教程:Azure 机器学习工作室中无代码自动机器学习的预测需求
了解如何在 Azure 机器学习工作室中使用自动化机器学习在不编写任何代码行的情况下创建时序预测模型。 此模型将预测自行车共享服务的租赁需求。
在本教程中,你不会编写任何代码,而是使用工作室界面来执行训练。 你将了解如何执行以下任务:
- 创建并加载数据集。
- 配置并运行自动化 ML 试验。
- 指定预测设置。
- 浏览试验结果。
- 部署最佳模型。
此外,请为其他这些模型类型尝试自动化机器学习:
- 如需分类模型的无代码示例,请参阅教程:使用 Azure 机器学习中的自动化 ML 创建分类模型。
- 有关物体检测模型的代码优先示例,请参阅教程:使用 AutoML 和 Python 训练物体检测模型。
先决条件
Azure 机器学习工作区。 请参阅创建工作区资源。
下载 bike-no.csv 数据文件
登录到工作室
本教程将在 Azure 机器学习工作室中创建自动化 ML 试验运行。机器学习工作室是一个整合的 Web 界面,其中包含的机器学习工具可让各种技能水平的数据科学实践者执行数据科学方案。 Internet Explorer 浏览器不支持此工作室。
登录到 Azure 机器学习工作室。
选择创建的订阅和工作区。
选择“开始”。
在左窗格的“创作”部分,选择“自动化 ML” 。
选择“+新建自动化 ML 作业”。
创建并加载数据集
在配置试验之前,请以 Azure 机器学习数据集的形式将数据文件上传到工作区。 这可以确保数据格式适合在试验中使用。
