记录并查看指标和日志文件 v1

使用默认的 Python 日志记录包和 Azure 机器学习 Python SDK 特有的功能来记录实时信息。 你可以在本地进行记录,并将日志发送到门户中的工作区。
日志可帮助你诊断错误和警告,或跟踪参数和模型性能等性能指标。 本文介绍如何在以下场景中启用日志记录功能:
- 记录运行指标
- 交互式训练会话
- 使用 ScriptRunConfig 提交训练作业
- Python 的原生
logging设置 - 来自其他源的日志记录
提示
本文说明如何监视模型训练过程。 如果你希望监视 Azure 机器学习的资源使用情况和事件,例如配额、已完成的训练运行或已完成的模型部署,请参阅监视 Azure 机器学习。
数据类型
可以记录多个数据类型,包括标量值、列表、表、图像、目录等。 有关不同数据类型的详细信息和 Python 代码示例,请查看 Run 类参考页。
运行指标日志记录
使用日志记录 API 中的以下方法可影响指标可视化效果。 请注意这些记录的指标的服务限制。
| 记录的值 | 示例代码 | 门户中的格式 |
|---|---|---|
| 记录一组数值 | run.log_list(name='Fibonacci', value=[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]) |
单变量折线图 |
| 使用重复使用的相同指标名称记录单个数值(例如在 for 循环中) | for i in tqdm(range(-10, 10)): run.log(name='Sigmoid', value=1 / (1 + np.exp(-i))) angle = i / 2.0 |
单变量折线图 |
| 重复记录包含 2 个数字列的行 | run.log_row(name='Cosine Wave', angle=angle, cos=np.cos(angle)) sines['angle'].append(angle) sines['sine'].append(np.sin(angle)) |
双变量折线图 |
| 记录包含 2 个数字列的表 | run.log_table(name='Sine Wave', value=sines) |
双变量折线图 |
| 日志图像 | run.log_image(name='food', path='./breadpudding.jpg', plot=None, description='desert') |
使用此方法在运行中记录图像文件或 matplotlib 图。 运行记录中可显示和比较这些图像 |
用 MLflow 进行日志记录
建议使用 MLflow 来记录模型、指标和项目,因为它是开源的,并且支持从本地移植到云。 下表和代码示例演示了如何使用 MLflow 来记录训练运行中的指标和项目。 详细了解 MLflow 的日志记录方法和设计模式。
请确保将 mlflow 和 azureml-mlflow pip 包安装到工作区。
pip install mlflow
pip install azureml-mlflow
将 MLflow 跟踪 URI 设置为指向 Azure 机器学习后端,以确保将指标和项目记录到工作区。
from azureml.core import Workspace
import mlflow
from mlflow.tracking import MlflowClient
ws = Workspace.from_config()
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.create_experiment("mlflow-experiment")
mlflow.set_experiment("mlflow-experiment")
mlflow_run = mlflow.start_run()
| 记录的值 | 示例代码 | 说明 |
|---|---|---|
| 记录数值(int 或 float) | mlflow.log_metric('my_metric', 1) |
|
| 记录布尔值 | mlflow.log_metric('my_metric', 0) |
0 = True,1 = False |
| 记录字符串 | mlflow.log_text('foo', 'my_string') |
记录为项目 |
| 记录 numpy 指标或 PIL 图像对象 | mlflow.log_image(img, 'figure.png') |
|
| 记录 matplotlib 绘图或图像文件 | mlflow.log_figure(fig, "figure.png") |
通过 SDK 查看运行指标
可以使用 run.get_metrics() 查看训练的模型的指标。
from azureml.core import Run
run = Run.get_context()
run.log('metric-name', metric_value)
metrics = run.get_metrics()
