重要
SharePoint Online 索引器支持现为公共预览版。 它按照补充使用条款“按原样”提供,并且会尽力提供支持。 不建议将预览功能用于生产工作负荷,我们不保证会正式发布它们。
在开始之前,请务必访问已知限制部分。
若要使用此预览版,请填写此表单。 你不会立即收到任何审批通知,因为任何访问请求在提交后都会自动接受。 启用访问权限后,使用预览版 REST API 编制内容索引。
本文介绍如何配置搜索索引器,以便为 SharePoint 文档库中存储的文档编制索引,从而在 Azure AI 搜索中进行全文搜索。 首先执行配置步骤,后跟行为和方案
功能
Azure AI 搜索中的索引器是一种爬网程序,可从数据源中提取可搜索的数据和元数据。 SharePoint Online 索引器将连接到你的 SharePoint 网站,并为一个或多个文档库中的文档编制索引。 该索引器提供以下功能:
- 为一个或多个文档库中文件和元数据编制索引。
- 以增量方式编制索引,只选取新的和已更改的文件和元数据。
- 删除检测是内置功能。 在下一个索引器运行时,会选取文档库中的删除项,并从索引中移除该文档。
- 默认情况下,将从已编制索引的文档中提取文本和规范化图像。 (可选)可以添加技能集,以便进行更深入的 AI 扩充,例如 OCR 或文本翻译。
先决条件
文档库中的文件
支持的文档格式
SharePoint Online 索引器可以使用以下文档格式提取文本:
- CSV(请参阅为 CSV Blob 编制索引)
- EML
- EPUB
- GZ
- HTML
- JSON(请参阅为 JSON blob 编制索引)
- KML(用于地理表示形式的 XML)
- Microsoft Office 格式:DOCX/DOC/DOCM、XLSX/XLS/XLSM、PPTX/PPT/PPTM、MSG(Outlook 电子邮件)、XML(2003 和 2006 Word XML)
- 公开文档格式:ODT、ODS、ODP
- 纯文本文件(另请参阅为纯文本编制索引)
- RTF
- XML
- ZIP
限制和注意事项
下面是此功能的限制:
不支持为 SharePoint 列表编制索引。
不支持为 SharePoint .ASPX 站点内容编制索引。
不支持 OneNote 笔记本文件。
不支持专用终结点。
重命名 SharePoint 文件夹不会触发增量索引。 重命名的文件夹会被视为新内容。
SharePoint 支持一种精细授权模型,它可以确定每个用户在文档级别的访问权限。 索引器不会将这些权限拉取到索引中,并且 Azure AI 搜索不支持文档级授权。 将 SharePoint 中的某文档索引到搜索服务后,对该索引具有读取访问权限的任何人员都可使用该内容。 如果需要文档级权限,应考虑使用安全筛选器来剪裁结果,并自动将文件级的权限复制到索引中的字段。
不支持为用户加密文件、受信息权限管理 (IRM) 保护的文件、具有密码或类似加密内容的 ZIP 文件编制索引。 若要处理加密内容,具有特定文件适当权限的用户必须删除加密,这样才能在索引器运行下一次计划迭代时相应地对项编制索引。
不支持从提供的特定网站以递归方式为子站点编制索引。
启用 Microsoft Entra ID 条件访问后,不支持 SharePoint Online 索引器。
以下是使用此功能时的注意事项:
- 如果在生产环境中需要 SharePoint 内容索引解决方案,请考虑使用 SharePoint Webhook 创建自定义连接器,从而调用 Microsoft Graph API 来将数据导出到 Azure Blob 容器,然后使用 Azure Blob 索引器进行增量索引编制。
- 如果 SharePoint 配置支持 Microsoft 365 进程更新 SharePoint 文件系统元数据,请注意,这些更新可以触发 SharePoint Online 索引器,从而导致索引器多次引入文档。 由于 SharePoint Online 索引器是连接到 Azure 的第三方连接器,因此该索引器无法读取配置或更改其行为。 无论这些更新如何进行,它都会响应新内容和已更改内容中的更改。 因此,请在使用索引器和任何 AI 扩充之前确保测试设置并了解文档处理计数。