在“选择数据集”窗体中,从“+ 创建数据集”下拉列表中选择“从本地文件”。
在“基本信息”窗体中,为数据集指定名称,并提供可选的说明。 数据集类型默认为“表格”,因为 Azure 机器学习工作室中的自动化 ML 目前仅支持表格数据集。
在左下角选择“下一步”
在“数据存储和文件选择”窗体上,选择在创建工作区期间自动设置的默认数据存储“workspaceblobstore(Azure Blob 存储)”。 这是要将数据文件上传到的存储位置。
在“上传”下拉菜单中,选择“上传文件”。
在本地计算机上选择“bike-no.csv”文件。 这是作为必备组件下载的文件。
选择“下一步”
上传完成后,系统会根据文件类型预先填充“设置和预览”窗体。
验证“设置和预览”窗体是否已填充如下,然后选择“下一步”。
字段 说明 教程的值 文件格式 定义文件中存储的数据的布局和类型。 带分隔符 分隔符 一个或多个字符,用于指定纯文本或其他数据流中不同的独立区域之间的边界。 逗号 编码 指定字符架构表中用于读取数据集的位。 UTF-8 列标题 指示如何处理数据集的标头(如果有)。 仅第一个文件包含标头 跳过行 指示要跳过数据集中的多少行(如果有)。 无 通过“架构”窗体,可以进一步为此试验配置数据。
对于本示例,请选择忽略 casual 和 registered 列。 这些列是 cnt 列的细目,因此我们不会包含这些列。
此外,对于本示例,请保留“属性”和“类型”的默认值。
选择“下一页”。