# metrics is of type Dict[str, List[float]] mapping metric names
# to a list of the values for that metric in the given run.
metrics.get('metric-name')
# list of metrics in the order they were recorded
还可以通过运行对象的数据和信息属性,使用 MLflow 来访问运行信息。 有关详细信息,请参阅 MLflow.entities.Run 对象文档。
在该运行完成后,可以使用 MlFlowClient () 来检索它。
from mlflow.tracking import MlflowClient
# Use MlFlow to retrieve the run that was just completed
client = MlflowClient()
finished_mlflow_run = MlflowClient().get_run(mlflow_run.info.run_id)
可以在运行对象的数据字段中查看该运行的指标、参数和标记。
metrics = finished_mlflow_run.data.metrics
tags = finished_mlflow_run.data.tags
params = finished_mlflow_run.data.params
注意
mlflow.entities.Run.data.metrics 下的指标字典只返回某个给定指标名称的最近记录的值。 例如,如果按顺序依次将 1、2、3、4 记录到名为 sample_metric 的指标,则在 sample_metric 的指标字典中只会存在 4。
若要获取为某个特定指标名称记录的所有指标,可以使用 MlFlowClient.get_metric_history()。
在工作室 UI 中查看运行指标
可以在 Azure 机器学习工作室中浏览已完成的运行记录,包括记录的指标。
导航到“试验”选项卡。若要查看工作区中各个试验的所有运行,请选择“所有运行”选项卡。可应用顶部菜单栏中的“试验”筛选器来深入了解特定试验的运行。
对于各个试验视图,请选择“所有试验”选项卡。在“试验运行”仪表板中,可以看到为每次运行跟踪的指标和日志。
还可以编辑“运行列表”表,以选择多个运行并显示运行的最新记录值、最小记录值或最大记录值。 自定义自己的图表,以比较多个运行上的已记录指标值和聚合。 你可以在图表的 y 轴上绘制多个指标,并自定义 x 轴以绘制记录的指标。
查看并下载运行用的日志文件
日志文件是用于调试 Azure 机器学习工作负载的重要资源。 提交训练作业后,向下钻取到特定运行以查看其日志和输出:
- 导航到“试验”选项卡。
- 选择特定运行的 runID。
- 选择页面顶部的“输出和日志”。
- 选择“全部下载”,将所有日志下载到 zip 文件夹中。
- 还可以通过选择日志文件并选择“下载”来下载单个日志文件
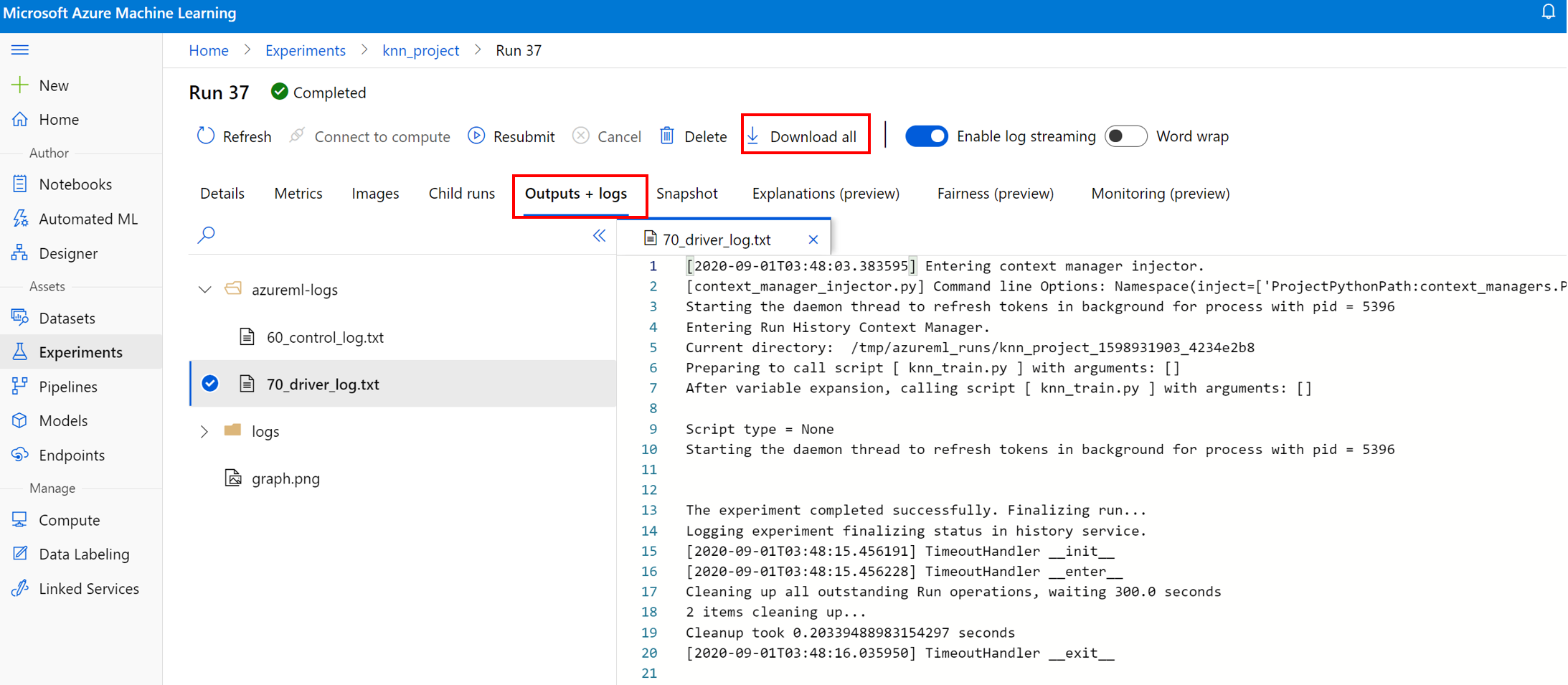
user_logs 文件夹
此文件夹包含有关用户生成的日志的信息。 此文件夹默认打开,并选择 std_log.txt 日志。 std_log.txt 是代码日志(例如,打印语句)出现的位置。 此文件包含来自控制脚本和训练脚本的 stdout 日志和 stderr 日志,每个进程一个日志。 大多数情况下,你都将在此处监视日志。
system_logs 文件夹
此文件夹包含 Azure 机器学习生成的日志,默认情况下将关闭。 系统生成的日志会根据运行时作业的阶段分组到不同的文件夹中。
其他文件夹
对于多个计算群集上的作业训练,将会针对每个节点 IP 提供日志。 每个节点的结构都与单节点作业相同。 对于总体执行、stderr 和 stdout 日志,还有一个额外的日志文件夹。
Azure 机器学习会在训练期间记录来自各种源的信息,例如运行训练作业的 AutoML 或 Docker 容器。 其中的许多日志没有详细的阐述。 如果遇到问题且联系了 Azure 支持部门,他们可以在排除故障时使用这些日志。
交互式日志记录会话
交互式日志记录会话通常用在笔记本环境中。 方法 Experiment.start_logging() 启动交互式日志记录会话。 试验中会话期间记录的任何指标都会添加到运行记录中。 方法 run.complete() 结束会话并将运行标记为已完成。
ScriptRun 日志
本部分介绍使用了 ScriptRunConfig 进行配置时,如何在创建的各次运行之内添加记录代码。 可以使用 ScriptRunConfig 类来封装用于可重复运行的脚本和环境。 还可以使用此选项来显示一个用于监视的 Jupyter Notebooks 视觉小组件。
此示例使用 run.log() 方法对 alpha 值执行参数扫描并捕获结果。
创建包含日志记录逻辑的训练脚本