配置 SharePoint Online 索引器
若要设置 SharePoint Online 索引器,请使用 Azure 门户和预览版 REST API。 你可以使用 2020-06-30-preview 或更高版本。 建议使用最新的预览版 API。
本部分提供了步骤。 也可以观看以下视频。
步骤 1(可选):启用系统分配的托管标识
启用系统分配的托管标识,以自动检测预配搜索服务的租户。
如果 SharePoint 网站与搜索服务位于同一租户中,请执行此步骤。 如果 SharePoint 网站位于其他租户中,请跳过此步骤。 标识不用于索引,而仅用于租户检测。 如果要将租户 ID 放在连接字符串中,也可以跳过此步骤。
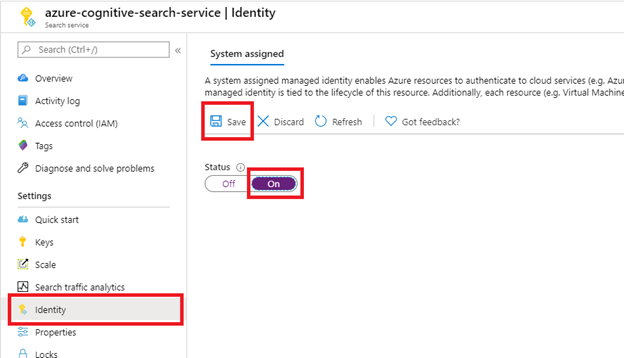
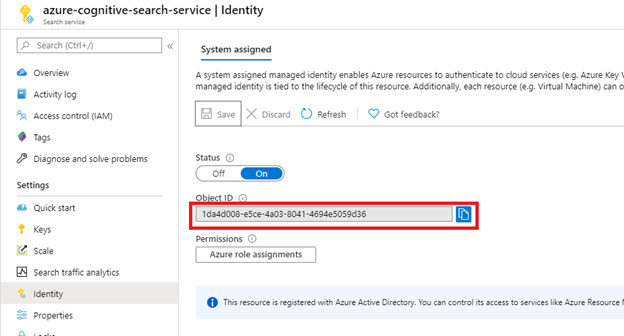
选择“保存”后,你会看到已分配给搜索服务的对象 ID。
步骤 2:确定索引器需要哪些权限
SharePoint Online 索引器支持委派和应用程序权限。 根据方案选择要使用的权限。
建议选择基于应用的权限。 请参阅限制,以了解与委托的权限有关的已知问题。
应用程序权限(建议选择),其中索引器以可以访问所有站点和文件的 SharePoint 租户身份运行,。 索引器需要使用客户端密码。 索引器还需要租户管理员批准,然后才能为任何内容编制索引。
委托的权限,索引器以发送请求的用户或应用的标识运行。 数据访问仅限于调用方有权访问的站点和文件。 为了支持委托的权限,索引器需要设备代码提示来代表用户登录。 根据用于实现此身份验证类型的最新安全库,用户委托的权限每 75 分钟强制实施一次令牌过期。 此行为不可调整。 过期的令牌需要使用运行索引器(预览版)手动编制索引。 出于此原因,你可能转而需要将基于应用的权限。
步骤 3:创建 Microsoft Entra 应用程序注册
SharePoint Online 索引器将使用此 Microsoft Entra 应用程序进行身份验证。
登录 Azure 门户。
搜索或导航到“Microsoft Entra ID”,然后选择“应用注册”。
选择“+ 新建注册”:
- 为应用提供一个名称。
- 选择“单个租户”。
- 跳过 URI 指定步骤。 无需重定向 URI。
- 选择“注册”。
在左侧,依次选择“API 权限”、“添加权限”和“Microsoft Graph” 。
如果索引器使用应用程序 API 权限,则选择“应用程序权限”并添加以下内容:
- 应用程序 - Files.Read.All
- 应用程序 - Sites.Read.All

使用应用程序权限意味着索引器将在服务上下文中访问 SharePoint 网站。 因此,当你运行索引器时,它将有权访问 SharePoint 租户中的所有内容,这需要租户管理员批准。 身份验证还需要客户端密码。 本文稍后将介绍设置客户端机密。
如果索引器使用的是委托的 API 权限,请选择“委托的权限”,并添加以下内容:
- 委托 - Files.Read.All
- 委托 - Sites.Read.All
- 委托 - User.Read
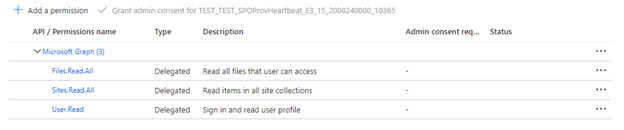
搜索客户端可以使用委托的权限以当前用户的安全标识连接到 SharePoint。
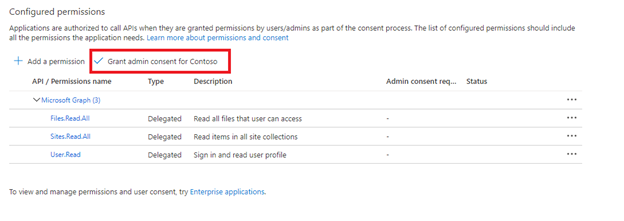
让管理员同意。
使用应用程序 API 权限时需要租户管理员同意。 某些租户被锁定,需要租户管理员同意才能获取委托 API 权限。 如果出现上述任何一种情况,则需要先获得租户管理员对此 Microsoft Entra 应用程序的同意,然后再创建索引器。
