教程:在 Azure 机器学习中上传、访问和浏览数据
适用于: Python SDK azure-ai-ml v2(当前版本)
Python SDK azure-ai-ml v2(当前版本)
本教程介绍如何执行下列操作:
- 将数据上传到云存储空间
- 创建 Azure 机器学习数据资产
- 访问笔记本中的数据以进行交互式开发
- 创建新版本的数据资产
机器学习项目的开始阶段通常涉及到探索性数据分析 (EDA)、数据预处理(清理、特征工程)以及生成机器学习模型原型来验证假设。 此原型制作项目阶段具有高度的交互性。 它适合在 IDE 或 Jupyter 笔记本中使用 Python 交互式控制台进行开发。 本教程介绍了这些想法。
先决条件
-
要使用 Azure 机器学习,你需要一个工作区。 如果没有工作区,请完成创建开始使用所需的资源以创建工作区并详细了解如何使用它。
重要
如果你的 Azure 机器学习工作区配置了托管虚拟网络,则可能需要添加出站规则以允许访问公共 Python 包存储库。 有关详细信息,请参阅应用场景:访问公共机器学习包。
-
登录到工作室,选择工作区(如果尚未打开)。
-
在工作区中打开或创建一个笔记本:
设置内核并在 Visual Studio Code (VS Code) 中打开
在打开的笔记本上方的顶部栏中,创建一个计算实例(如果还没有计算实例)。

如果计算实例已停止,请选择“启动计算”,并等待它运行。

等待计算实例运行。 然后确保右上角的内核为
Python 3.10 - SDK v2。 如果不是,请使用下拉列表选择该内核。
如果没有看到该内核,请验证计算实例是否正在运行。 如果它正在运行,请选择笔记本右上角的“刷新”按钮。
如果看到一个横幅,提示你需要进行身份验证,请选择“身份验证”。
可在此处运行笔记本,或者在 VS Code 中将其打开,以获得具有 Azure 机器学习资源强大功能的完整集成开发环境 (IDE)。 选择“在 VS Code 中打开”,然后选择 Web 或桌面选项。 以这种方式启动时,VS Code 将附加到计算实例、内核和工作区文件系统。
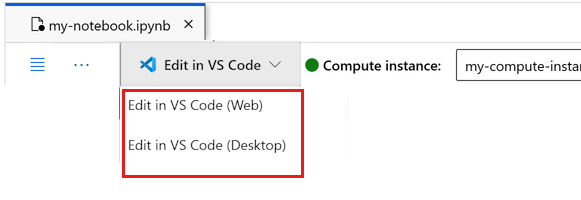




重要
本教程的其余部分包含教程笔记本的单元格。 将其复制并粘贴到新笔记本中,或者立即切换到该笔记本(如果已克隆该笔记本)。
下载本教程中使用的数据
对于数据引入,Azure 数据资源管理器处理这些格式的原始数据。 本教程使用此 CSV 格式的信用卡客户数据示例。 这些步骤将在一个 Azure 机器学习资源中进行。 在该资源中,我们将在笔记本所在的文件夹下创建一个本地文件夹,建议的名称为“数据”。
注意
本教程依赖于 Azure 机器学习资源文件夹位置中放置的数据。 对于本教程,“local”表示该 Azure 机器学习资源中的文件夹位置。
选择三点下方的“打开终端”,如此图所示:
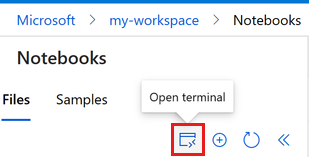
终端窗口将在新选项卡中打开。
请确保
cd(意思是“更改目录”)到此笔记本所在的同一文件夹。 例如,如果笔记本位于名为 get-started-notebooks 的文件夹中:cd get-started-notebooks # modify this to the path where your notebook is located在终端窗口中输入以下命令,将数据复制到计算实例:
mkdir data cd data # the sub-folder where you'll store the data wget https://azuremlexamples.blob.core.chinacloudapi.cn/datasets/credit_card/default_of_credit_card_clients.csv现在可以关闭终端窗口。
有关 UC Irvine 机器学习存储库中的数据的详细信息,请访问此资源。
创建工作区的句柄
在了解代码之前,需要一种方法来引用工作区。 你将为工作区句柄创建 ml_client。 然后,使用 ml_client 来管理资源和作业。
在下一个单元格中,输入你的订阅 ID、资源组名称和工作区名称。 若要查找这些值:
- 在右上方的 Azure 机器学习工作室工具栏上,选择工作区名称。
- 将工作区、资源组和订阅 ID 的值复制到代码中。
- 必须一次单独复制一个值,关闭区域并粘贴,然后继续下一个值。
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
注意
创建 MLClient 不会连接到工作区。 客户端初始化不会立即进行, 而是会等待第一次需要进行调用。 这发生在下一个代码单元中。
将数据上传到云存储空间
Azure 机器学习使用统一资源标识符 (URI),它们指向云中的存储位置。 使用 URI 可以轻松访问笔记本和作业中的数据。 数据 URI 格式类似于在 Web 浏览器中用于访问网页的 Web URL。 例如:
- 从公共 https 服务器访问数据:
https://<account_name>.blob.core.chinacloudapi.cn/<container_name>/<folder>/<file> - 从 Azure Data Lake Gen 2 访问数据:
abfss://<file_system>@<account_name>.dfs.core.chinacloudapi.cn/<folder>/<file>
Azure 机器学习数据资产类似于 Web 浏览器书签(收藏夹)。 可以创建数据资产,然后使用易记名称访问该资产,而无需记住指向最常用数据的冗长存储路径 (URI)。
通过创建数据资产,还可以创建对数据源位置的引用及其元数据的副本。 由于数据保留在其现有位置中,因此不会产生额外的存储成本,也不会损害数据源的完整性。 可以从 Azure 机器学习数据存储、Azure 存储、公共 URL 和本地文件创建数据资产。
提示
对于较小的数据上传,Azure 机器学习数据资产创建适用于从本地计算机资源到云存储空间的数据上传。 此方法可避免使用额外的工具或实用工具。 但是,较大的数据上传可能需要专用工具或实用工具(例如 azcopy)。 azcopy 命令行工具可将数据移向和移出 Azure 存储。 有关 azcopy 的详细信息,请访问此资源。
下一个笔记本单元格会创建数据资产。 此代码示例将原始数据文件上传到指定的云存储资源。
每次创建数据资产时,都需要为其创建唯一版本。 如果版本已存在,则会收到错误。 在此代码中,我们使用“initial”来首次读取数据。 如果该版本已存在,我们不会重新创建它。
你还可以省略版本参数。 在这种情况下,系统会为你生成版本号,从 1 开始,然后递增。
本教程使用名称“initial”作为第一个版本。 创建机器学习生产管道教程也将使用此版本的数据,因此,你将会在该教程中再次看到我们在此处使用的值。
