在 Azure 机器学习中提交 Spark 作业
适用范围: Azure CLI ml 扩展 v2(最新版)Python SDK azure-ai-ml v2(最新版)
Azure CLI ml 扩展 v2(最新版)Python SDK azure-ai-ml v2(最新版)
Azure 机器学习支持提交独立的机器学习作业,以及创建涉及多个机器学习工作流步骤的机器学习管道。 Azure 机器学习处理独立的 Spark 作业创建,以及可供 Azure 机器学习管道使用的可重用 Spark 组件的创建。 本文介绍如何使用以下方式提交 Spark 作业:
- Azure 机器学习工作室 UI
- Azure 机器学习 CLI
- Azure 机器学习 SDK
有关 Azure 机器学习中 Apache Spark 概念的详细信息,请访问此资源。
先决条件
- Azure 订阅;如果没有 Azure 订阅,请在开始前创建试用版帐户。
- 一个 Azure 机器学习工作区。 有关详细信息,请访问创建工作区资源。
- 创建 Azure 机器学习计算实例。
- 安装 Azure 机器学习 CLI。
- (可选):Azure 机器学习工作区中附加的 Synapse Spark 池。
使用 CLI v2 附加用户分配的托管标识
- 创建 YAML 文件,该文件用于定义应附加到工作区的用户分配的托管标识:
identity: type: system_assigned,user_assigned tenant_id: <TENANT_ID> user_assigned_identities: '/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>': {} - 使用
--file参数,使用az ml workspace update命令中的 YAML 文件以附加用户分配的托管标识:az ml workspace update --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --name <AML_WORKSPACE_NAME> --file <YAML_FILE_NAME>.yaml
使用 ARMClient 附加用户分配的托管标识
- 安装
ARMClient,这是调用 Azure 资源管理器 API 的简单命令行工具。 - 创建 JSON 文件,该文件用于定义应附加到工作区的用户分配的托管标识:
{ "properties":{ }, "location": "<AZURE_REGION>", "identity":{ "type":"SystemAssigned,UserAssigned", "userAssignedIdentities":{ "/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>": { } } } } - 若要将用户分配的托管标识附加到工作区,请在 PowerShell 提示符或命令提示符下执行以下命令。
armclient PATCH https://management.chinacloudapi.cn/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>?api-version=2022-05-01 '@<JSON_FILE_NAME>.json'
注意
- 为确保成功执行 Spark 作业,请将用于数据输入和输出的 Azure 存储帐户上的“参与者”和“存储 Blob 数据参与者”角色分配给 Spark 作业所使用的标识
- 应在 Azure Synapse 工作区中启用公用网络访问,确保使用附加的 Synapse Spark 池成功执行 Spark 作业。
- 无服务器 Spark 计算支持 Azure 机器学习托管虚拟网络。 如果为无服务器 Spark 计算预配了托管网络,则还应为存储帐户预配相应的专用终结点,以确保数据访问。
提交独立的 Spark 作业
在针对 Python 脚本参数化进行必要的更改后,可以使用通过交互式数据整理开发的 Python 脚本提交批处理作业,以处理更大量的数据。 可以将数据整理批处理作业作为独立的 Spark 作业提交。
Spark 作业需要采用参数的 Python 脚本。 可以修改最初通过交互式数据整理开发的 Python 代码,以开发该脚本。 此处显示了一个示例 Python 脚本。
# titanic.py
import argparse
from operator import add
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
parser = argparse.ArgumentParser()
parser.add_argument("--titanic_data")