在“确认详细信息”窗体上,确认信息与先前在“基本信息”和“设置和预览”窗体上填充的内容匹配。
选择“创建”以完成数据集的创建。
当数据集出现在列表中时,则选择它。
选择“下一页”。
配置作业
加载并配置数据后,请设置远程计算目标,并在数据中选择要预测的列。
- 按如下所述填充“配置作业”窗体:
输入试验名称:
automl-bikeshare选择“cnt”作为要预测的目标列。 此列指示共享单车的租赁总次数。
选择“计算群集”作为计算类型。
选择“+ 新建”以配置计算目标。 自动 ML 仅支持 Azure 机器学习计算。
填充“选择虚拟机”窗体以设置计算。
字段 说明 教程的值 虚拟机层 选择试验应具有的优先级 专用 虚拟机类型 选择计算的虚拟机大小。 CPU(中央处理单元) 虚拟机大小 指定计算资源的虚拟机大小。 根据数据和试验类型提供了建议的大小列表。 Standard_DS12_V2 选择“下一步”以填充“配置设置窗体”。
字段 说明 教程的值 计算名称 用于标识计算上下文的唯一名称。 bike-compute 最小/最大节点数 要分析数据,必须指定一个或多个节点。 最小节点数:1
最大节点数:6缩减前的空闲秒数 群集自动缩减到最小节点数之前的空闲时间。 120(默认值) 高级设置 用于为试验配置虚拟网络并对其进行授权的设置。 无 选择“创建”,获取计算目标。
完成此操作需要数分钟的时间。
创建后,从下拉列表中选择新的计算目标。
选择“下一步”。
选择预测设置