选择“身份验证”选项卡。
将“允许公共客户端流”设置为“是”,然后选择“保存” 。
依次选择“+添加平台”和“移动和桌面应用程序”,选中
https://login.chinacloudapi.cn/common/oauth2/nativeclient,然后选择“配置” 。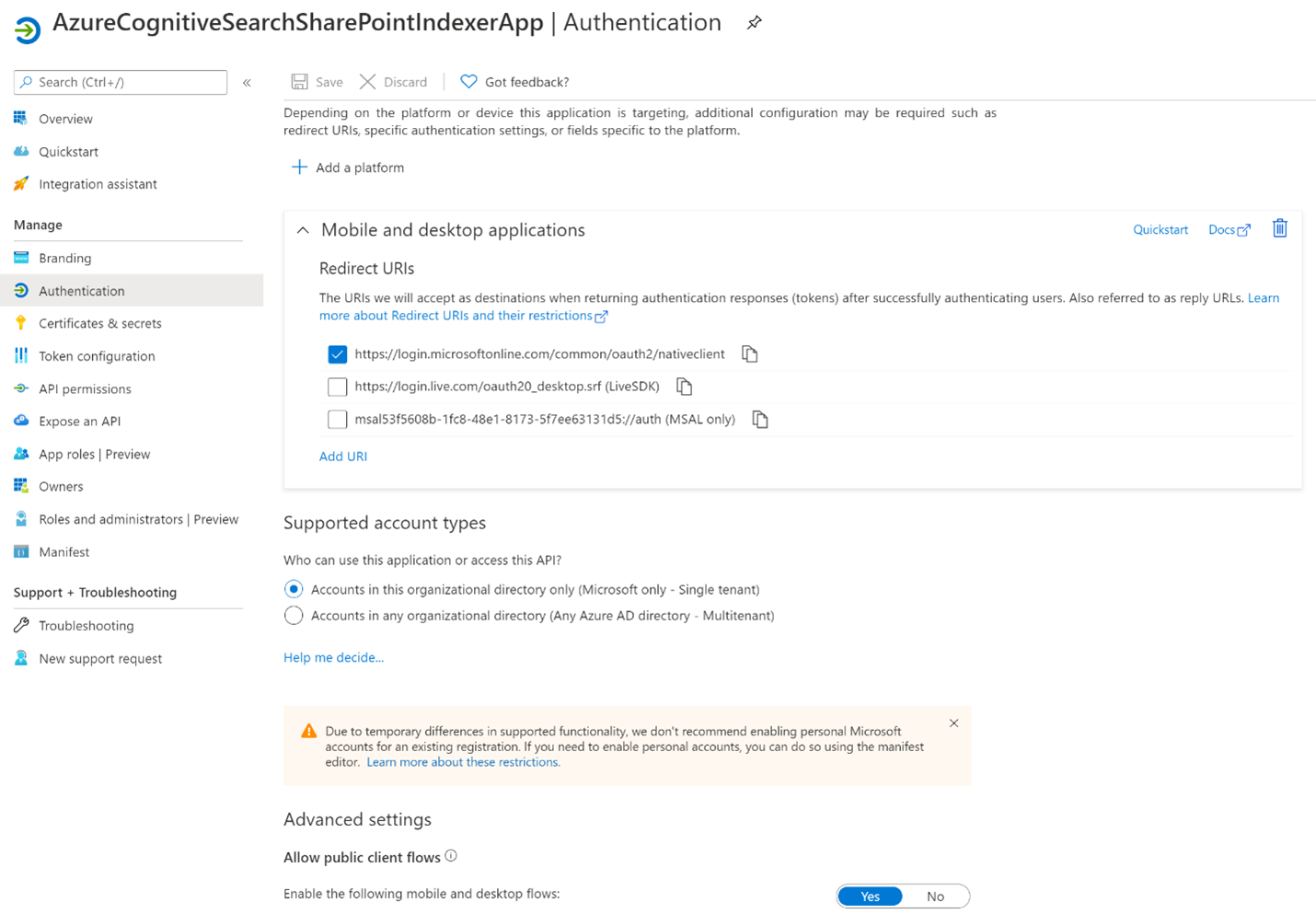
(仅限应用程序 API 权限)若要使用应用程序权限向 Microsoft Entra 应用程序进行身份验证,索引器需要客户端密码。
从左侧菜单中选择“证书和密码”,然后选择“客户端密码”和“新建客户端密码”。

在弹出的菜单中,输入新客户端密码的描述。 如有必要,请调整期日期。 如果密码过期,则需要重新创建该机密,并且需要使用新机密更新索引器。
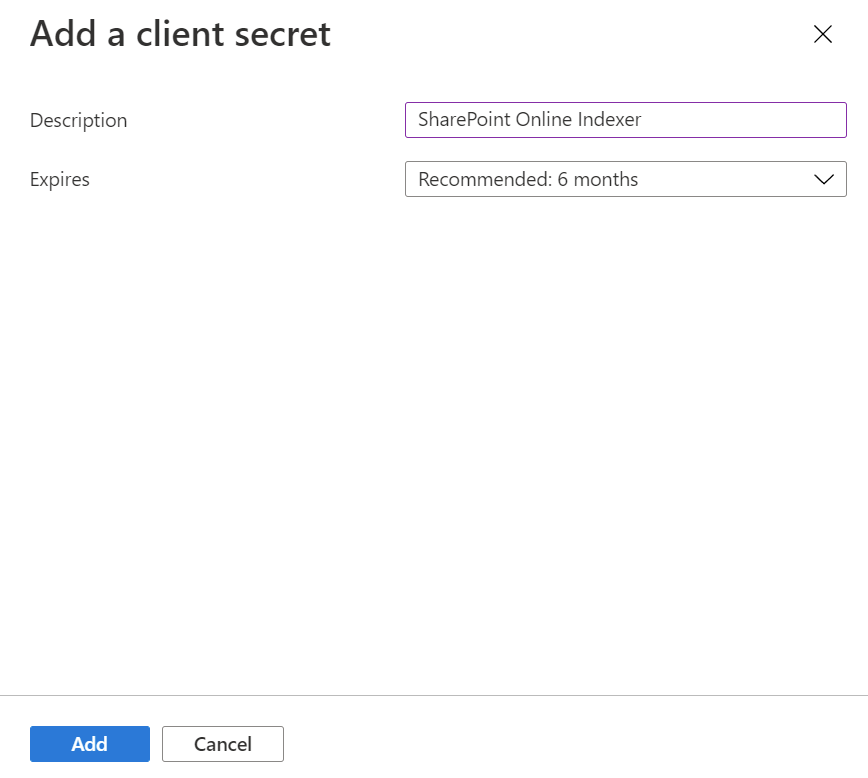
新的客户端密码将显示在机密列表中。 导航离开页面后,机密将不再可见,因此请使用“复制”按钮复制该机密并将其保存在安全位置。

步骤 4:创建数据源
从此部分开始,请使用预览版 REST API 执行其余步骤。 建议使用最新的预览版 API。
数据源指定要编制索引的数据、凭据和策略,以高效标识数据更改(新建行、已修改行或已删除行)。 一个数据源可供同一搜索服务中的多个索引器使用。
对于 SharePoint 索引,数据源必须具有以下属性:
- name 是搜索服务中数据源的唯一名称。
- type 必须为“sharepoint”。 此值区分大小写。
-
credentials 提供 SharePoint 终结点和 Microsoft Entra 应用程序(客户端)ID。
https://microsoft.sharepoint.com/teams/MySharePointSite就是一个 SharePoint 终结点。 可导航到 SharePoint 站点的主页,并从浏览器复制 URL 来获取终结点。 - container 指定要索引的文档库。 属性可控制为哪些文档编制索引。
要创建数据源,请调用创建数据源(预览版)。
POST https://[service name].search.azure.cn/datasources?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"name" : "sharepoint-datasource",
"type" : "sharepoint",
"credentials" : { "connectionString" : "[connection-string]" },
"container" : { "name" : "defaultSiteLibrary", "query" : null }
}
连接字符串格式
连接字符串的格式会根据索引器是使用委派的 API 权限还是应用程序 API 权限而变化
委派 API 权限连接字符串格式
SharePointOnlineEndpoint=[SharePoint site url];ApplicationId=[Azure AD App ID];TenantId=[SharePoint site tenant id]应用程序 API 权限连接字符串格式
SharePointOnlineEndpoint=[SharePoint site url];ApplicationId=[Azure AD App ID];ApplicationSecret=[Azure AD App client secret];TenantId=[SharePoint site tenant id]
注意
如果 SharePoint 站点与搜索服务位于同一租户中,并且启用了系统分配的托管标识,则无需将 TenantId 包含在连接字符串中。 如果 SharePoint 站点与搜索服务位于不同的租户中,则必须包含 TenantId。
步骤 5:创建索引
索引指定文档、属性和其他构造中可以塑造搜索体验的字段。
