通过计分概要文件,可以根据条件提升匹配文档的排名。 本文介绍如何指定和分配计分概要文件,以便根据提供的参数提升搜索分数。
可以使用计分概要文件进行关键字搜索、矢量搜索和混合搜索。 但是,计分概要文件仅适用于非矢量字段,因此请确保索引具有可在计分概要文件中使用的文本或数字字段。 2024-05-01-preview 和 2024-07-01 REST API 以及针对这些版本的 Azure SDK 包中提供了对矢量和混合搜索的计分概要文件支持。
有关计分概要文件的要点
计分概要文件参数可以是:
加权字段,在特定字符串字段中找到匹配项。 例如,你可能希望与在“内容”字段中找到的匹配项相比,在“摘要”字段中找到的相同匹配项的相关性更高。
用于数字数据(包括日期、范围和地理坐标)的函数。 还有一个 Tags 函数,可以对提供任意字符串集合的字段进行操作。 若想根据是否在标签字段中找到匹配项来提高分数,则可以选择这种方法而不是加权字段。
可以创建多个概要文件,然后修改查询逻辑以选择使用哪一个。
在一个索引中可以具有最多 100 个计分概要文件(请参阅服务限制),但在任何给定查询中,一次只能指定一个概要文件。
计分概要文件定义
计分概要文件是在索引架构中定义的命名对象。 计分概要文件由加权字段、函数和参数组成。
以下定义展示了名为“geo”的简单概要文件。 此示例用于提升在“hotelName”字段中具有搜索词的结果。 它还使用 distance 函数优先提升在当前位置 10 公里范围内的结果。 如果有人搜索“inn”一词,而“inn”恰好是酒店名称的一部分,包含当前位置 10 公里范围内带有“inn”的酒店的文档会在搜索结果中的较高位置出现。
"scoringProfiles": [
{
"name":"geo",
"text": {
"weights": {
"hotelName": 5
}
},
"functions": [
{
"type": "distance",
"boost": 5,
"fieldName": "location",
"interpolation": "logarithmic",
"distance": {
"referencePointParameter": "currentLocation",
"boostingDistance": 10
}
}
]
}
]
若要使用此计分概要文件,请制定查询,以在请求中指定 scoringProfile 参数。 如果使用 REST API,则通过 GET 和 POST 请求指定查询。 在以下示例中,“currentLocation”具有单连接号 (-) 分隔符。 它后跟经度和纬度坐标,其中经度为负值。
GET /indexes/hotels/docs?search+inn&scoringProfile=geo&scoringParameter=currentLocation--122.123,44.77233&api-version=2024-07-01
请注意使用 POST 时的语法差异。 在 POST 中,“scoringParameters”是复数形式,并且是一个数组。
POST /indexes/hotels/docs&api-version=2024-07-01
{
"search": "inn",
"scoringProfile": "geo",
"scoringParameters": ["currentLocation--122.123,44.77233"]
}
此查询对“inn”一词进行搜索,并在当前位置中传递。 请注意,此查询包含其他参数(例如 scoringParameter)。 查询参数(包括“scoringParameter”)在搜索文档 (REST API) 中介绍。
更多场景请参阅矢量和混合搜索的扩展示例和关键字搜索的扩展示例。
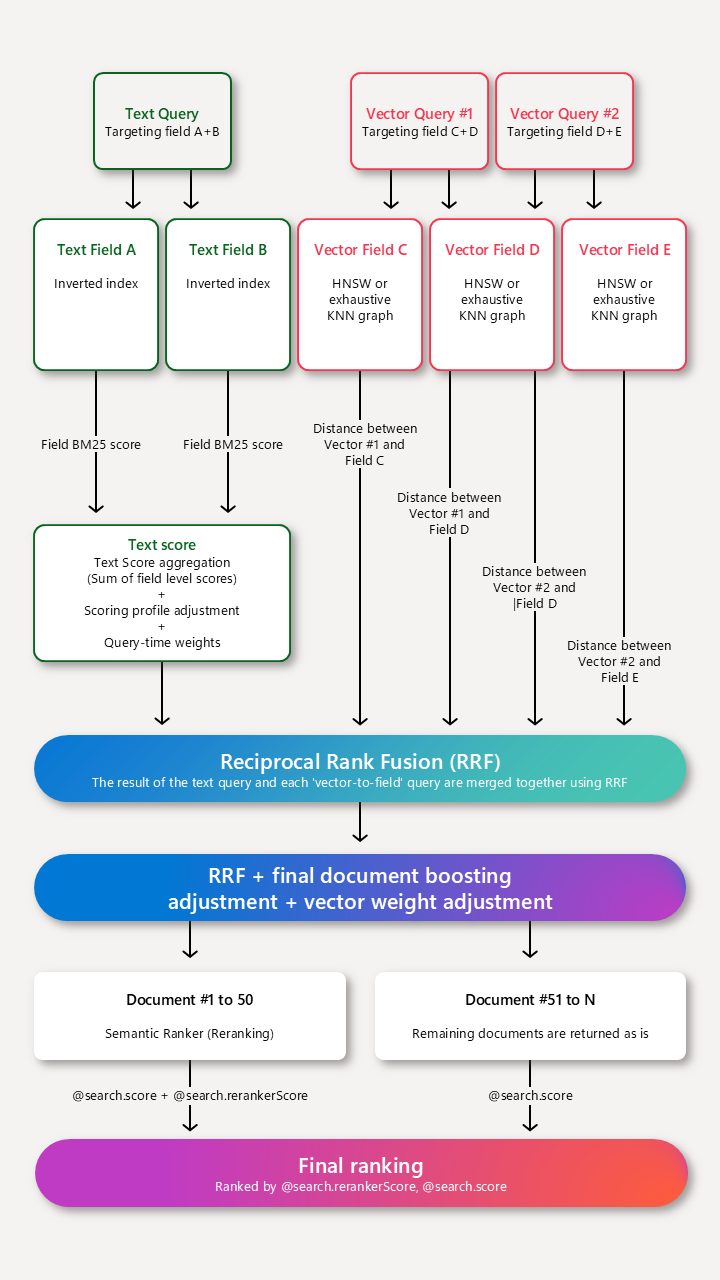
Azure AI 搜索中的搜索评分的工作原理
计分概要文件通过提高符合配置文件标准的匹配分数来完善默认评分算法。 评分函数适用于:
对于独立文本查询,计分概要文件会标识 BM25 排名搜索中的最大 1,000 个匹配项,结果中返回前 50 个匹配项。
对于纯矢量,查询仅为矢量,但如果 k 匹配文档 包含具有人类包含具有人类可读内容的非矢量字段,则可以应用计分概要文件。 评分配置文件通过提升与配置文件中的条件匹配的文档来修改结果集。