train.py。# Copyright (c) Microsoft. All rights reserved. # Licensed under the MIT license. from sklearn.datasets import load_diabetes from sklearn.linear_model import Ridge from sklearn.metrics import mean_squared_error from sklearn.model_selection import train_test_split from azureml.core.run import Run import os import numpy as np import mylib # sklearn.externals.joblib is removed in 0.23 try: from sklearn.externals import joblib except ImportError: import joblib os.makedirs('./outputs', exist_ok=True) X, y = load_diabetes(return_X_y=True) run = Run.get_context() X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) data = {"train": {"X": X_train, "y": y_train}, "test": {"X": X_test, "y": y_test}} # list of numbers from 0.0 to 1.0 with a 0.05 interval alphas = mylib.get_alphas() for alpha in alphas: # Use Ridge algorithm to create a regression model reg = Ridge(alpha=alpha) reg.fit(data["train"]["X"], data["train"]["y"]) preds = reg.predict(data["test"]["X"]) mse = mean_squared_error(preds, data["test"]["y"]) run.log('alpha', alpha) run.log('mse', mse) model_file_name = 'ridge_{0:.2f}.pkl'.format(alpha) # save model in the outputs folder so it automatically get uploaded with open(model_file_name, "wb") as file: joblib.dump(value=reg, filename=os.path.join('./outputs/', model_file_name)) print('alpha is {0:.2f}, and mse is {1:0.2f}'.format(alpha, mse))提交要在用户管理的环境中运行的
train.py脚本。 整个脚本文件夹都要提交,以便进行训练。from azureml.core import ScriptRunConfig src = ScriptRunConfig(source_directory='./', script='train.py', environment=user_managed_env)run = exp.submit(src)show_output参数会启用详细日志记录,让你可以查看训练过程的详细信息,以及有关任何远程资源或计算目标的信息。 请使用以下代码在提交试验时启用详细日志记录。run = exp.submit(src, show_output=True)还可以在生成的运行上的
wait_for_completion函数中使用相同的参数。run.wait_for_completion(show_output=True)
原生 Python 日志记录
SDK 中的某些日志可能包含一个错误,指示你将日志记录级别设置为“调试”。 若要设置日志记录级别,请在脚本中添加以下代码。
import logging
logging.basicConfig(level=logging.DEBUG)
其他日志记录源
Azure 机器学习还可以在训练期间记录其他来源的信息,例如自动化机器学习运行或运行作业的 Docker 容器。 这些日志未进行记录,但如果你遇到问题并联系了 Azure 支持部门,他们可以在排除故障时使用这些日志。
有关在 Azure 机器学习设计器中记录指标的信息,请参阅如何在设计器中记录指标
示例笔记本
下面的笔记本展示了本文中的概念:
- how-to-use-azureml/training/train-on-local
- how-to-use-azureml/track-and-monitor-experiments/logging-api
阅读使用 Jupyter 笔记本探索此服务一文,了解如何运行笔记本。
后续步骤
请参阅以下文章,详细了解如何使用 Azure 机器学习:
- 查看教程使用 Azure 机器学习训练图像分类模型中的示例,了解如何注册和部署最佳模型。