通过指定机器学习任务类型和配置设置来完成自动化 ML 试验的设置。
在“任务类型和设置”窗体中,选择“时序预测”作为机器学习任务类型。
选择“日期”作为时间列,将“时序标识符”留空。
“频率”是指收集历史数据的频率。 保留选择“自动检测”。
“预测范围”是要预测的未来时间长短。 取消选择“自动检测”,并在字段中键入 14。
选择“查看其他配置设置”并按如下所示填充字段。 这些设置旨在更好地控制训练作业以及指定预测设置。 否则,将会根据试验选择和数据应用默认设置。
其他配置 说明 教程的值 主要指标 对机器学习算法进行度量时依据的评估指标。 规范化均方根误差 解释最佳模型 自动显示有关自动化 ML 创建的最佳模型的可解释性。 启用 阻止的算法 要从训练作业中排除的算法 极端随机树 其他预测设置 这些设置有助于提高模型的准确度。
预测目标滞后:要将目标变量的滞后往后推多久
目标滚动窗口:指定滚动窗口的大小(例如 max、min 和 sum),将基于此大小生成特征。
预测目标滞后:无
目标滚动窗口大小:无退出条件 如果符合某个条件,则会停止训练作业。 训练作业时间(小时):3
指标分数阈值:无并发 每次迭代执行的并行迭代的最大数目 最大并发迭代数:6 选择“保存”。
选择“下一步” 。
在“[可选]验证和测试”窗体上,
- 选择“k-折交叉验证”作为“验证类型”。
- 选择“5”作为“交叉验证次数”。
运行试验
若要运行试验,请选择“完成”。 此时会打开“作业详细信息”屏幕,其顶部的作业编号旁边显示了“作业状态”。 此状态随着试验的进行而更新。 通知也会显示在工作室的右上角,以告知你试验的状态。