parser.add_argument("--wrangled_data")
args = parser.parse_args()
print(args.wrangled_data)
print(args.titanic_data)
df = pd.read_csv(args.titanic_data, index_col="PassengerId")
imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy(
"mean"
) # Replace missing values in Age column with the mean value
df.fillna(
value={"Cabin": "None"}, inplace=True
) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
df.to_csv(args.wrangled_data, index_col="PassengerId")
注意
此 Python 代码示例使用 pyspark.pandas。 只有 Spark 运行时版本 3.2 或更高版本才支持此功能。
此脚本采用两个参数,分别传递输入数据和输出文件夹的路径:
--titanic_data--wrangled_data
若要创建作业,可以将独立的 Spark 作业定义为 YAML 规范文件,该文件可以在带有 --file 参数的 az ml job create 命令中使用。 在 YAML 文件中定义这些属性:
Spark 作业规范中的 YAML 属性
type- 设置为spark。code- 定义包含此作业的源代码和脚本的文件夹的位置。entry- 定义作业的入口点。 它应涵盖以下属性之一:file- 定义用作作业入口点的 Python 脚本的名称。class_name- 定义用作作业入口点的类的名称。
py_files- 定义要放置在PYTHONPATH中的.zip、.egg或.py文件的列表,以便成功执行作业。 此属性是可选的。jars- 定义要包含在 Spark 驱动程序和执行程序CLASSPATH上的.jar文件列表,以便成功执行作业。 此属性是可选的。files- 定义应复制到每个执行程序的工作目录的文件列表,以便成功执行作业。 此属性是可选的。archives- 定义应提取到每个执行程序的工作目录中的存档列表,以便成功执行作业。 此属性是可选的。conf- 定义以下 Spark 驱动程序和执行程序属性:spark.driver.cores:Spark 驱动程序的核心数。spark.driver.memory:为 Spark 驱动程序分配的内存,以千兆字节 (GB) 为单位。spark.executor.cores:Spark 执行程序的核心数。spark.executor.memory:Spark 执行程序的内存分配,以千兆字节 (GB) 为单位。spark.dynamicAllocation.enabled- 是否应动态分配执行程序,作为True或False值。- 如果启用了执行程序的动态分配,请定义以下属性:
spark.dynamicAllocation.minExecutors- 用于动态分配的 Spark 执行程序实例的最小数目。spark.dynamicAllocation.maxExecutors- 用于动态分配的 Spark 执行程序实例的最大数目。
- 如果禁用了执行程序的动态分配,请定义此属性:
spark.executor.instances- Spark 执行程序实例的数目。
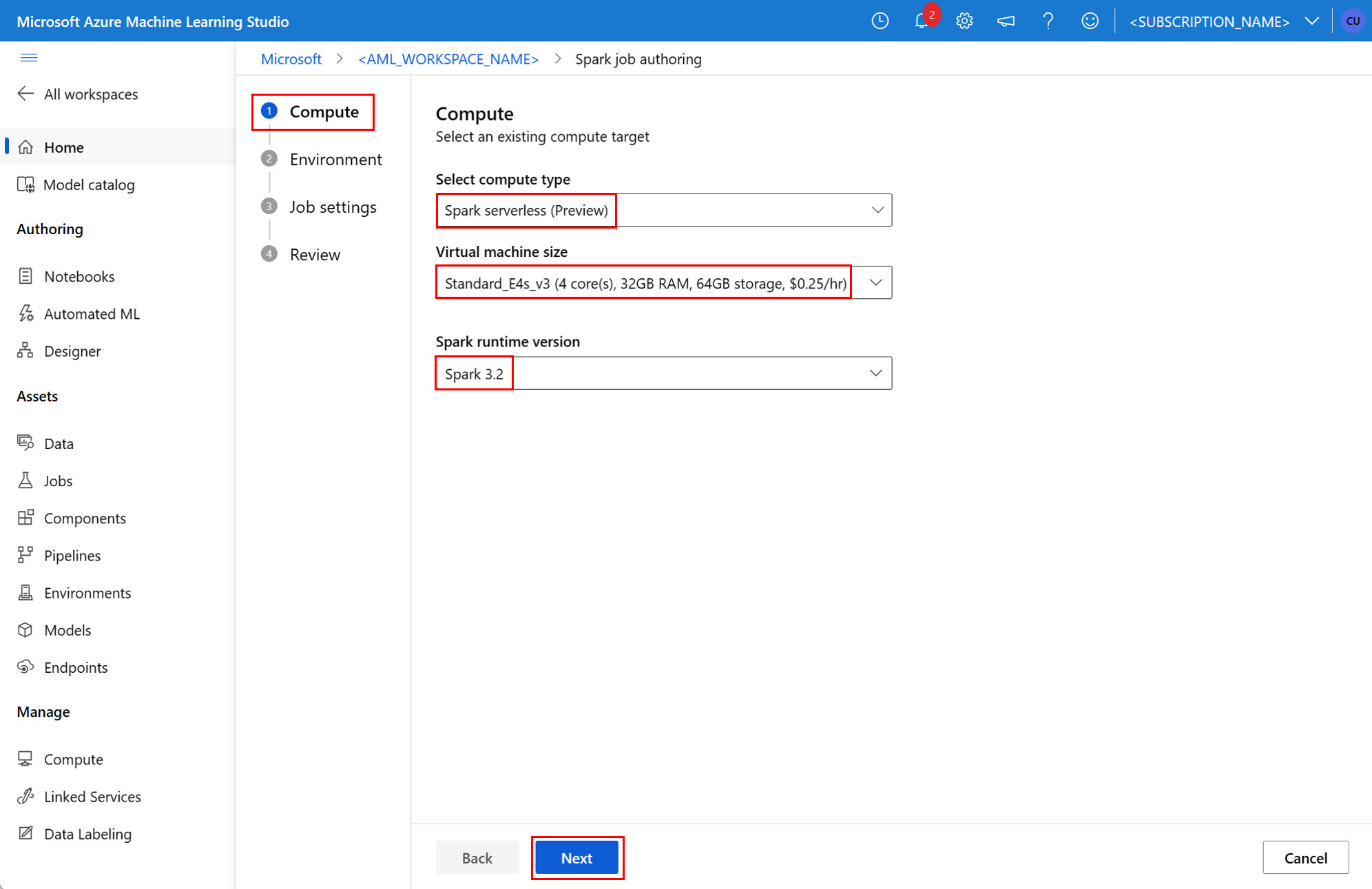
environment- 用于运行作业的 Azure 机器学习环境。args- 应传递给作业入口点 Python 脚本的命令行参数。 有关示例,请查看此处提供的 YAML 规范文件。resources- 此属性定义 Azure 机器学习无服务器 Spark 计算要使用的资源。 它使用以下属性:instance_type- 要用于 Spark 池的计算实例类型。 目前支持以下实例类型:standard_e4s_v3standard_e8s_v3standard_e16s_v3standard_e32s_v3standard_e64s_v3
runtime_version- 定义 Spark 运行时版本。 当前支持以下 Spark 运行时版本:3.33.4重要
适用于 Apache Spark 的 Azure Synapse 运行时:公告
- 适用于 Apache Spark 3.3 的 Azure Synapse 运行时:
- EOLA 公告日期:2024 年 7 月 12 日
- 支持终止日期:2025 年 3 月 31 日。 在此日期之后,将会禁用运行时。