对于混合查询中的文本查询,计分配置文件标识 BM25 排名搜索中最多 1,000 个匹配项。 但是,一旦这 1000 个结果被识别出来,它们就会恢复到原来的 BM25 排序,这样就可以在最终的倒数排名函数 (RRF) 排序中,与矢量结果一起进行重新计分,其中计分概要文件(在图中标识为“最终文档提升调整”)将应用于合并结果,最后一步是矢量加权。
将评分概要文件添加到搜索索引
应该以迭代的方式工作,使用有助于证明或反驳给定概要文件有效性的数据集。
可以在 Azure 门户中定义计分概要文件(如以下屏幕截图所示),也可以通过 REST API 或 Azure SDK(例如用于 .NET 的 Azure SDK 中的 ScoringProfile 类)以编程方式定义计分概要文件。

使用文本加权字段
当字段上下文很重要且查询包含 searchable 字符串字段时,使用文本加权字段。 例如,如果查询包含字词“airport”,则你可能希望“Description”字段中的“airport”具有比 HotelName 中更多的权重。
加权字段是由一个 searchable 字段和一个用作乘数的正数组成的名称-值对。 如果 HotelName 的原始字段分数为 3,该字段的提升分数将变为 6,从而提升父文档本身的总体分数。
"scoringProfiles": [
{
"name": "boostSearchTerms",
"text": {
"weights": {
"HotelName": 2,
"Description": 5
}
}
}
]
使用函数
当简单的相对权重不足或不适用时,请使用函数,例如距离和新鲜度的情况(即对数值数据的计算)。 可以为每个计分概要文件指定多个函数。 有关 Azure AI 搜索中使用的 EDM 数据类型的详细信息,请参阅支持的数据类型。
| 函数 | 说明 | 用例 |
|---|---|---|
| distance | 按距离或地理位置提升。 此函数仅可与 Edm.GeographyPoint 字段结合使用。 |
用于“在我附近查找”方案。 |
| freshness | 按照日期/时间字段 (Edm.DateTimeOffset) 中的值进行提升。
设置 boostingDuration 来指定表示发生提升的时间跨度的值。 |
当想要按较新或较旧的日期提升时使用。 排列日历事件等具有未来日期的项,以便接近当前日期的项可以排在距离当前日期较远的将来的项之上。 范围的一端固定为当前时间。 若要扩大过去的时间范围,请使用正 boostingDuration。 要提升将来的时间范围,请使用负的 boostingDuration。 |
| magnitude | 根据数字字段的值范围改变排名。 该值必须是整数或浮点数。 对于星级评分 1 到 4,这里应为 1。 对于超过 50% 的利润率,这里应为 50。 此函数仅可与 Edm.Double 和 Edm.Int 字段结合使用。 对于 magnitude 函数,如果想要反转模式(例如,将价格较低项提升至价格较高项之上),可以将范围反转为从高到低。 假设价格范围从 100 美元到 1 美元,可以将 boostingRangeStart 设为 100、boostingRangeEnd 设为 1 以提升价格较低的项。 |
当想要提高利润率、评级、单击次数、下载次数、最高价格、最低价格或下载次数时使用。 如果两个项相关,具有较高评分的项先显示。 |
| 标记 | 按搜索文档和查询字符串共有的标记提升。
tagsParameter 中提供了标记。 此函数仅可与类型为 Edm.String 和 Collection(Edm.String) 的搜索字段结合使用。 |
当有标签字段时使用。 如果列表中的给定标记本身是逗号分隔的列表,则可在查询时在字段上使用文本规范化器来去除逗号(将逗号字符映射到空格)。 此方法会“平展”列表,以便所有字词都是以逗号分隔的字词的单个长字符串。 |
使用函数的规则
- 函数只能应用于被归为
filterable的字段。 - 函数类型(“freshness”、“magnitude”、“distance”、“tag”)必须为小写。
- 函数不能包含 null 值或空值。
- 每个函数定义中函数只能有一个字段。 若要在同一个配置文件中使用两次度量值,请提供两个定义度量值,每个字段一个。
模板
本部分演示计分概要文件的语法和模板。 有关属性的描述,请参阅 REST API 参考。
"scoringProfiles": [
{