重要
准备试验作业时,准备需要 10-15 分钟。
运行以后,每个迭代还需要 2-3 分钟。
在生产环境中,此过程需要一段时间,因此不妨干点其他的事。 在等待过程中,我们建议在“模型”选项卡上开始浏览已完成测试的算法。
浏览模型
导航到“模型”选项卡,以查看测试的算法(模型)。 默认情况下,这些模型在完成后按指标分数排序。 对于本教程,列表中首先显示评分最高的模型(评分根据所选的“规范化均方根误差”指标给出)。
在等待所有试验模型完成的时候,可以选择已完成模型的“算法名称”,以便浏览其性能详细信息。
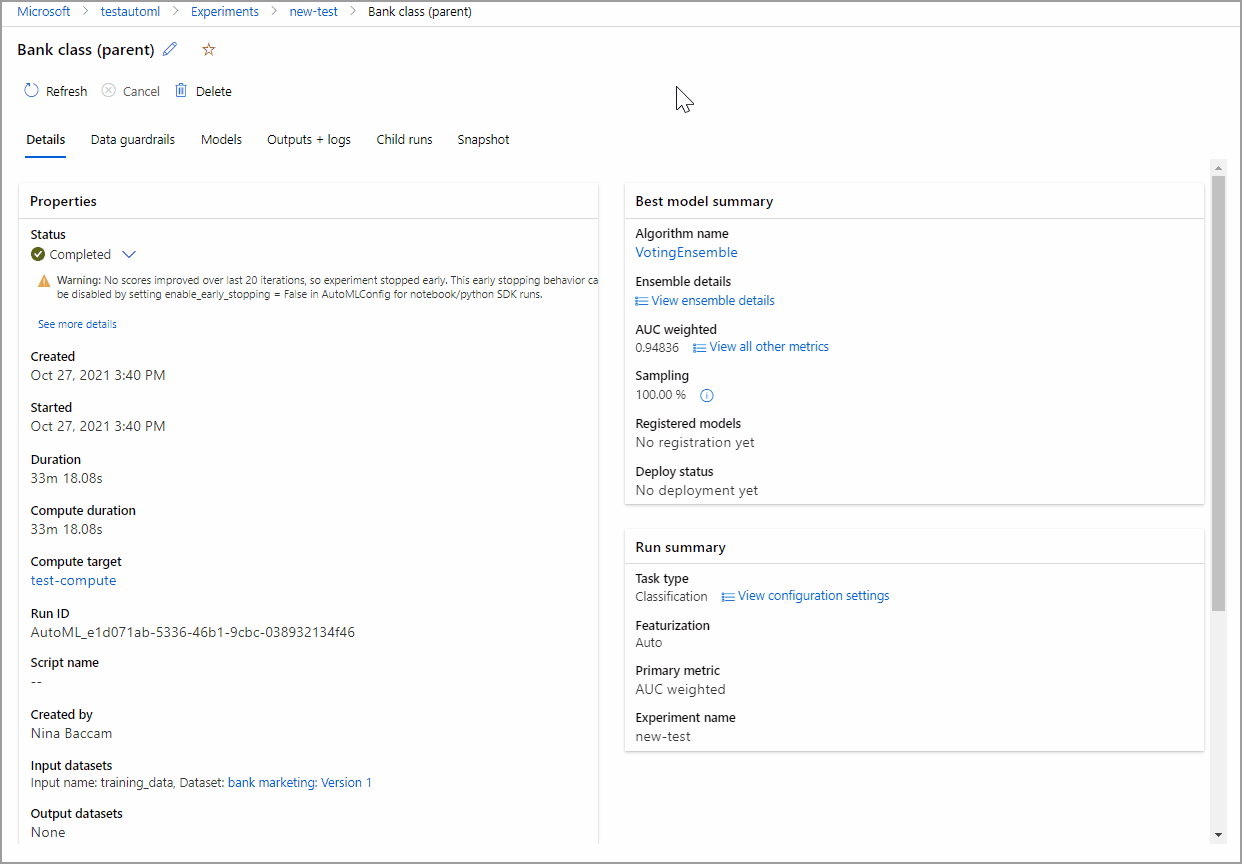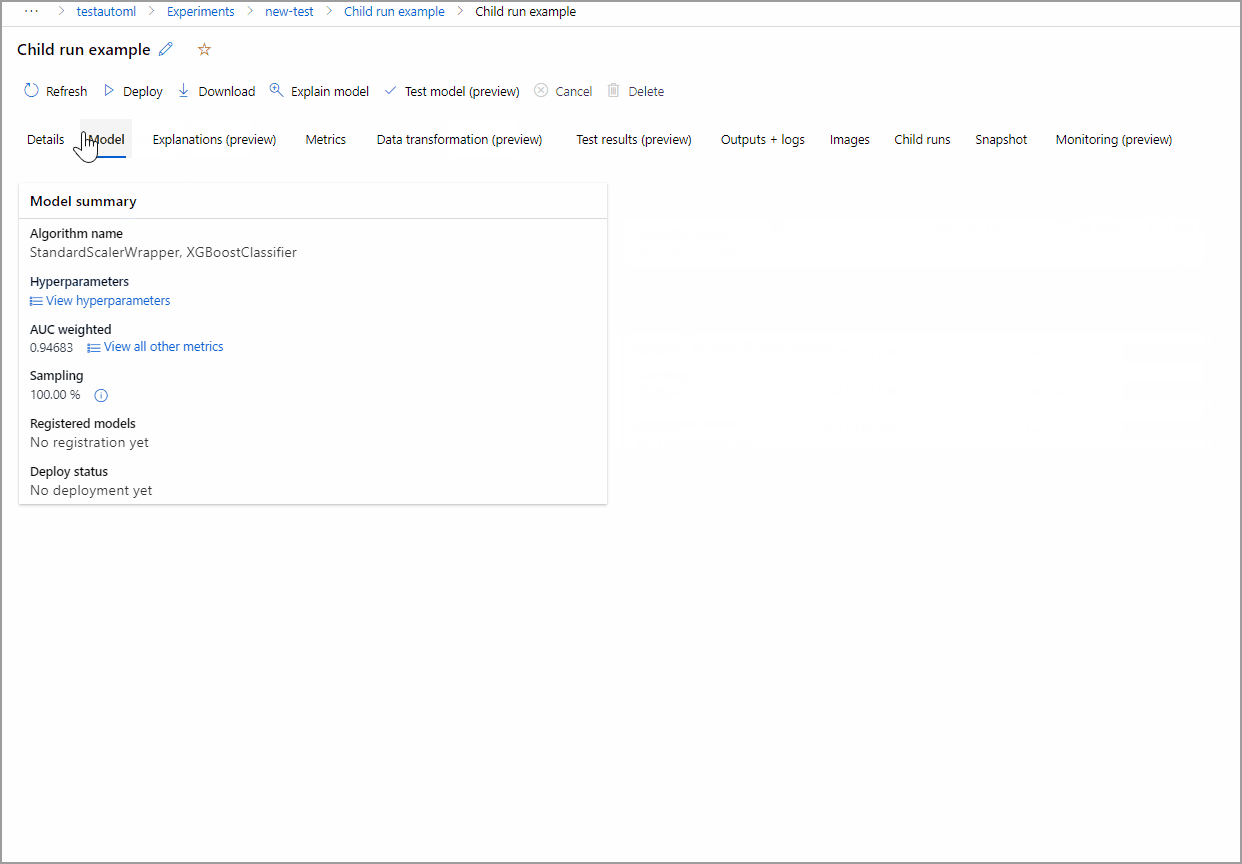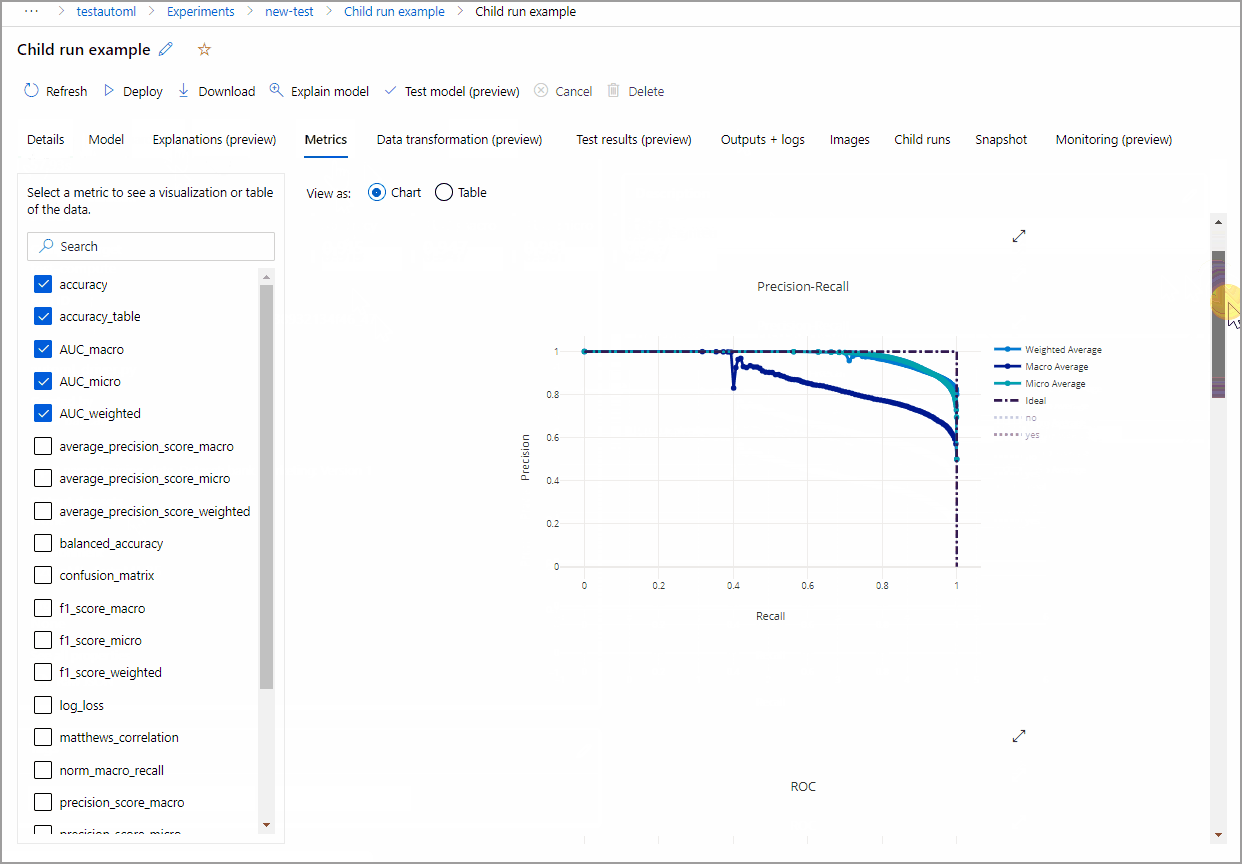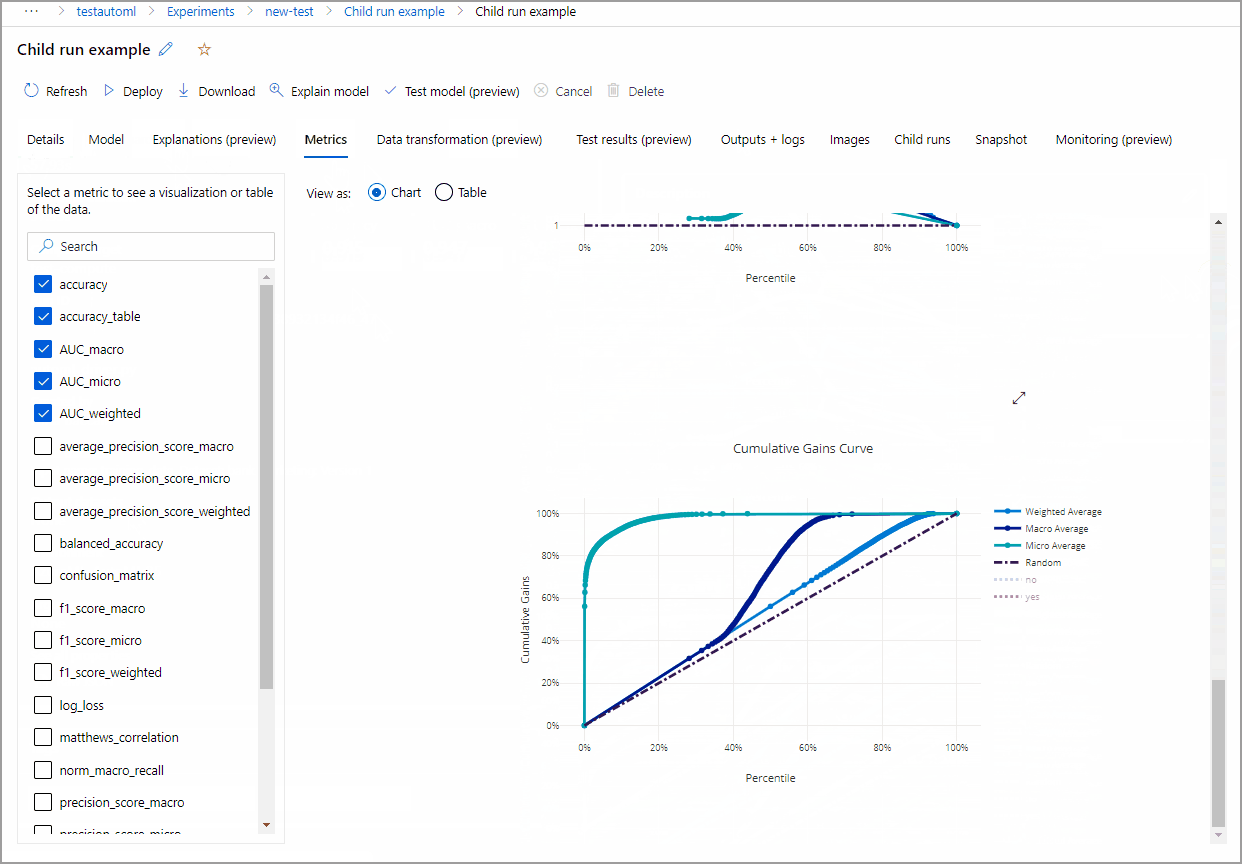
以下示例进行导航,从作业创建的模型列表中选择模型。 然后,选择“概述”和“指标”选项卡,查看选定模型的属性、指标和性能图表。
部署模型
Azure 机器学习工作室中的自动化机器学习可以通过几个步骤将最佳模型部署为 Web 服务。 部署是模型的集成,因此它可以对新数据进行预测并识别潜在的机会领域。
在此试验中部署到 Web 服务后,单车共享公司即会获得一个迭代且可缩放的 Web 解决方案,可以预测共享单车的租赁需求。