要创建索引,请调用创建索引(预览版):
POST https://[service name].search.azure.cn/indexes?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"name" : "sharepoint-index",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "metadata_spo_item_name", "type": "Edm.String", "key": false, "searchable": true, "filterable": false, "sortable": false, "facetable": false },
{ "name": "metadata_spo_item_path", "type": "Edm.String", "key": false, "searchable": false, "filterable": false, "sortable": false, "facetable": false },
{ "name": "metadata_spo_item_content_type", "type": "Edm.String", "key": false, "searchable": false, "filterable": true, "sortable": false, "facetable": true },
{ "name": "metadata_spo_item_last_modified", "type": "Edm.DateTimeOffset", "key": false, "searchable": false, "filterable": false, "sortable": true, "facetable": false },
{ "name": "metadata_spo_item_size", "type": "Edm.Int64", "key": false, "searchable": false, "filterable": false, "sortable": false, "facetable": false },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "sortable": false, "facetable": false }
]
}
重要
只有 metadata_spo_site_library_item_id 可以充当由 SharePoint Online 索引器填充的索引中的键字段。 如果数据源中不存在某个键字段,metadata_spo_site_library_item_id 会自动映射到该键字段。
步骤 6:创建索引器
索引器将数据源与目标搜索索引关联,并提供自动执行数据刷新的计划。 创建索引和数据源后,可以创建索引器。
如果使用委托的权限,在执行此步骤期间,系统会要求你使用有权访问 SharePoint 网站的组织凭据登录。 如果可能,建议创建新的组织用户帐户,并为该新用户提供希望索引器具有的确切权限。
创建索引器需要几步操作:
发送创建索引器(预览版)请求:
POST https://[service name].search.azure.cn/indexers?api-version=2024-05-01-preview Content-Type: application/json api-key: [admin