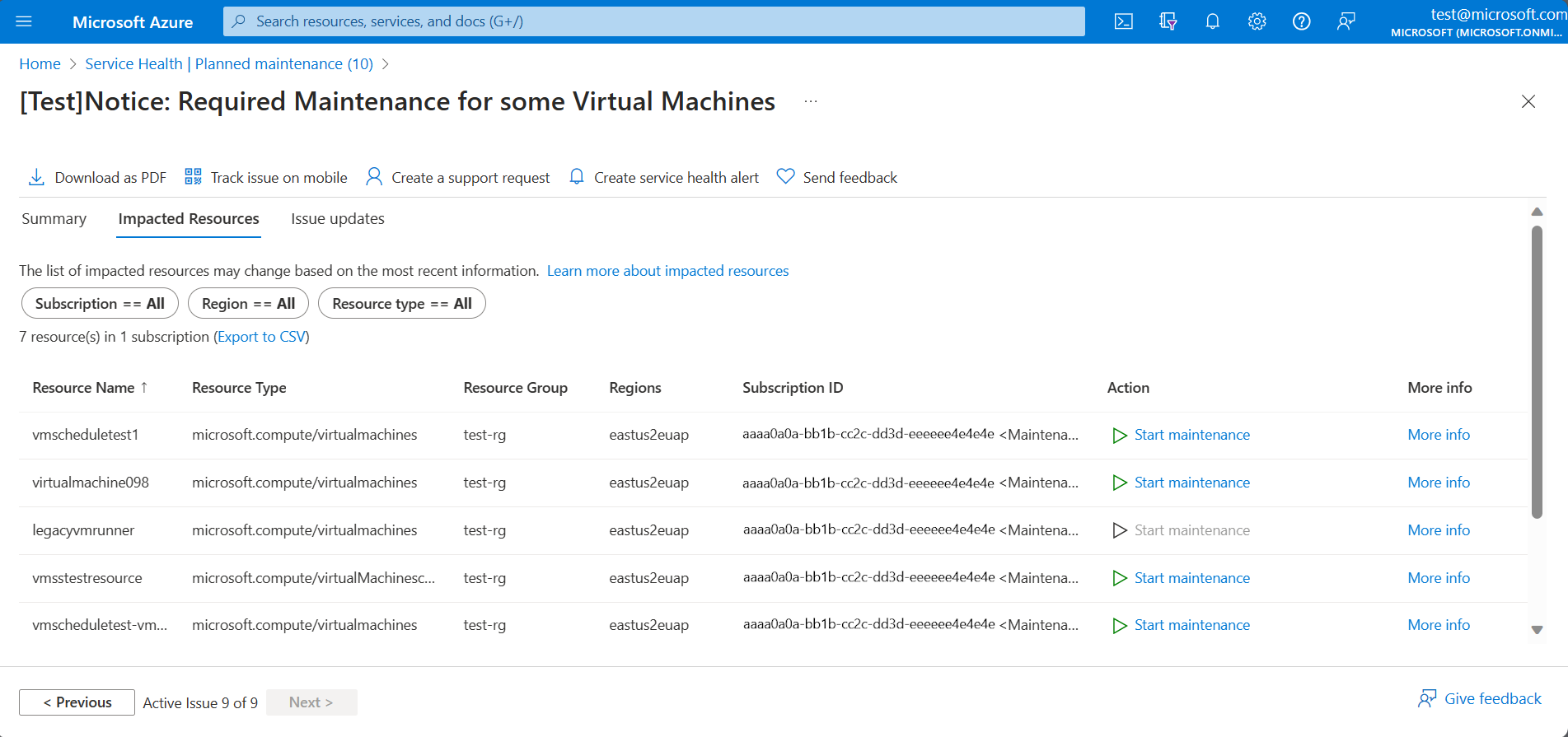
服务运行状况提供有关受计划内维护事件影响的资源的信息:
| 字段 | 说明 |
|---|---|
| 资源名称 | 受计划内维护事件影响的资源的名称。 |
| 资源类型 | 受计划内维护事件影响的资源类型。 |
| 资源组 | 包含受影响资源的资源组。 |
| 区域 | 包含受影响资源的区域。 |
| 订阅 ID | 包含受影响资源的订阅的唯一 ID。 |
| Action* | 在自助服务窗口中链接到“应用更新”页(仅适用于计算资源的重新启动更新)。 |
| 自助维护截止日期* | 自助服务窗口的截止日期,在此期间,用户可以应用更新(仅适用于计算资源的重新启动更新)。 |
注意
具有星号 * 的字段是可用的可选字段,具体取决于资源类型。
筛选器
客户可使用以下筛选器筛选结果:
- 区域
- 订阅 ID:用户有权访问的所有订阅 ID
- 资源类型:用户订阅下的所有资源类型
导出到 CSV
单击此选项可将受影响资源的列表导出到 Excel 文件。
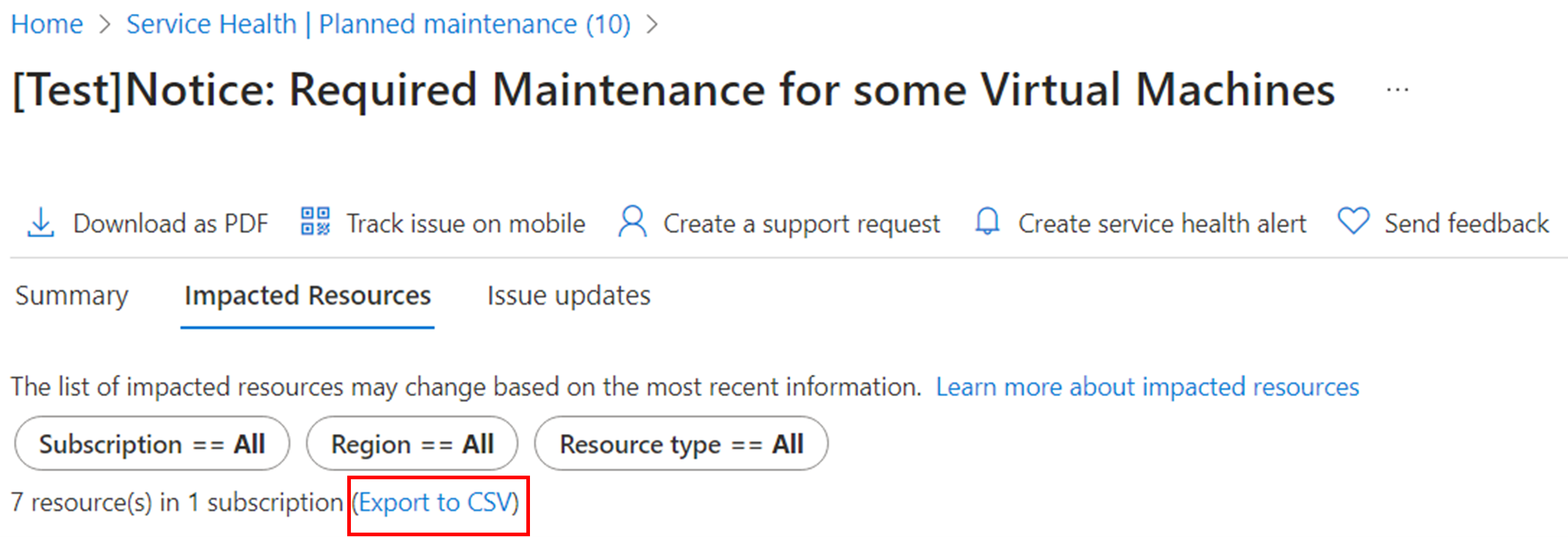
CSV 文件包括与每个事件关联的属性,以及每个事件级别的更多详细信息。 此 CSV 文件可用作“服务运行状况”>“计划内维护”视图中所有活动事件的静态时间点快照。 这些详细信息是通过服务运行状况 API 提供的更多事件级别信息的子集,该 API 可与事件网格或其他事件自动化解决方案集成。

下表包含每个 column 属性的简短说明。
| column 属性 | 说明 |
|---|---|
| 标题 | 已发布的事件的标题。 |
| TrackingId | 每个事件跨不同的服务运行状况类别唯一的标识符。 |
| 受影响的服务 | 适用于已发布的维护事件的一个或多个服务。 |
| 影响开始时间 | 事件的开始时间 (UTC)。 在通过更新通信共享的每个事件中,可以有较小的工作时段或时间范围。 |
| 影响结束时间 | 事件的结束时间 (UTC)。 在通过更新通信共享的每个事件中,可以有较小的工作时段或时间范围。 |
| 订阅 | 在已发布的事件范围内的一个或多个订阅 ID。 |
| 估计的影响持续时间* | 资源级别影响的估计时间(以秒为单位)。 事件时段可以用于更广泛的时间范围(例如几个小时,有时甚至几天)。 但是,此字段显示计划时段内估计的影响持续时间。 |
| 影响类型* | 预定义的影响类型,有助于在事件时段中根据观察服务或资源级别影响的方式对事件进行分类。 以下部分中有关于类别的更多详细信息。 |
| 建议 | 基于“影响类型”的用户步骤或建议操作。 |
注意
带星号 * 的字段是新引入的属性,对于某些服务来说可能为空,因为它们尚未采用新布局。