- 为了获取持续支持和最佳性能,建议迁移到 Apache Sark 3.4。
- 适用于 Apache Spark 3.3 的 Azure Synapse 运行时:
这是一个示例 YAML 文件:
resources: instance_type: standard_e8s_v3 runtime_version: "3.4"compute- 此属性定义附加的 Synapse Spark 池的名称,如本例所示:compute: mysparkpoolinputs- 此属性定义 Spark 作业的输入。 Spark 作业的输入可以是文本值,也可以是存储在文件或文件夹中的数据。- 文本值可以是数字、布尔值或字符串。 下面显示了一些示例:
inputs: sampling_rate: 0.02 # a number hello_number: 42 # an integer hello_string: "Hello world" # a string hello_boolean: True # a boolean value - 应使用以下属性定义存储在文件或文件夹中的数据 :
type- 对于包含在文件或文件夹中的输入数据,将此属性分别设置为uri_file或uri_folder。path- 输入数据的 URI,例如azureml://、abfss://或wasbs://。mode- 将此属性设置为direct。 此示例显示了作业输入的定义,可称为$${inputs.titanic_data}}:inputs: titanic_data: type: uri_file path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv mode: direct
- 文本值可以是数字、布尔值或字符串。 下面显示了一些示例:
outputs- 此属性定义 Spark 作业输出。 Spark 作业的输出可以写入文件或文件夹位置,这是使用以下三个属性定义的:type- 可以将此属性设置为uri_file或uri_folder,以分别将输出数据写入文件或文件夹。path- 此属性定义输出位置 URI,例如azureml://、abfss://或wasbs://。mode- 将此属性设置为direct。 此示例显示作业输出的定义,可以将其称为${{outputs.wrangled_data}}:outputs: wrangled_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/data/wrangled/ mode: direct
identity- 此可选属性定义用于提交此作业的标识。 它可以有user_identity和managed值。 如果 YAML 规范未定义标识,则 Spark 作业将使用默认标识。
独立 Spark 作业
此示例 YAML 规范显示了一个独立的 Spark 作业。 它使用 Azure 机器学习无服务器 Spark 计算:
$schema: http://azureml/sdk-2-0/SparkJob.json
type: spark
code: ./
entry:
file: titanic.py
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.executor.instances: 2
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
identity:
type: user_identity
resources:
instance_type: standard_e4s_v3
runtime_version: "3.4"
注意
若要使用附加的 Synapse Spark 池,请在上面所示的示例 YAML 规范文件中定义 compute 属性,而不是 resources 属性。
如下所示,可以在带有 --file 参数的 az ml job create 命令中使用上面显示的 YAML 文件,以创建独立的 Spark 作业:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
可从以下位置执行上述命令:
- Azure 机器学习计算实例终端。
- 连接到 Azure 机器学习计算实例的 Visual Studio Code 终端。
- 安装了 Azure 机器学习 CLI 的本地计算机。
管道作业中的 Spark 组件
使用 Spark 组件可在多个 Azure 机器学习管道中灵活地使用同一组件作为管道步骤。
Spark 组件的 YAML 语法在大多数方面类似于 Spark 作业规范的 YAML 语法。 这些属性在 Spark 组件 YAML 规范中的定义不同:
name- Spark 组件的名称。version- Spark 组件的版本。display_name- 要显示在 UI 和其他位置的 Spark 组件的名称。description- Spark 组件的说明。inputs- 此属性类似于 Spark 作业规范的 YAML 语法中描述的inputs属性,只是它不定义path属性。 以下代码片段显示了 Spark 组件inputs属性的示例:inputs: titanic_data: type: uri_file mode: directoutputs- 此属性类似于 Spark 作业规范的 YAML 语法中描述的outputs属性,只是它不定义path属性。 以下代码片段显示了 Spark 组件outputs属性的示例:outputs: wrangled_data: type: uri_folder mode: direct
注意
Spark 组件不定义 identity、compute 或 resources 属性。 管道 YAML 规范文件定义这些属性。
此 YAML 规范文件提供 Spark 组件的示例:
$schema: http://azureml/sdk-2-0/SparkComponent.json
name: titanic_spark_component
type: spark
version: 1
display_name: Titanic-Spark-Component
description: Spark component for Titanic data
code: ./src
entry:
file: titanic.py
inputs:
titanic_data:
type: uri_file
mode: direct
outputs:
wrangled_data:
type: uri_folder
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.dynamicAllocation.enabled: True
spark.dynamicAllocation.minExecutors: 1
spark.dynamicAllocation.maxExecutors: 4
可以在 Azure 机器学习管道作业中使用在上述 YAML 规范文件中定义的 Spark 组件。 请访问管道作业 YAML 架构资源,以详细了解定义管道作业的 YAML 语法。 此示例显示了管道作业的 YAML 规范文件,其中包含 Spark 组件和 Azure 机器学习无服务器 Spark 计算:
$schema: http://azureml/sdk-2-0/PipelineJob.json
type: pipeline
display_name: Titanic-Spark-CLI-Pipeline
description: Spark component for Titanic data in Pipeline
jobs:
spark_job:
type: spark
component: ./spark-job-component.yaml
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
identity:
type: managed
resources:
instance_type: standard_e8s_v3
runtime_version: "3.4"
注意
若要使用附加的 Synapse Spark 池,请在上面所示的示例 YAML 规范文件中定义 compute 属性,而不是 resources 属性。
如下所示,可以在带有 --file 参数的 az ml job create 命令中使用上述 YAML 规范文件,以创建管道作业:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
可从以下位置执行上述命令:
- Azure 机器学习计算实例终端。
- 安装了 Azure 机器学习 CLI 的本地计算机。
排查 Spark 作业问题
若要排查 Spark 作业问题,可以在 Azure 机器学习工作室中访问为该作业生成的日志。 若要查看 Spark 作业的日志,请执行以下操作:
- 导航到 Azure 机器学习工作室 UI 左侧面板中的“作业”
- 选择“所有作业”选项卡
- 选择作业的“显示名称”值
- 在作业详细信息页上,选择“输出 + 日志”选项卡
- 在文件资源管理器中,展开 logs 文件夹,然后展开 azureml 文件夹
- 访问 driver 和 library manager 文件夹中的 Spark 作业日志
注意
若要对在笔记本会话中交互式数据整理期间创建的 Spark 作业进行故障排除,请选择笔记本 UI 右上角附近的“作业详细信息”。 交互式笔记本会话中的 Spark 作业是在试验名称 notebook-runs 下创建的。