作业完成后,选择屏幕顶部的“作业 1”导航回父作业页。
在“最佳模型摘要”部分中,根据“标准化均方根误差”指标,选择此试验背景下的最佳模型。
我们将部署此模型,但请注意,部署需要大约 20 分钟才能完成。 部署过程需要几个步骤,包括注册模型、生成资源和为 Web 服务配置资源。
选择该最佳模型,以打开特定于模型的页。
选择位于屏幕左上角的“部署”按钮。
按如下所示填充“部署模型”窗格:
字段 值 部署名称 bikeshare-deploy 部署说明 单车共享需求部署 计算类型 选择“Azure 计算实例(ACI)” 启用身份验证 禁用。 使用自定义部署资产 禁用。 禁用此选项可以自动生成默认驱动程序文件(评分脚本)和环境文件。 本示例使用“高级”菜单中提供的默认值。
选择“部署”。
“作业”屏幕的顶部会以绿色字体显示一条成功消息,指出部署已成功启动。 可以在“部署状态”下的“模型摘要”窗格中找到部署进度。
部署成功后,即会获得一个正常运行的、可以生成预测结果的 Web 服务。
转到后续步骤详细了解如何使用新的 Web 服务,以及如何使用 Power BI 的内置 Azure 机器学习支持来测试预测。
清理资源
部署文件比数据文件和试验文件更大,因此它们的存储成本也更大。 仅当你想要最大程度地降低帐户成本,或者想要保留工作区和试验文件时,才删除部署文件。 否则,如果你不打算使用任何文件,请删除整个资源组。
删除部署实例
若要保留资源组和工作区以便在其他教程和探索中使用,请仅从 Azure 机器学习工作室中删除部署实例。