key] { "name" : "sharepoint-indexer", "dataSourceName" : "sharepoint-datasource", "targetIndexName" : "sharepoint-index", "parameters": { "batchSize": null, "maxFailedItems": null, "maxFailedItemsPerBatch": null, "base64EncodeKeys": null, "configuration": { "indexedFileNameExtensions" : ".pdf, .docx", "excludedFileNameExtensions" : ".png, .jpg", "dataToExtract": "contentAndMetadata" } }, "schedule" : { }, "fieldMappings" : [ { "sourceFieldName" : "metadata_spo_site_library_item_id", "targetFieldName" : "id", "mappingFunction" : { "name" : "base64Encode" } } ] }如果使用应用程序权限,则必须先等待初始运行完成,然后再开始查询索引。 此步骤中提供的以下说明是针对委托权限的,不适用于应用程序权限。
首次创建索引器时,创建索引器(预览版)请求会等待你完成下一步。 必须调用获取索引器状态以获取链接,然后输入新的设备代码。
GET https://[service name].search.azure.cn/indexers/sharepoint-indexer/status?api-version=2024-05-01-preview Content-Type: application/json api-key: [admin key]从获取索引器状态响应复制设备登录代码。 可以在“errorMessage”中找到设备登录名。
{ "lastResult": { "status": "transientFailure", "errorMessage": "To sign in, use a web browser to open the page https://microsoft.com/deviceloginchina and enter the code <CODE> to authenticate." } }提供错误消息中包含的代码。
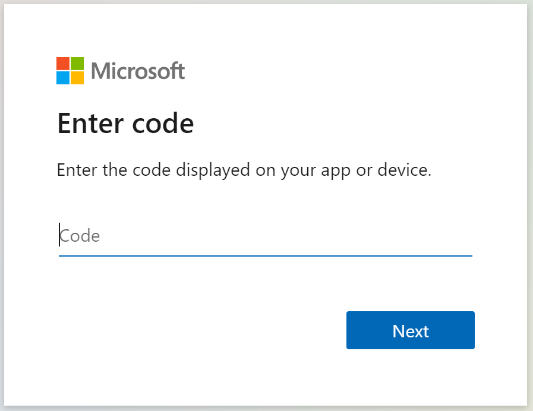
SharePoint Online 索引器将以已登录用户的身份访问 SharePoint 内容。 在该步骤中登录的用户就是该登录用户。 因此,如果登录时使用的用户帐户无权访问文档库中你想要索引的文档,那么索引器将无法访问该文档。
如果可能,建议创建新的用户帐户,并为该新用户提供希望索引器具有的确切权限。
批准所请求的权限。
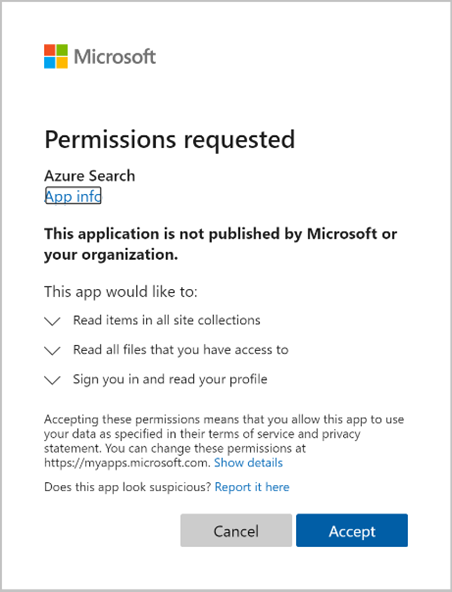
如果上面提供的所有权限正确无误且在 10 分钟时间范围内,则创建索引器(预览版)初始请求将会完成。
注意
如果 Microsoft Entra 应用程序需要管理员批准,并且未在登录之前获得批准,你可能会看到以下屏幕。 需要管理员批准才能继续。
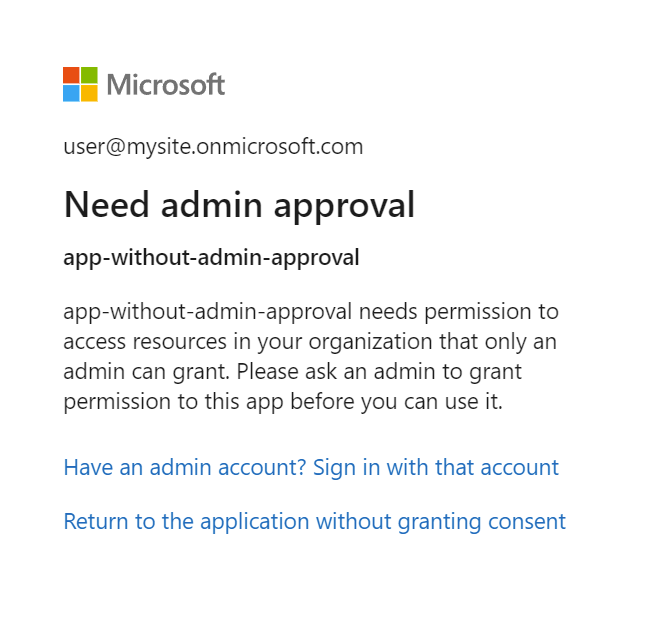
步骤 7:检查索引器状态
创建索引器后,可以调用获取索引器状态:
GET https://[service name].search.azure.cn/indexers/sharepoint-indexer/status?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
更新数据源
如果数据源对象没有更新,则索引器会按计划运行,而无需任何用户交互。
但如果在设备代码过期时修改了数据源对象,则必须再次登录才能运行索引器。 例如,如果更改数据源查询,则需要使用 https://microsoft.com/deviceloginchina 重新登录并获取新的设备代码。
下面是更新数据源的步骤,假设设备代码已过期:
调用运行索引器(预览版)以手动启动索引器执行。