"name": "name of scoring profile",
"text": (optional, only applies to searchable fields) {
"weights": {
"searchable_field_name": relative_weight_value (positive #'s),
...
}
},
"functions": (optional) [
{
"type": "magnitude | freshness | distance | tag",
"boost": # (positive number used as multiplier for raw score != 1),
"fieldName": "(...)",
"interpolation": "constant | linear (default) | quadratic | logarithmic",
"magnitude": {
"boostingRangeStart": #,
"boostingRangeEnd": #,
"constantBoostBeyondRange": true | false (default)
}
// ( - or -)
"freshness": {
"boostingDuration": "..." (value representing timespan over which boosting occurs)
}
// ( - or -)
"distance": {
"referencePointParameter": "...", (parameter to be passed in queries to use as reference location)
"boostingDistance": # (the distance in kilometers from the reference location where the boosting range ends)
}
// ( - or -)
"tag": {
"tagsParameter": "..."(parameter to be passed in queries to specify a list of tags to compare against target field)
}
}
],
"functionAggregation": (optional, applies only when functions are specified) "sum (default) | average | minimum | maximum | firstMatching"
}
],
"defaultScoringProfile": (optional) "...",
设置内插
可通过内插设置评分的坡度形状。 由于评分从高到低,坡度总是在下降,但内插决定了下坡的曲线。 可以使用以下内插:
| 内插 | 说明 |
|---|---|
linear |
对于最大和最小范围内的项,将按递减的方式进行提升。 Linear 是计分概要文件的默认内插。 |
constant |
对于起始和结束范围内的项,将对排名结果应用恒定提升。 |
quadratic |
与具有不断减小的提升的线性内插 (linear) 相比,二次内插 (quadratic) 最初以较小的速度递减,然后在接近结束范围时,以更高的间隔递减。 tag 计分函数中不允许使用此内插选项。 |
logarithmic |
与具有恒定递减提升的线性内插 (linear) 相比,对数内插 (logarithmic) 最初以较大的速度递减,然后在接近结束范围时,以明显更小的间隔递减。 tag 计分函数中不允许使用此内插选项。 |

设置 freshness 函数的 boostingDuration
boostingDuration 是 freshness 函数的属性。 使用它设置一个有效期,超过这个有效期之后,针对特定文档的提升将停止。 例如,要在 10 天促销期内提升某个产品系列或品牌,应针对这些文档将 10 天期限指定为 "P10D"。
boostingDuration 必须设置为 XSD "dayTimeDuration" 值(ISO 8601 持续时间值的受限子集)的格式。 它的模式为:“P[nD][T[nH][nM][nS]]”。
下表提供几个示例。
| 持续时间 | boostingDuration |