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# update the 'my_path' variable to match the location of where you downloaded the data on your
# local filesystem
my_path = "./data/default_of_credit_card_clients.csv"
# set the version number of the data asset
v1 = "initial"
my_data = Data(
name="credit-card",
version=v1,
description="Credit card data",
path=my_path,
type=AssetTypes.URI_FILE,
)
## create data asset if it doesn't already exist:
try:
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(
f"Data asset already exists. Name: {my_data.name}, version: {my_data.version}"
)
except:
ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
要检查上传的数据,请选择左侧的“数据”。 数据已上传且数据资产已创建:
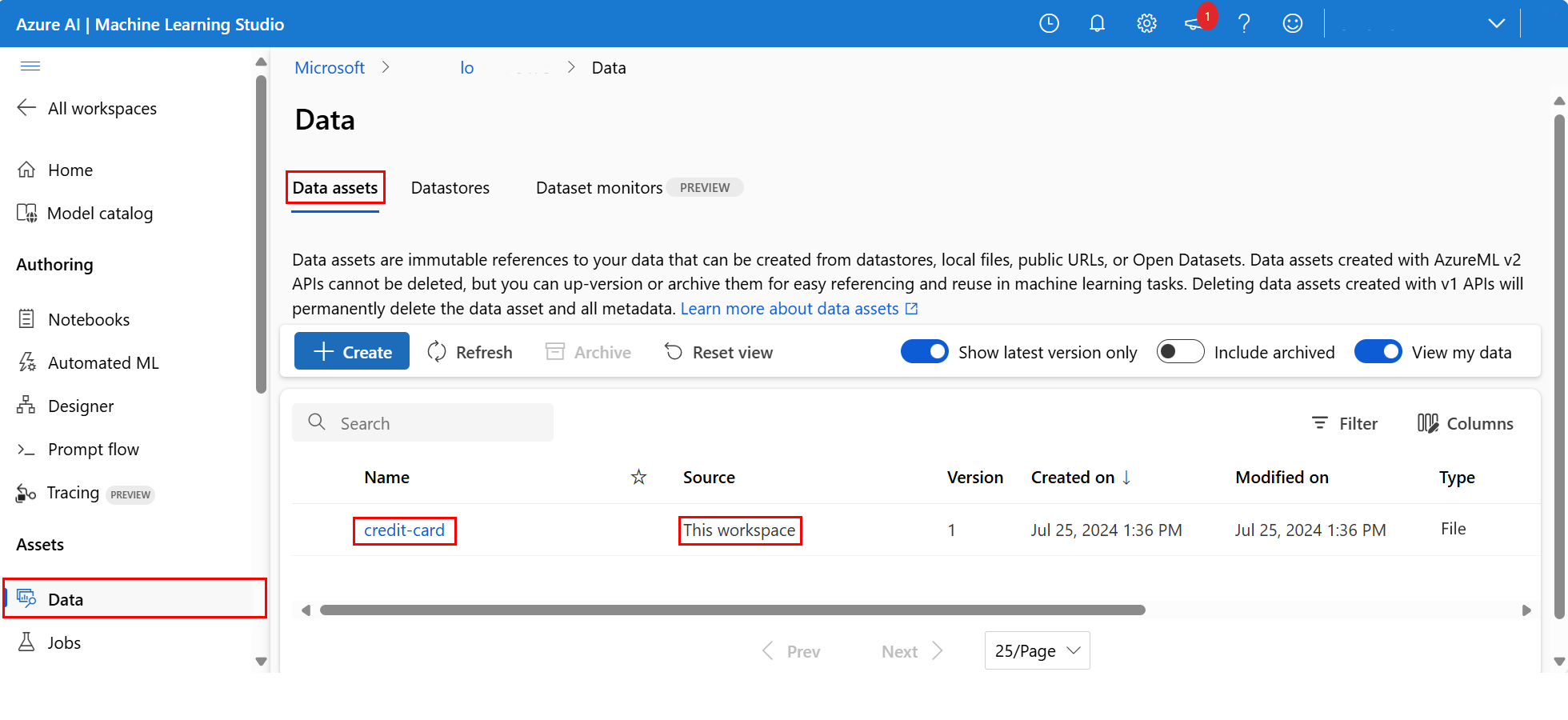
此数据命名为 credit-card,在“数据资产”选项卡中,可以在“名称”列中看到它。
Azure 机器学习数据存储是对 Azure 上现有存储帐户的引用。 数据存储具有以下优势:
可使用常见易用的 API 与不同的存储类型进行交互
- Azure Data Lake Storage
- Blob
- 文件
和身份验证方法。
一种在团队协作时更轻松地发现有用的数据存储的方式。
在你的脚本中,隐藏基于凭据的数据访问连接信息的方法(服务主体/SAS/密钥)。
访问笔记本中的数据
Pandas 直接支持 URI - 此示例演示如何从 Azure 机器学习数据存储读取 CSV 文件:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
但是,如前所述,可能很难记住这些 URI。 此外,必须手动将 pd.read_csv 命令中的所有 <substring> 值替换为资源的实际值。
需要为经常访问的数据创建数据资产。 下面是在 Pandas 中访问 CSV 文件的更简单的方法:
重要
在笔记本单元格中,执行以下代码以在 Jupyter 内核中安装 azureml-fsspec Python 库:
%pip install -U azureml-fsspec
import pandas as pd
# get a handle of the data asset and print the URI
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(f"Data asset URI: {data_asset.path}")