POST https://[service name].search.azure.cn/indexers/sharepoint-indexer/run?api-version=2024-05-01-preview Content-Type: application/json api-key: [admin key]检查索引器状态。
GET https://[service name].search.azure.cn/indexers/sharepoint-indexer/status?api-version=2024-05-01-preview Content-Type: application/json api-key: [admin key]如果收到要求访问
https://microsoft.com/deviceloginchina的错误,请打开页面并复制新代码。将代码粘贴到对话框中。
再次手动运行索引器并检查索引器状态。 此时,索引器运行应会成功启动。
索引文档元数据
如果要为文档元数据编制索引("dataToExtract": "contentAndMetadata"),可使用以下元数据。
| Identifier | 类型 | 说明 |
|---|---|---|
| metadata_spo_site_library_item_id | Edm.String | 网站 ID、库 ID 和项 ID 的组合键,用于唯一标识站点文档库中的项。 |
| metadata_spo_site_id | Edm.String | SharePoint 站点的 ID。 |
| metadata_spo_library_id | Edm.String | 文档库的 ID。 |
| metadata_spo_item_id | Edm.String | 库中(文档)项的 ID。 |
| metadata_spo_item_last_modified | Edm.DateTimeOffset | 项的最后修改日期/时间 (UTC)。 |
| metadata_spo_item_name | Edm.String | 项的名称。 |
| metadata_spo_item_size | Edm.Int64 | 项的大小(以字节为单位)。 |
| metadata_spo_item_content_type | Edm.String | 项的内容类型。 |
| metadata_spo_item_extension | Edm.String | 项的扩展名。 |
| metadata_spo_item_weburi | Edm.String | 项的 URI。 |
| metadata_spo_item_path | Edm.String | 父路径和项名称的组合。 |
SharePoint Online 索引器还支持每种文档类型特定的元数据。 有关详细信息,可查看 Azure AI 搜索中使用的内容元数据属性。
注意
若要为自定义元数据编制索引,必须在数据源的查询参数中指定“additionalColumns”。
包含或排除文件类型
可以通过在索引器定义的“参数”部分设置包含和排除条件来控制要索引哪些文件。
通过将 "indexedFileNameExtensions" 设置为文件扩展名(包括前置句点)逗号分隔列表来包含特定的文件扩展名。 通过将 "excludedFileNameExtensions" 设置为应跳过的扩展名来排除特定的文件扩展名。 如果两个列表中存在同一个扩展名,则将其从索引编制中排除。
PUT /indexers/[indexer name]?api-version=2024-05-01-preview
{
"parameters" : {
"configuration" : {
"indexedFileNameExtensions" : ".pdf, .docx",
"excludedFileNameExtensions" : ".png, .jpeg"
}
}
}