|---|---|
| 1 天 | "P1D" |
| 2 天 12 小时 | "P2DT12H" |
| 15 分钟 | "PT15M" |
| 30 天 5 小时 10 分钟 6.334 秒 | "P30DT5H10M6.334S" |
有关更多示例,请参阅 XML 架构:数据类型(W3.org 网站)。
扩展示例
下面的示例演示具有两个计分概要文件(boostGenre、newAndHighlyRated)的索引架构。 针对此索引的任何查询(包含任一概要文件作为查询参数)将使用此概要文件对结果集进行计分。
boostGenre 概要文件使用加权文本字段,提升在“albumTitle”、“genre”和“artistName”字段中找到的匹配项。 这些字段分别提升了 1.5、5 和 2。 genre 为何比其他字段提升更高? 如果对某种程度上为同类的数据执行搜索(正如 musicstoreindex 中的“genre”一样),可能需要在相对权重中具有更大的差异。 例如,在 musicstoreindex 中,“rock”既作为流派显示,又显示在采用相同组句方式的流派说明中。 如果希望流派的权重在流派说明之上,genre 字段将需要更高的相对权重。
{
"name": "musicstoreindex",
"fields": [
{ "name": "key", "type": "Edm.String", "key": true },
{ "name": "albumTitle", "type": "Edm.String" },
{ "name": "albumUrl", "type": "Edm.String", "filterable": false },
{ "name": "genre", "type": "Edm.String" },
{ "name": "genreDescription", "type": "Edm.String", "filterable": false },
{ "name": "artistName", "type": "Edm.String" },
{ "name": "orderableOnline", "type": "Edm.Boolean" },
{ "name": "rating", "type": "Edm.Int32" },
{ "name": "tags", "type": "Collection(Edm.String)" },
{ "name": "price", "type": "Edm.Double", "filterable": false },
{ "name": "margin", "type": "Edm.Int32", "retrievable": false },
{ "name": "inventory", "type": "Edm.Int32" },
{ "name": "lastUpdated", "type": "Edm.DateTimeOffset" }
],
"scoringProfiles": [
{
"name": "boostGenre",
"text": {
"weights": {
"albumTitle": 1.5,
"genre": 5,
"artistName": 2
}
}
},
{
"name": "newAndHighlyRated",
"functions": [
{
"type": "freshness",
"fieldName": "lastUpdated",
"boost": 10,
"interpolation": "quadratic",
"freshness": {
"boostingDuration": "P365D"
}
},
{
"type": "magnitude",
"fieldName": "rating",
"boost": 10,
"interpolation": "linear",
"magnitude": {
"boostingRangeStart": 1,
"boostingRangeEnd": 5,
"constantBoostBeyondRange": false
}
}
]
}
],
"suggesters": [
{
"name": "sg",
"searchMode": "analyzingInfixMatching",
"sourceFields": [ "albumTitle", "artistName" ]
}
]
}