# read into pandas - note that you will see 2 headers in your data frame - that is ok, for now
df = pd.read_csv(data_asset.path)
df.head()
有关笔记本中的数据访问的详细信息,请访问在交互式开发期间从 Azure 云存储访问数据。
创建新版本的数据资产
数据需要稍微清理一下,使其适合训练机器学习模型。 它具有:
- 两个标头
- 客户端 ID 列;我们不会在机器学习中使用此功能
- 响应变量名称中的空格
此外,与 CSV 格式相比,Parquet 文件格式成为存储此数据的更好方法。 Parquet 可提供压缩,并维护架构。 要清理数据并将其存储在 Parquet 中,请使用:
# read in data again, this time using the 2nd row as the header
df = pd.read_csv(data_asset.path, header=1)
# rename column
df.rename(columns={"default payment next month": "default"}, inplace=True)
# remove ID column
df.drop("ID", axis=1, inplace=True)
# write file to filesystem
df.to_parquet("./data/cleaned-credit-card.parquet")
此表显示了在前面的步骤中下载的原始 default_of_credit_card_clients.csv .CSV 文件中的数据结构。 上传的数据包含 23 个解释变量和 1 个响应变量,如下所示:
| 列名 | 变量类型 | 说明 |
|---|---|---|
| X1 | 解释型 | 给予的信贷金额(新台币):它包括个人消费信贷和他们的家庭(附加)信贷。 |
| X2 | 解释型 | 性别(1 = 男性;2 = 女性)。 |
| X3 | 解释型 | 教育(1 = 研究生;2 = 本科;3 = 高中;4 = 其他)。 |
| X4 | 解释型 | 婚姻状况(1 = 已婚;2 = 单身;3 = 其他)。 |
| X5 | 解释型 | 年龄(年)。 |
| X6-X11 | 解释型 | 过去付款的历史记录。 我们跟踪了过去的每月付款记录(从 2005 年 4 月到 9 月)。 -1 = 按期付款;1 = 付款延迟一个月;2 = 付款延迟两个月; 。 8 = 付款延迟 8 个月;9 = 付款延迟 9 个月及以上。 |
| X12-17 | 解释型 | 2005 年 4 月到 9 月账单金额流水(新台币)。 |
| X18-23 | 解释型 | 2005 年 4 月到 9 月的先前付款金额(新台币)。 |
| Y | 响应 | 默认付款(是 = 1,否 = 0) |
接下来,创建数据资产的新版本(数据会自动上传到云存储空间)。 对于此版本,请添加时间值,以便每次运行此代码时,都会创建不同的版本号。
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
import time
# Next, create a new *version* of the data asset (the data is automatically uploaded to cloud storage):
v2 = "cleaned" + time.strftime("%Y.%m.%d.%H%M%S", time.gmtime())