控制要索引哪些文档
一个 SharePoint Online 索引器可从一个或多个文档库中索引内容。 使用数据源定义中的“container”参数来指示要从中进行索引的站点和文档库。
数据源“容器”部分具有用于此任务的两个属性:“name”和“query”。
名称
“name”属性是必需的,并且必须是以下三个值之一:
| 值 | 说明 |
|---|---|
| defaultSiteLibrary | 从站点默认文档库中索引所有内容。 |
| allSiteLibraries | 从站点的所有文档库中索引所有内容。 子站点中的文档库超出范围/如果需要子网站中的内容,请选择“useQuery”并指定“includeLibrariesInSite”。 |
| useQuery | 仅为“query”中定义的内容编制索引。 |
查询
数据源的“query”参数由关键字/值对组成。 下面是可使用的关键字。 这些值是站点 URL 或文档库 URL。
注意
若要获取特定关键字的值,建议导航到想要包含/排除的文档库,并从浏览器复制相应的 URI。 这是获取要在查询中与关键字一起使用的值的最简便方法。
| 关键字 | 值说明和示例 |
|---|---|
| null | 如果为 null 或为空,则索引默认文档库或所有文档库,具体取决于容器名称。 示例: "container" : { "name" : "defaultSiteLibrary", "query" : null } |
| includeLibrariesInSite | 从连接字符串中指定的站点内的所有库索引内容。 该值应为站点或子站点的 URI。 示例 1: "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/mysite" } 示例 2(仅包括几个子网站): "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/sites/TopSite/SubSite1;includeLibrariesInSite=https://mycompany.sharepoint.com/sites/TopSite/SubSite2" } |
| includeLibrary | 从该库中索引所有内容。 该值是库的完全限定路径,可以从浏览器复制: 示例 1(完全限定的路径): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/mysite/MyDocumentLibrary" } 示例 2(从浏览器复制的 URI): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx" } |
| excludeLibrary | 不从此库中索引内容。 该值是库的完全限定路径,可以从浏览器复制: 示例 1(完全限定的路径): "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mysite.sharepoint.com/subsite1; excludeLibrary=https://mysite.sharepoint.com/subsite1/MyDocumentLibrary" } 示例 2(从浏览器复制的 URI): "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/teams/mysite; excludeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx" } |