维护影响类型和影响持续时间字段
在我们使计划内维护通知对客户来说更可靠且更可预测的持续努力中,我们最近添加了 3 个新属性,特别是针对已发布事件的影响方面。 这些属性当前可通过 CSV 导出选项或服务运行状况 API 调用获得。
注意
我们正在支持更多服务在事件发布过程中包括这些字段,但有一些服务正在载入过程中,这些字段可能不会显示其事件的值。
对托管服务和最终用户的影响
“影响类型”新属性是回答这个常见问题的关键。 在跨 Azure 服务运行状况门户 UI 针对维护事件的其他增强功能中,最重要的新增功能是新的“影响类型”字段,通过它可快速了解在计划时段期间预期的假设性或总体影响。
我们目前有一组预定义的类别,它们涵盖或表示 Azure 服务中的不同影响症状。 根据产品设计,每项服务在影响方面都有独特的标准,因此可能会存在轻微的重叠。
下表更深入地展示“影响类型”属性的可能值。 描述列还显示了与行业标准术语(例如停电、欠压保护和灰视)的映射关系。
| 影响类型类别 | 说明 | 示例 |
|---|---|---|
| 服务可用性 | #Blackout、#Impactful#ServicePaused、#TempStorageLoss 资源或服务在短时间内处于暂停状态。 此类别下的事件可能会暂时影响总体资源可用性和/或用户连接。 |
网络:VM 可能断开网络连接且/或现有连接可能已终止。 计算 (VM):暂时暂停或冻结影响 VM 响应时间和连接的虚拟核心 (CPU)。 另一种常见的情况是在强制更新或主机运行状况下降期间进行服务修复。 存储:磁盘 IO 的完全或暂时暂停(例如驱动程序更新或存储代理更新)。 SQL:由于维护重新配置而对 SQL 数据库产生暂时影响,这会影响查询响应时间和短暂断开数据库连接。 长时间运行的查询可能会中断,并且可能需要重启。 |
| 性能降低 | #Brownout、#ModerateImpact、#Latency、#IntermittentTimeouts、#Slowness、#VMStatePreserved 每个服务或产品的症状可能有所不同。 对于某些应用(例如 SQL 应用),延迟或响应时间变慢对于正在执行的用户或查询来说可能更加明显。 资源通常已启动并运行,但功能降级或受限。 对于敏感工作负载更加明显。 |
网络:连接性明显下降,导致间歇性超时或断开连接。 访问磁盘驱动器时响应时间缓慢(例如,在更新期间,加速网络功能可能会暂停)。 间歇性数据包丢失。 计算 (VM):“实时迁移”活动。 应用程序或用户可能会观察到处理速度变慢。 另一种情况是 NIC 重置,可能观察到连接性能下降,持续最多 9 秒。 存储:磁盘 IOPS 可能性能下降。 SQL:DB 延迟请求在读取或写入操作中可能会遇到延迟或失败。 |