转到 Azure 机器学习工作室。 导航到你的工作区,然后在“资产”窗格的左下角选择“终结点”。
选择要删除的部署,然后选择“删除”。
选择“继续”。
删除资源组
重要
已创建的资源可用作其他 Azure 机器学习教程和操作方法文章的先决条件。
如果你不打算使用已创建的任何资源,请删除它们,以免产生任何费用:
在 Azure 门户的搜索框中输入“资源组”,然后从结果中选择它。
从列表中选择你创建的资源组。
在“概述”页面上,选择“删除资源组”。
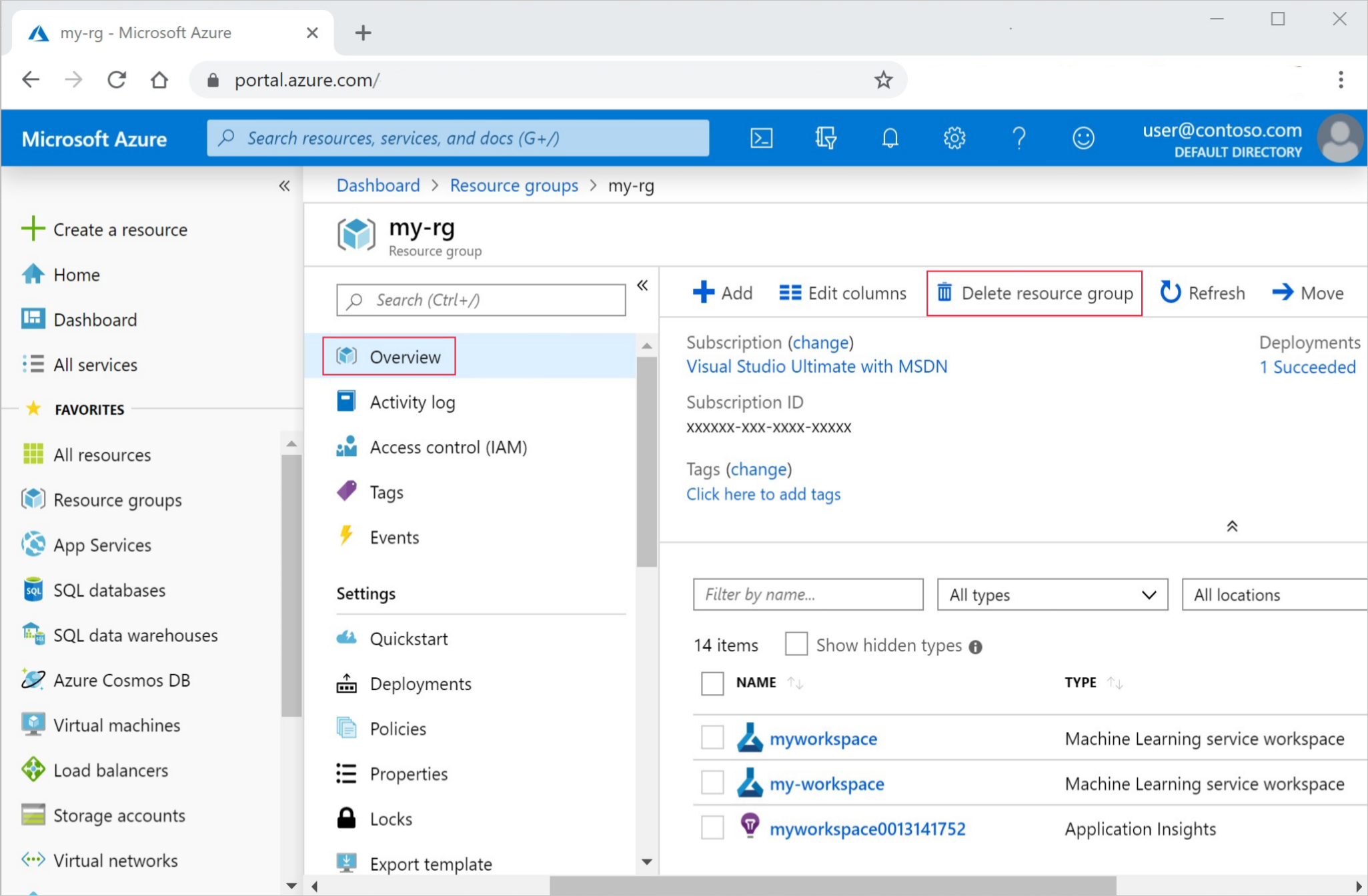
输入资源组名称。 然后选择“删除”。
后续步骤
在本教程中,你已使用 Azure 机器学习工作室中的自动化 ML 创建并部署了一个可预测单车共享租赁需求的时序预测模型。
请参阅以下文章中的步骤来创建 Power BI 支持的架构,以方便使用新部署的 Web 服务:
- 详细了解自动化机器学习。
- 有关分类指标和图表的详细信息,请参阅理解自动化机器学习结果一文。
注意
此单车共享数据集已根据本教程修改。 此数据集是作为 Kaggle 竞赛的一部分提供的,最初通过 Capital Bikeshare 提供。 也可以在 UCI 机器学习数据库中找到它。
源:Fanaee-T、Hadi、Gama 和 Joao:合并系综检测器的事件标签和背景知识;人工智能的进步 (2013):pp. 1-15,Springer Berlin Heidelberg。