| additionalColumns | 为文档库中的列编制索引。 该值是要为其编制索引的以逗号分隔的列名列表。 使用双反斜杠来转义列名中的分号和逗号: 示例 1 (additionalColumns=MyCustomColumn,MyCustomColumn2): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/mysite/MyDocumentLibrary;additionalColumns=MyCustomColumn,MyCustomColumn2" } 示例 2(使用双反杠对字符进行转义): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx;additionalColumns=MyCustomColumnWith\\,,MyCustomColumnWith\\;" } |
处理错误
默认情况下,SharePoint Online 索引器一旦遇到包含不受支持的内容类型(例如图像)的文档时,就会立即停止。 可以使用 excludedFileNameExtensions 参数跳过某些内容类型。 但可能需要在事先不知道所有可能内容类型的情况下为文档编制索引。 若要在遇到不受支持的内容类型时继续索引,可将配置参数 failOnUnsupportedContentType 设置为 false:
PUT https://[service name].search.azure.cn/indexers/[indexer name]?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
... other parts of indexer definition
"parameters" : { "configuration" : { "failOnUnsupportedContentType" : false } }
}
对于某些文档,Azure AI 搜索无法确定其内容类型,或者无法处理其他受支持内容类型的文档。 若要忽略此故障模式,将 failOnUnprocessableDocument 配置参数设置为 false:
"parameters" : { "configuration" : { "failOnUnprocessableDocument" : false } }
Azure AI 搜索会限制已编制索引的文档的大小。 这些限制记录在 Azure AI 搜索中的服务限制中。 文档太大会被默认视为错误。 不过,如果将配置参数 indexStorageMetadataOnlyForOversizedDocuments 设为 true,则仍可索引过大文档的存储元数据:
"parameters" : { "configuration" : { "indexStorageMetadataOnlyForOversizedDocuments" : true } }
如果在任意处理点发生错误(无论是在分析文档时,还是在将文档添加到索引时),都仍可继续索引。 若要忽略特定的错误数,将 maxFailedItems 和 maxFailedItemsPerBatch 配置参数设置为所需值。 例如:
{
... other parts of indexer definition
"parameters" : { "maxFailedItems" : 10, "maxFailedItemsPerBatch" : 10 }
}
如果 SharePoint 网站上的文件已启用加密,可能会看到如下所示的错误消息:
Code: resourceModified Message: The resource has changed since the caller last read it; usually an eTag mismatch Inner error: Code: irmEncryptFailedToFindProtector
错误消息还包含以下模式中的 SharePoint 网站 ID、驱动器 ID 和驱动器项 ID:<sharepoint site id> :: <drive id> :: <drive item id>。 此信息可用于识别哪些项在 SharePoint 端失败。 然后,用户可以从项中删除加密来解决该问题。