| 网络连接 | #Grayout、#ModerateImpact、#ConnectionTimeouts、#RetriesSucceed 当事件与网络堆栈相关时,审查对用户的影响。 影响持续时间较短,因为每个体系结构设计中内置了冗余层,这最大限度地减少了整体影响。 它们可能是针对与 T0、T1、NIC 或 NMAgent 升级和/或区域/地区性网络电缆和交换机相关的事件。 |
网络:现有连接继续运行,但无法建立新连接(例如,在 VFP 更新期间可能发生这种情况)。 一些 ToR(顶架)设备相关维护属于此类别。 |
| 资源不可用 | #Impactful、#Reboot、#Restart、#Redeploy、#Shutdown、#NoConnectivity、#Downtime 资源故障时间较长的事件(例如,VM 故障 > 30 秒)。 服务或资源可能不适用于用户和/或应用程序。 随着较新的平台设计创新,此类别中的事件频率大幅减少。 |
计算:VM 重启。 临时存储上的数据可能会丢失。 重启、重新部署、停止再启动 VM 等操作是此方案的常见示例。 启动 VM 的受控维护属于此类别,因为它构成重新部署。 |
| 数据可用性 | #Grayout、#Failover、#ModerateImpact、#ConnectionTimeouts、#QueryTimeouts、#RetriesSucceed 适用于 SQL 应用套件。 对用户的影响很小,仅在发生故障转移时才会看到。 |
SQL:维护事件可能产生单个或多个重新配置或故障转移,具体取决于维护事件开始时主要副本和次要副本的集合。 平均影响持续时间为几秒钟。 如果已连接,应用程序必须重新连接,并且长时间运行的查询可能会中断,甚至可能需要重启。 |
| 预期无影响 | #NoImpact、#Impactless | 没有明显的影响。 网络:一个例子是光纤电缆维护事件,这些事件再大多数情况下没有影响,除了在流量切换期间会有少量间歇性的数据包丢失,但重试会成功。 |
| 其他(请查看消息了解详细信息) | 如果这些类别都不直接适用,或者上述多个类别适用的,我们会在邮件内容中提供更多详细信息。 | 多个影响类别适用。 |
影响持续时间
“影响持续时间”字段将显示一个数值,表示事件会影响所列资源的时间(以秒为单位)。 根据服务复原能力和实现设计,此“持续时间”字段与“影响类型”字段相结合,有助于用户了解可能受到的整体影响程度。
要注意的一个关键方面是 StartTime/EndTime 事件与持续时间之间的差异。 虽然“开始/结束时间”等事件级别字段表示计划的工作时段,但“影响持续时间”字段表示该计划工作时段内的实际故障时间。