my_path = "./data/cleaned-credit-card.parquet"
# Define the data asset, and use tags to make it clear the asset can be used in training
my_data = Data(
name="credit-card",
version=v2,
description="Default of credit card clients data.",
tags={"training_data": "true", "format": "parquet"},
path=my_path,
type=AssetTypes.URI_FILE,
)
## create the data asset
my_data = ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
清理的 parquet 文件是最新版本的数据源。 此代码先显示 CSV 版本结果集,然后显示 Parquet 版本:
import pandas as pd
# get a handle of the data asset and print the URI
data_asset_v1 = ml_client.data.get(name="credit-card", version=v1)
data_asset_v2 = ml_client.data.get(name="credit-card", version=v2)
# print the v1 data
print(f"V1 Data asset URI: {data_asset_v1.path}")
v1df = pd.read_csv(data_asset_v1.path)
print(v1df.head(5))
# print the v2 data
print(
"_____________________________________________________________________________________________________________\n"
)
print(f"V2 Data asset URI: {data_asset_v2.path}")
v2df = pd.read_parquet(data_asset_v2.path)
print(v2df.head(5))
清理资源
如果打算继续学习其他教程,请跳到后续步骤。
停止计算实例
如果现在不打算使用计算实例,请将其停止:
- 在工作室的左侧导航区域中,选择“计算”。
- 在顶部选项卡中,选择“计算实例”
- 在列表中选择该计算实例。
- 在顶部工具栏中,选择“停止”。
删除所有资源
重要
已创建的资源可用作其他 Azure 机器学习教程和操作方法文章的先决条件。
如果你不打算使用已创建的任何资源,请删除它们,以免产生任何费用:
在 Azure 门户的搜索框中输入“资源组”,然后从结果中选择它。
从列表中选择你创建的资源组。
在“概述”页面上,选择“删除资源组”。
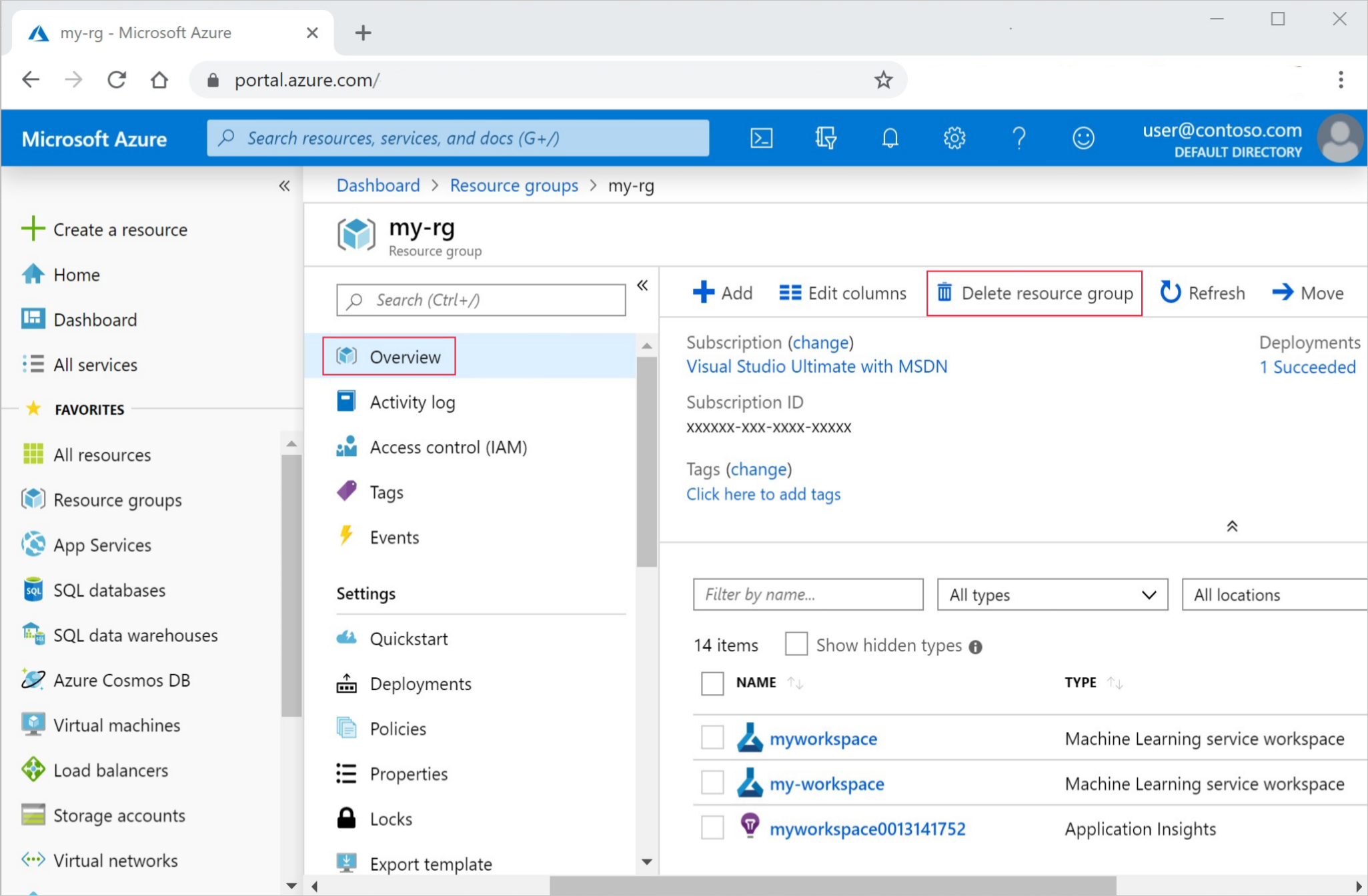
输入资源组名称。 然后选择“删除”。
后续步骤
有关数据资产的详细信息,请访问创建数据资产。
有关数据存储的详细信息,请访问创建数据存储。
继续学习下一教程,了解如何开发训练脚本: