访问作业中的数据
适用范围: Azure CLI ml 扩展 v2(最新版)Python SDK azure-ai-ml v2(最新版)
Azure CLI ml 扩展 v2(最新版)Python SDK azure-ai-ml v2(最新版)
本文内容:
- 如何在 Azure 机器学习作业中从 Azure 存储读取数据。
- 如何将 Azure 机器学习作业中的数据写入 Azure 存储。
- 装载和下载模式之间的差异。
- 如何使用用户标识和托管标识访问数据。
- 作业中可用的装载设置。
- 常见方案的最佳装载设置。
- 如何访问 V1 数据资产。
先决条件
Azure 订阅。 如果没有 Azure 订阅,请在开始前创建一个试用版订阅。 尝试试用版订阅。
Azure 机器学习工作区
快速入门
我们首先介绍用于数据访问的相关代码片段,然后你就可以探索访问数据时可用的详细选项。
从 Azure 机器学习作业中的 Azure 存储读取数据
在此示例中,你将提交一个 Azure 机器学习作业,从公共 Blob 存储帐户访问数据。 但是,你可以调整代码片段,从而访问你在专用 Azure 存储帐户中拥有的数据。 按照此处的说明更新路径。 Azure 机器学习使用 Microsoft Entra 直通来无缝处理向云存储进行的身份验证。 提交作业时,你可以选择:
- 用户标识:传递访问数据所需的 Microsoft Entra 标识
- 托管标识:使用计算目标的托管标识访问数据
- 无:不指定用于访问数据的标识。 使用基于凭据的(密钥/SAS 令牌)数据存储或访问公共数据时,请使用“无”
提示
如果你使用密钥或 SAS 令牌进行身份验证,建议创建 Azure 机器学习数据存储,因为运行时会自动连接到存储,而不会公开密钥/令牌。
from azure.ai.ml import command, Input, MLClient, UserIdentityConfiguration, ManagedIdentityConfiguration
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.chinacloudapi.cn/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.chinacloudapi.cn/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# We set the input path to a file on a public blob container
# ==============================================================
path = "wasbs://data@azuremlexampledata.blob.core.chinacloudapi.cn/titanic.csv"
# ==============================================================
# What type of data does the path point to? Options include:
# data_type = AssetTypes.URI_FILE # a specific file
# data_type = AssetTypes.URI_FOLDER # a folder
# data_type = AssetTypes.MLTABLE # an mltable
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the mode. The popular modes include:
# mode = InputOutputModes.RO_MOUNT # Read-only mount on the compute target
# mode = InputOutputModes.DOWNLOAD # Download the data to the compute target
# ==============================================================
mode = InputOutputModes.RO_MOUNT
# ==============================================================
# You can set the identity you want to use in a job to access the data. Options include:
# identity = UserIdentityConfiguration() # Use the user's identity
# identity = ManagedIdentityConfiguration() # Use the compute target managed identity
# ==============================================================
# This example accesses public data, so we don't need an identity.
# You also set identity to None if you use a credential-based datastore
identity = None
# Set the input for the job:
inputs = {
"input_data": Input(type=data_type, path=path, mode=mode)
}
# This command job uses the head Linux command to print the first 10 lines of the file
job = command(
command="head ${{inputs.input_data}}",
inputs=inputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
identity=identity,
)
# Submit the command
ml_client.jobs.create_or_update(job)
将数据从 Azure 机器学习作业写入 Azure 存储
在此示例中,你将提交一个 Azure 机器学习作业,将数据写入默认的 Azure 机器学习数据存储。 可选择性地设置数据资产的 name 值,以在输出中创建数据资产。
from azure.ai.ml import command, Input, Output, MLClient
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.chinacloudapi.cn/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.chinacloudapi.cn/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# As an example, we set the input path to a file on a public blob container
# As an example, we set the output path to a folder in the default datastore
# ==============================================================
input_path = "wasbs://data@azuremlexampledata.blob.core.chinacloudapi.cn/titanic.csv"
output_path = "azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv"
# ==============================================================
# What type of data are you pointing to?
# AssetTypes.URI_FILE (a specific file)
# AssetTypes.URI_FOLDER (a folder)
# AssetTypes.MLTABLE (a table)
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the input mode. The most commonly-used modes:
# InputOutputModes.RO_MOUNT
# InputOutputModes.DOWNLOAD
# Set the mode to Read Only (RO) to mount the data
# ==============================================================
input_mode = InputOutputModes.RO_MOUNT
# ==============================================================
# Set the output mode. The most commonly-used modes:
# InputOutputModes.RW_MOUNT
# InputOutputModes.UPLOAD
# Set the mode to Read Write (RW) to mount the data
# ==============================================================
output_mode = InputOutputModes.RW_MOUNT
# Set the input and output for the job:
inputs = {
"input_data": Input(type=data_type, path=input_path, mode=input_mode)
}
outputs = {
"output_data": Output(type=data_type,
path=output_path,
mode=output_mode,
# optional: if you want to create a data asset from the output,
# then uncomment `name` (`name` can be set without setting `version`, and in this way, we will set `version` automatically for you)
# name = "<name_of_data_asset>", # use `name` and `version` to create a data asset from the output
# version = "<version>",
)
}
# This command job copies the data to your default Datastore
job = command(
command="cp ${{inputs.input_data}} ${{outputs.output_data}}",
inputs=inputs,
outputs=outputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
)
# Submit the command
ml_client.jobs.create_or_update(job)
Azure 机器学习数据运行时
提交作业时,Azure 机器学习数据运行时会控制从存储位置到计算目标的数据加载。 Azure 机器学习数据运行时经过优化,可快速高效地执行机器学习任务。 主要优点包括:
- 数据加载是用 Rust 语言编写的,该语言以高速和高内存效率而闻名。 对于并发数据下载,Rust 避免了 Python 全局解释器锁 (GIL) 问题。
- 轻量级;Rust 不依赖于 JVM 等其他技术。 因此,运行时可快速安装,并且不会耗尽计算目标上的额外资源(CPU、内存)
- 多进程(并行)数据加载
- 作为 CPU 上的后台任务进行数据预提取,以便在进行深度学习时更好地利用 GPU
- 对云存储的无缝身份验证处理
- 提供装载数据(流式传输)或下载所有数据的选项。 有关详细信息,请访问装载(流式处理)和下载部分。
- 与 fsspec 无缝集成 - 本地、远程和嵌入式文件系统和字节存储的统一 python 式接口。
提示
建议利用 Azure 机器学习数据运行时,而不是在训练(客户端)代码中创建自己的装载/下载功能。 我们观察到,由于全局解释器锁 (GIL) 的问题,当客户端代码使用 Python 从存储下载数据时,存储吞吐量会出现受限的情况。
路径
向作业提供数据输入/输出时,必须指定指向数据位置的 path 参数。 下表显示了 Azure 机器学习支持的不同数据位置,还显示了 path 参数示例:
| 位置 | 示例 | 输入 | 输出 |
|---|---|---|---|
| 本地计算机上的路径 | ./home/username/data/my_data |
Y | N |
| 公共 http (s) 服务器上的路径 | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
Y | N |
| Azure 存储上的路径 | wasbs://<container_name>@<account_name>.blob.core.chinacloudapi.cn/<path>abfss://<file_system>@<account_name>.dfs.core.chinacloudapi.cn/<path> |
Y,仅适用于基于标识的身份验证。 | N |
| Azure 机器学习数据存储上的路径 | azureml://datastores/<data_store_name>/paths/<path> |
Y | Y |
| 数据资产的路径 | azureml:<my_data>:<version> |
Y | N,但可以使用 name 和 version 从输出创建数据资产 |
模式
使用数据输入/输出运行作业时,可以从以下模式选项中进行选择:
ro_mount:在本地磁盘 (SSD) 计算目标上将存储位置装载为“只读”。rw_mount:在本地磁盘 (SSD) 计算目标上将存储位置装载为“读写”。download:将数据从存储位置下载到本地磁盘 (SSD) 计算目标。upload: 将数据从计算目标上传到存储位置。eval_mount/eval_download:这些模式对 MLTable 来说是唯一的。在某些情况下,MLTable 可生成可能不位于托管 MLTable 文件的存储帐户,而是位于其他存储帐户中的文件。 或者,MLTable 可以对位于存储资源中的数据进行子集选择或混洗。 仅当 Azure 机器学习数据运行时评估 MLTable 文件时,子集/混洗视图才可见。 例如,此图显示了与eval_mount或eval_download一起使用的 MLTable 如何从两个不同的存储容器和位于不同存储帐户中的注释文件获取映像,然后装载/下载到远程计算目标的文件系统。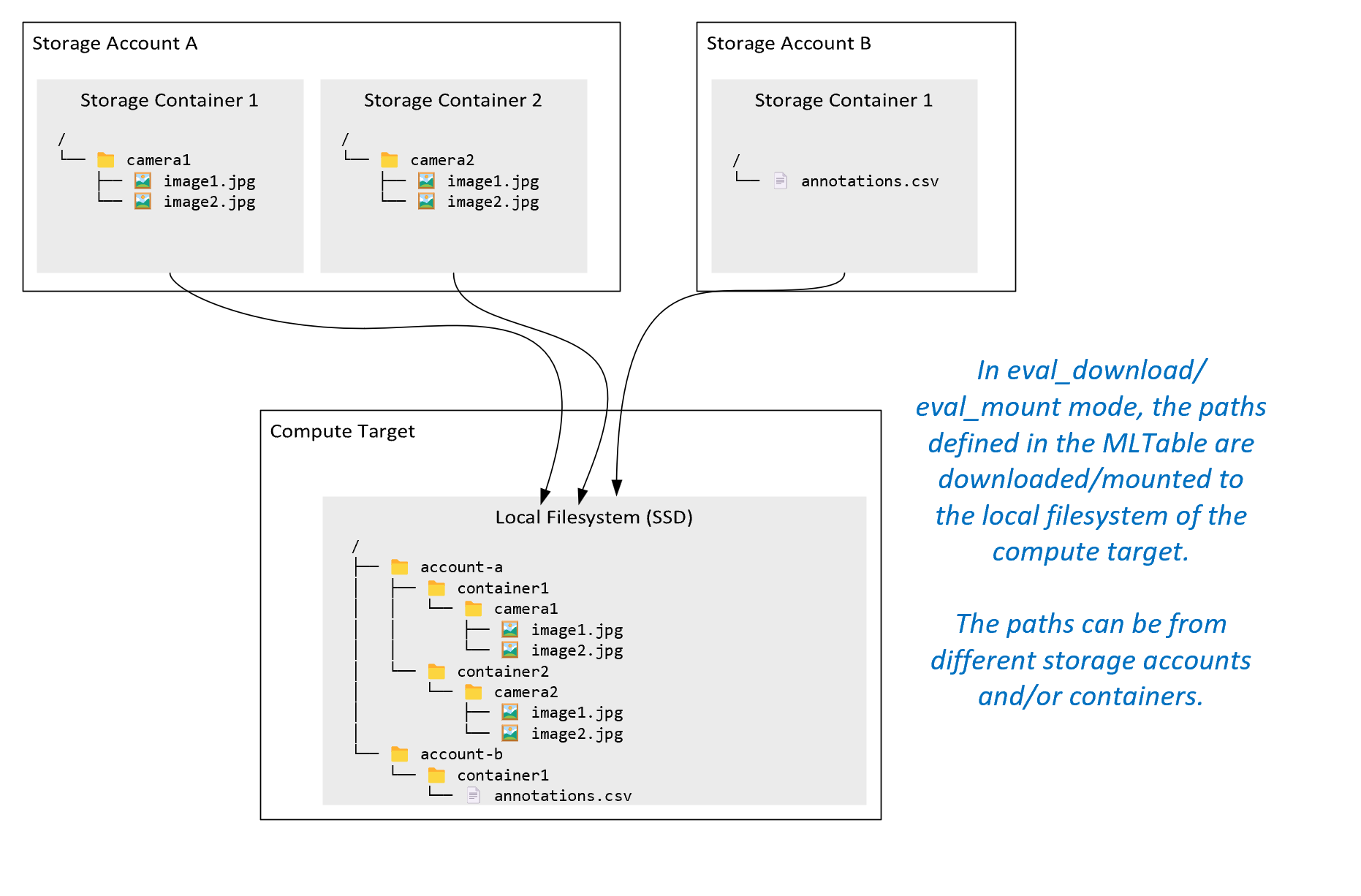
然后,可以在计算目标的文件系统上访问文件夹结构中的
camera1文件夹、camera2文件夹和annotations.csv文件:/INPUT_DATA ├── account-a │ ├── container1 │ │ └── camera1 │ │ ├── image1.jpg │ │ └── image2.jpg │ └── container2 │ └── camera2 │ ├── image1.jpg │ └── image2.jpg └── account-b └── container1 └── annotations.csvdirect:你可能想要通过其他 API 直接从 URI 读取数据,而不是通过 Azure 机器学习数据运行时。 例如,你可能想要使用 boto s3 客户端(通过虚拟托管样式或路径样式httpsURL)访问 s3 Bucket 上的数据。 可使用direct模式以字符串的形式获取输入的 URI。 你会看到在 Spark 作业中使用了直接模式,因为spark.read_*()方法知道如何处理 URI。 对于非 Spark 作业,由你负责管理访问凭据。 例如,必须显式使用计算 MSI,否则必须使用代理访问。

此表显示了不同类型/模式/输入/输出组合的可能模式:
| 类型 | 输入/输出 | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|---|
uri_folder |
输入 | ✓ | ✓ | ✓ | ||||
uri_file |
输入 | ✓ | ✓ | ✓ | ||||
mltable |
输入 | ✓ | ✓ | ✓ | ✓ | ✓ | ||
uri_folder |
输出 | ✓ | ✓ | |||||
uri_file |
输出 | ✓ | ✓ | |||||
mltable |
输出 | ✓ | ✓ | ✓ |
下载
在下载模式下,所有输入数据将复制到计算目标的本地磁盘 (SSD)。 复制所有数据后,Azure 机器学习数据运行时将启动用户训练脚本。 用户脚本启动时,会像读取任何其他文件一样从本地磁盘读取数据。 作业完成后,将从计算目标的磁盘中删除数据。
| 优点 | 缺点 |
|---|---|
| 训练开始时,训练脚本可在计算目标的本地磁盘 (SSD) 上使用所有数据。 不需要 Azure 存储/网络交互。 | 数据集必须完全适合计算目标磁盘。 |
| 用户脚本启动后,不依赖于存储/网络可靠性。 | 会下载整个数据集(如果训练只需要随机选择一小部分数据,那么大部分下载都将浪费)。 |
| Azure 机器学习数据运行时可以并行下载(在许多小文件上有显著的区别),并最大限度地提高网络/存储吞吐量。 | 作业将等待,直到所有数据都下载到计算目标的本地磁盘。 对于提交的深度学习作业,GPU 将空闲,直到数据准备就绪。 |
| FUSE 层没有添加不可避免的开销(往返:用户脚本中的用户空间调用 → 内核 → 用户空间 fuse 守护程序 → 内核 → 用户空间中对用户脚本的响应) | 下载完成后,存储更改不会反映在数据上。 |
何时使用下载
- 数据足够小,可以放在计算目标的磁盘上而不会干扰其他训练
- 训练使用大部分或全部数据集
- 训练会多次从数据集读取文件
- 训练必须跳转到大型文件的随机位置
- 可以等待所有数据下载,然后再开始训练
可用的下载设置
可以在作业中使用以下环境变量来优化下载设置:
| 环境变量名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
RSLEX_DOWNLOADER_THREADS |
u64 | NUMBER_OF_CPU_CORES * 4 |
下载可以使用的并发线程数 |
AZUREML_DATASET_HTTP_RETRY_COUNT |
u64 | 7 | 从暂时性错误中恢复的单个存储 / http 请求的重试次数。 |
在作业中,可以通过设置环境变量来更改上述默认值,例如:
为简洁起见,我们只演示如何在作业中定义环境变量。
from azure.ai.ml import command
env_var = {
"RSLEX_DOWNLOADER_THREADS": 64,
"AZUREML_DATASET_HTTP_RETRY_COUNT": 10
}
job = command(
environment_variables=env_var
)
下载性能指标
计算目标的 VM 大小会影响数据的下载时间。 具体而言:
- 核心数。 可用核心数越多,并发性越多,进而下载速度更快。
- 预期网络带宽。 Azure 中的每个 VM 都具有网络接口卡 (NIC) 的最大吞吐量。
注意
对于 A100 GPU VM,在将数据下载到计算目标时(约 24 Gbit/s),Azure 机器学习数据运行时可能会使 NIC(网络接口卡)饱和:理论上可能的最大吞吐量。
下表显示了 Azure 机器学习数据运行时在 Standard_D15_v2 VM(20 个核心、25 Gbit/s 的网络吞吐量)上针对 100 GB 文件可以处理的下载性能:
| 数据结构 | 仅下载(秒) | 下载并计算 MD5(秒) | 实现的吞吐量 (Gbit/s) |
|---|---|---|---|
| 10 x 10 GB 文件 | 55.74 | 260.97 | 14.35 Gbit/s |
| 100 x 1 GB 文件 | 58.09 | 259.47 | 13.77 Gbit/s |
| 1 x 100 GB 文件 | 96.13 | 300.61 | 8.32 Gbit/s |
我们可以看到,由于并行性,将较大的文件分解为较小的文件时,可以提高下载性能。 建议避免使用变得太小(小于 4 MB)的文件,因为那样的话,存储请求提交所花费的时间相对于下载有效负载的时间会增加。 有关详细信息,请阅读许多小文件问题。
装载(流式处理)
在装载模式下,Azure 机器学习数据功能使用 FUSE(用户空间中的文件系统)Linux 功能来创建模拟的文件系统。 运行时可以实时响应用户的脚本操作,而不是将所有数据下载到计算目标的本地磁盘 (SSD)。 例如,“打开文件”、“从位置 X 读取 2 KB 区块”、“列出目录内容”。
| 优点 | 缺点 |
|---|---|
| 可能会使用超出计算目标本地磁盘容量的数据(不受计算硬件限制) | 增加了 Linux FUSE 模块的开销。 |
| 训练开始时没有延迟(与下载模式不同)。 | 对用户代码行为的依赖(如果按顺序读取单个线程装载中的小文件的训练代码也从存储请求数据,则可能无法最大化网络或存储吞吐量)。 |
| 更多可用于优化使用方案的设置。 | 无 Windows 支持。 |
| 仅从存储中读取训练所需的数据。 |
何时使用装载
- 数据很大,不适合放在计算目标本地磁盘上。
- 群集中的每个计算节点不需要读取整个数据集(随机文件或 csv 文件选择中的行等)。
- 在训练开始前等待所有数据下载所带来的延迟可能会成为问题(空闲 GPU 时间)。
可用的装载设置
可以在作业中使用以下环境变量来优化装载设置:
| Env 变量名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL |
u64 | 未设置(缓存永远不会过期) | 将 getattr 调用结果保留在缓存中所需的时间(毫秒),目的是避免之后再次从存储请求此信息。 |
DATASET_RESERVED_FREE_DISK_SPACE |
u64 | 150 MB | 适用于系统配置,以保持计算正常运行。 无论其他设置有什么值,Azure 机器学习数据运行时都不会使用磁盘空间的最后 RESERVED_FREE_DISK_SPACE 个字节。 |
DATASET_MOUNT_CACHE_SIZE |
usize | 无限制 | 控制可以使用多少磁盘空间装载。 正值设置绝对值(以字节为单位)。 负值设置要留空的磁盘空间量。 此表提供了更多磁盘缓存选项。 为方便起见,支持 KB、MB、GB 修饰符。 |
DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD |
f64 | 1.0 | 当缓存填充到 AVAILABLE_CACHE_SIZE * DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD 时,卷装载将启动缓存删除。 应介于 0 和 1 之间。 将其设置为< 1 会提前触发后台缓存删除。 AVAILABLE_CACHE_SIZE 不是可以直接修改或查看的环境变量。 在此上下文中,它指的是“系统计算出的可用于缓存的字节数”。此值取决于多种因素,如磁盘大小、系统健康所需的磁盘空间量以及环境变量(如 DATASET_RESERVED_FREE_DISK_SPACE 和 DATASET_MOUNT_CACHE_SIZE)中设置的配置。 |
DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET |
f64 | 0.7 | 删除缓存操作会尝试释放至少 (1-DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET) 缓存空间。 |
DATASET_MOUNT_READ_BLOCK_SIZE |
usize | 2 MB | 流式传输读取块大小。 当文件足够大时,即使 fuse 请求的读取操作较少,也会从存储中请求至少 DATASET_MOUNT_READ_BLOCK_SIZE 的数据并进行缓存。 |
DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT |
usize | 32 | 预提取块数(读取块 k 时会在后台触发预提取块 k+1、...、k.+DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT) |
DATASET_MOUNT_READ_THREADS |
usize | NUMBER_OF_CORES * 4 |
后台预提取线程数。 |
DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED |
bool | false | 启用基于块的缓存。 |
DATASET_MOUNT_MEMORY_CACHE_SIZE |
usize | 128 MB | 仅适用于基于块的缓存。 可以使用基于 RAM 块的缓存的大小。 值为 0 会完全禁用内存缓存。 |
DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED |
bool | true | 仅适用于基于块的缓存。 设置为 true 时,基于块的缓存会使用本地硬盘驱动器来缓存块。 |
DATASET_MOUNT_BLOCK_FILE_CACHE_MAX_QUEUE_SIZE |
usize | 512 MB | 仅适用于基于块的缓存。 基于块的缓存在后台将缓存的块写入本地磁盘。 此设置控制可用于存储等待刷新到本地磁盘缓存的块的内存装载量。 |
DATASET_MOUNT_BLOCK_FILE_CACHE_WRITE_THREADS |
usize | NUMBER_OF_CORES * 2 |
仅适用于基于块的缓存。 基于块的缓存使用的后台线程的数量,使用目的是将下载的块写入计算目标的本地磁盘。 |
DATASET_UNMOUNT_TIMEOUT_SECONDS |
u64 | 30 | 在强制终止装载消息循环之前 unmount(妥善地)完成所有挂起操作(例如刷新调用)所用的时间(秒)。 |
在作业中,可以通过设置环境变量来更改上述默认值,例如:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": True
}
job = command(
environment_variables=env_var
)
基于块的打开模式
基于块的打开模式会将每个文件拆分为预定义大小的块(最后一个块除外)。 来自指定位置的读取请求从存储请求相应的块,并立即返回请求的数据。 读取还会触发接下来 N 个块的后台预提取,使用多个线程(针对顺序读取进行了优化)。 下载的块缓存在两层缓存中(RAM 和本地磁盘)。
| 优点 | 缺点 |
|---|---|
| 将数据快速传送到训练脚本(尚未被请求的区块的阻塞性较小)。 | 随机读取可能会浪费向前预提取的块。 |
| 更多的工作会卸载到后台线程(预提取/缓存)。 然后训练就可以继续进行。 | 与从本地磁盘缓存上的文件直接读取相比,增加了在缓存之间导航的开销(例如,在全文件缓存模式下)。 |
| 仅从存储中读取请求的数据(加上预提取)。 | |
| 对于足够小的数据,会使用快速的基于 RAM 的缓存。 |
何时使用基于块的打开模式
建议用于大多数方案,但需要从随机文件位置快速读取的情况除外。 在这些情况下,请使用全文件缓存打开模式。
全文件缓存打开模式
在全文件模式下打开装载文件夹下的文件(例如 f = open(path, args))时,将阻止调用,直到整个文件都下载到磁盘上的计算目标缓存文件夹中。 所有后续读取调用都会重定向到缓存的文件,因此不需要存储交互。 如果缓存没有足够的可用空间来容纳当前文件,装载会尝试通过从缓存中删除最不常用的文件来清理空间。 如果文件无法放在磁盘上(考虑到缓存设置),数据运行时将回退到流式处理模式。
| 优点 | 缺点 |
|---|---|
| 打开文件后,没有存储可靠性/吞吐量依赖项。 | 打开调用被阻止,直到下载完整个文件。 |
| 快速随机读取(从文件的随机位置读取区块)。 | 从存储中读取整个文件,即便可能不需要文件的某些部分。 |
何时使用
对于超过 128 MB 的相对大型文件需要随机读取时。
使用情况
在作业中将环境变量 DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED 设置为 false:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False
}
job = command(
environment_variables=env_var
)
装载:列出文件
处理数百万个文件时,请避免使用递归列出,例如 ls -R /mnt/dataset/folder/。 递归列出会触发许多调用来列出父目录的目录内容。 然后,它会要求在所有子级别对内部的每个目录进行单独的递归调用。 通常,Azure 存储仅允许每个列出请求返回 5000 个元素。 结果就是,如果要递归列出 100 万个文件夹,而每个文件夹包含 10 个文件,则需要向存储发出 1,000,000 / 5000 + 1,000,000 = 1,000,200 个请求。 相比之下,包含 10,000 个文件的 1,000 个文件夹只需要向存储发出 1001 个递归列出请求。
Azure 机器学习装载以延迟方式处理列出。 因此,若要列出许多小文件,最好使用迭代客户端库调用(例如 Python 中的 os.scandir()),而不是使用返回完整列表的客户端库调用(例如 Python 中的 os.listdir())。 迭代客户端库调用将返回生成器,这意味着它不需要等待整个列表加载。 所以它可以更快地进行。
下表比较了 Python os.scandir() 和 os.listdir() 函数列出包含 ~4M 平面结构文件的文件夹所需的时间:
| 指标 | os.scandir() |
os.listdir() |
|---|---|---|
| 获取第一个条目的时间(秒) | 0.67 | 553.79 |
| 获取前 5 万个条目的时间(秒) | 9.56 | 562.73 |
| 获取所有条目的时间(秒) | 558.35 | 582.14 |
常见方案的最佳装载设置
对于某些常见方案,我们显示了需要在 Azure 机器学习作业中设置的最佳装载设置。
一次按顺序读取大型文件(在 csv 文件中处理行)
在你的 Azure 机器学习作业的 environment_variables 部分中加入这些装载设置:
注意
若要使用无服务器计算,请删除此代码中的 compute="cpu-cluster",。
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
# Increase the number of blocks used for prefetch. This leads to use of more RAM (2 MB * #value set).
# Can adjust up and down for fine-tuning, depending on the actual data processing pattern.
# An optimal setting based on our test ~= the number of prefetching threads (#CPU_CORES * 4 by default)
"DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT": 80,
}
job = command(
environment_variables=env_var
)
从多个线程一次读取大型文件(在多个线程中处理分区的 csv 文件)
在你的 Azure 机器学习作业的 environment_variables 部分中加入这些装载设置:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
从多个线程一次读取数百万个小文件(图像)(对图像进行单个纪元训练)
在你的 Azure 机器学习作业的 environment_variables 部分中加入这些装载设置:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
从多个线程多次读取数百万个小文件(图像)(对图像进行多个纪元训练)
在你的 Azure 机器学习作业的 environment_variables 部分中加入这些装载设置:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
}
job = command(
environment_variables=env_var
)
读取大型文件并进行随机寻找(如从装载的文件夹中提供文件数据库)
在你的 Azure 机器学习作业的 environment_variables 部分中加入这些装载设置:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False, # Disable block-based caching
}
job = command(
environment_variables=env_var
)
诊断和解决数据加载瓶颈
对数据执行 Azure 机器学习作业时,输入的 mode 将确定如何从存储中读取字节以及如何将其缓存在计算目标本地 SSD 磁盘上。 对于下载模式,所有数据在用户代码开始执行之前都缓存在磁盘上。 因此,有一些因素,例如
- 并行线程数、
- 文件数,
- 文件大小
会对最大下载速度产生影响。 对于装载,用户代码必须在数据开始缓存之前开始打开文件。 不同的装载设置会导致不同的读取和缓存行为。 各种因素会影响数据从存储加载的速度:
- 要计算的数据位置:存储和计算目标的位置应相同。 如果存储和计算目标位于不同的区域,性能会降低,因为数据必须跨区域传输。 若要详细了解如何确保数据与计算在同一位置,请访问将数据与计算共置。
- 计算目标大小:与较大的计算大小相比,小型计算的核心数较少(并行度较低)、预期网络带宽较低 - 这两个因素都会影响数据加载性能。
- 例如, 如果使用较小的 VM 大小,例如
Standard_D2_v2(2 个核心、1500 Mbps NIC),然后尝试加载 50,000 MB (50 GB) 的数据,则可实现的最佳数据加载时间为 ~270 秒(假设 187.5 MB/s 的吞吐量使 NIC 饱和)。 相比之下,Standard_D5_v2(16 个核心、12,000 Mbps)可在 ~33 秒内加载相同的数据(假设 1500 MB/s 的吞吐量使 NIC 饱和)。
- 例如, 如果使用较小的 VM 大小,例如
- 存储层:对于大多数方案(包括大型语言模型 (LLM)),标准存储可提供最佳的成本/性能表现。 但是,如果有许多小文件,那么高级存储可提供更好的成本/性能表现。 有关详细信息,请参阅 Azure 存储选项。
- 存储负载:如果存储帐户处于高负载下(例如,请求数据的群集中有许多 GPU 节点),则存在达到存储的出口容量的风险。 有关详细信息,请阅读存储负载。 如果有许多需要并行访问的小文件,则可能会达到存储请求限制。 在标准存储帐户的缩放目标中阅读有关出口容量和存储请求限制的最新信息。
- 用户代码中的数据访问模式:使用装载模式时,将根据代码中的打开/读取操作提取数据。 例如,读取大型文件的随机部分时,装载的默认数据预提取设置可能会导致下载无法读取的块。 可能需要调整一些设置才能达到最大吞吐量。 有关详细信息,请参阅常见方案的最佳装载设置。
使用日志诊断问题
若要从作业访问数据运行时的日志:
- 从作业页中选择“输出+日志”选项卡。
- 选择 system_logs 文件夹,然后选择 data_capability 文件夹。
- 你应该会看到两个日志文件:
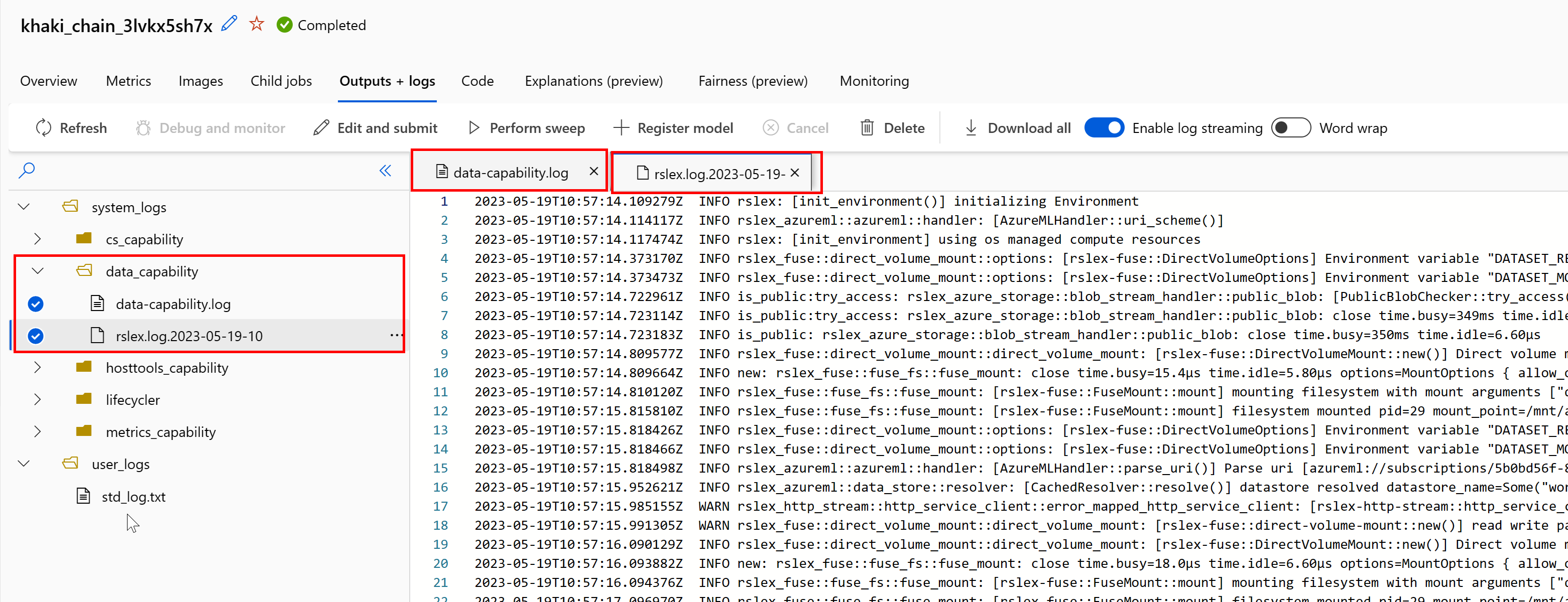

日志文件 data-capability.log 会显示有关关键数据加载任务所花费时间的概览信息。 例如,下载数据时,运行时会记录下载活动的开始和完成时间:
INFO 2023-05-18 17:14:47,790 sdk_logger.py:44 [28] - ActivityStarted, download
INFO 2023-05-18 17:14:50,295 sdk_logger.py:44 [28] - ActivityCompleted: Activity=download, HowEnded=Success, Duration=2504.39 [ms]
如果下载吞吐量是 VM 大小的预期网络带宽的一小部分,则可以检查日志文件 rslex.log.<TIMESTAMP>。 该文件包含了来自基于 Rust 的运行时的所有精细日志记录,例如并行化:
2023-05-18T14:08:25.388670Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce:get_iter: rslex::prefetching: close time.busy=23.2µs time.idle=1.90µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0 index=0
2023-05-18T14:08:25.388731Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce: rslex::dataset_crossbeam: close time.busy=90.9µs time.idle=9.10µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0
2023-05-18T14:08:25.388762Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:combine: rslex::dataset_crossbeam: close time.busy=1.22ms time.idle=9.50µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4
无论选择装载还是下载模式,rslex.log 文件都会详细记录所有文件复制。 它还介绍了使用的设置(环境变量)。 若要开始调试,请检查你是否已完成常见方案的最佳装载设置。
监视 Azure 存储
在 Azure 门户,可选择你的存储帐户,然后选择“指标”来查看存储指标:

然后,使用 SuccessServerLatency 绘制 SuccessE2ELatency。 如果指标显示 SuccessE2ELatency 较高且 SuccessServerLatency 较低,你的可用线程有限,或者 CPU、内存或网络带宽等资源不足,你应该执行以下操作:
- 使用 Azure 机器学习工作室中的监视视图检查作业的 CPU 和内存利用率。 如果 CPU 和内存不足,请考虑增加计算目标 VM 大小。
- 如果你正在下载并且未使用 CPU 和内存,请考虑增加
RSLEX_DOWNLOADER_THREADS。 如果使用装载,则应增加DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT以执行更多预提取,并增加DATASET_MOUNT_READ_THREADS以执行更多读取线程。
如果指标显示 SuccessE2ELatency 较低且 SuccessServerLatency 较低,但客户端遇到高延迟,则表示到达服务的存储请求存在延迟。 应检查:
- 相对于计算目标上可用的内核数,用于装载/下载 (
DATASET_MOUNT_READ_THREADS/RSLEX_DOWNLOADER_THREADS) 的线程数是否设置得太低。 如果设置得太低,请增加线程数。 - 下载的重试次数 (
AZUREML_DATASET_HTTP_RETRY_COUNT) 是否设置得太高。 如果是这样,请减少重试次数。
在作业期间监视磁盘使用情况
在 Azure 机器学习工作室中,你还可以在作业执行期间监视计算目标磁盘 IO 和使用情况。 导航到你的作业,然后选择“监视”选项卡。此选项卡以 30 天滚动方式提供有关作业资源的见解。 例如:

注意
作业监视仅支持 Azure 机器学习管理的计算资源。 运行时间少于 5 分钟的作业将没有足够的数据来填充此视图。
为了保持计算正常运行,Azure 机器学习数据运行时不使用磁盘空间的最后 RESERVED_FREE_DISK_SPACE 个字节(默认值为 150MB)。 如果磁盘已满,则代码会将文件写入磁盘,而不将文件声明为输出。 因此,请检查你的代码以确保数据不会错误地写入临时磁盘。 如果必须将文件写入临时磁盘,并且该资源已快满,请考虑:
- 将 VM 大小增加到具有较大临时磁盘的大小
- 在缓存数据上设置 TTL (
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL),以从磁盘中清除数据
将数据与计算共置
注意
如果存储和计算位于不同的区域,则性能会降低,因为数据必须跨区域传输。 这会增加成本。 确保存储帐户和计算资源位于同一区域中。
如果数据和 Azure 机器学习工作区存储在不同的区域中,建议使用 azcopy 实用工具将数据复制到同一区域中的存储帐户。 AzCopy 使用服务器到服务器 API,因此,数据可以直接在存储服务器之间复制。 这些复制操作不会占用计算机的网络带宽。 可以通过 AZCOPY_CONCURRENCY_VALUE 环境变量来提高这些操作的吞吐量。 若要了解详细信息,请参阅提高并发性。
存储负载
单个存储帐户在负载过高时可能会受到限制,包括以下情况:
- 作业使用了很多 GPU 节点
- 存储帐户有许多并发用户/应用在你运行作业时访问数据
本部分显示计算结果,以确定限制是否可能成为工作负荷的问题,以及如何减少限制。
计算带宽限制
Azure 存储帐户的默认出口限制为 120 Gbit/s。 Azure VM 具有不同的网络带宽,这会影响达到存储的最大默认出口容量所需的理论计算节点数:
| 大小 | GPU 卡 | vCPU | 内存:GiB | 临时存储 (SSD) GiB | GPU 卡的数量 | GPU 内存:GiB | 预期网络带宽 (Gbit/s) | 存储帐户出口默认最大值 (Gbit/s)* | 达到默认出口容量的节点数 |
|---|---|---|---|---|---|---|---|---|---|
| Standard_ND96asr_v4 | A100 | 96 | 900 | 6000 | 8 | 40 | 24 | 120 | 5 |
| Standard_ND96amsr_A100_v4 | A100 | 96 | 1900 | 6400 | 8 | 80 | 24 | 120 | 5 |
| Standard_NC6s_v3 | V100 | 6 | 112 | 736 | 1 | 16 | 24 | 120 | 5 |
| Standard_NC12s_v3 | V100 | 12 | 224 | 1474 | 2 | 32 | 24 | 120 | 5 |
| Standard_NC24s_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC24rs_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC4as_T4_v3 | T4 | 4 | 28 | 180 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC8as_T4_v3 | T4 | 8 | 56 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC16as_T4_v3 | T4 | 16 | 110 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC64as_T4_v3 | T4 | 64 | 440 | 2880 | 4 | 64 | 32 | 120 | 3 |
A100/V100 SKU 的每个节点的最大网络带宽为 24 Gbit/s。 如果每个从单个帐户读取数据的节点可以读取接近 24 Gbit/s 的理论最大值,则 5 个节点可能会达到出口容量。 使用 6 个或更多计算节点时,所有节点的数据吞吐量会开始下降。
重要
如果你的工作负荷需要超过 6 个 A100/V100 节点,或者你认为你会超出存储的默认出口容量 (120Gbit/s),请联系支持人员(通过 Azure 门户),并请求提高存储出口限制。
跨多个存储帐户进行缩放
你可能会超出存储的最大出口容量并/或可能达到请求速率限制。 如果出现这些问题,建议首先联系支持人员,以增加存储帐户的这些限制。
如果无法增加最大出口容量或请求速率限制,应考虑跨多个存储帐户复制数据。 将数据复制到具有 Azure 数据工厂、Azure 存储资源管理器 或 azcopy 的多个帐户,并在训练作业中装载所有帐户。 仅会下载在装载上访问的数据。 因此,训练代码可以从环境变量中读取 RANK,以选择要读取多个输入装载中的哪个。 你的作业定义传入存储帐户的列表:
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
code: src
command: >-
python train.py
--epochs ${{inputs.epochs}}
--learning-rate ${{inputs.learning_rate}}
--data ${{inputs.cifar_storage1}}, ${{inputs.cifar_storage2}}
inputs:
epochs: 1
learning_rate: 0.2
cifar_storage1:
type: uri_folder
path: azureml://datastores/storage1/paths/cifar
cifar_storage2:
type: uri_folder
path: azureml://datastores/storage2/paths/cifar
environment: azureml:AzureML-pytorch-1.9-ubuntu18.04-py37-cuda11-gpu@latest
compute: azureml:gpu-cluster
distribution:
type: pytorch
process_count_per_instance: 1
resources:
instance_count: 2
display_name: pytorch-cifar-distributed-example
experiment_name: pytorch-cifar-distributed-example
description: Train a basic convolutional neural network (CNN) with PyTorch on the CIFAR-10 dataset, distributed via PyTorch.
然后,你的训练 Python 代码可以使用 RANK 来获取特定于该节点的存储帐户:
import argparse
import os
parser = argparse.ArgumentParser()
parser.add_argument('--data', nargs='+')
args = parser.parse_args()
world_size = int(os.environ["WORLD_SIZE"])
rank = int(os.environ["RANK"])
local_rank = int(os.environ["LOCAL_RANK"])
data_path_for_this_rank = args.data[rank]
许多小文件问题
从存储读取文件涉及对每个文件发出请求的过程。 每个文件的请求计数因文件大小和处理文件读取的软件的设置而异。
通常以 1-4 MB 大小的块读取文件。 对于小于单个块的文件,使用单个请求进行读取 (GET file.jpg 0-4MB);对于大于单个块的文件,每个块发出一个请求 (GET file.jpg 0-4MB、GET file.jpg 4-8 MB)。 下表显示,与较大的文件相比,小于 4 MB 块的文件会导致更多的存储请求:
| # 文件 | 文件大小 | 总数据大小 | 块大小 | # 存储请求 |
|---|---|---|---|---|
| 2,000,000 | 500KB | 1 TB | 4 MB | 2,000,000 |
| 1,000 | 1GB | 1 TB | 4 MB | 256,000 |
对于小文件,延迟间隔主要涉及处理对存储而不是数据传输的请求。 因此,我们提供以下建议来增加文件大小:
- 对于非结构化数据(图像、文本、视频等),将小文件一起存档 (zip/tar),使它们存储为可以在多个区块中被读取的较大文件。 可以在计算资源中打开这些较大的存档文件,然后 PyTorch Archive DataPipes 就可以提取较小的文件。
- 对于结构化数据(CSV、parquet 等),请检查 ETL 过程,以确保它会联合文件以增加大小。 Spark 具有
repartition()和coalesce()方法来帮助增加文件大小。
如果无法增加文件大小,请浏览 Azure 存储选项。
Azure 存储选项
Azure 存储提供两个层 - 标准和高级层:
| 存储 | 方案 |
|---|---|
| Azure Blob - 标准 (HDD) | 数据以较大的 blob 构成–图像、视频等。 |
| Azure Blob - 高级 (SSD) | 事务速率高、对象较小或具有持续的低存储延迟要求 |
提示
对于“众多的”小文件(KB 数量级),我们建议使用“高级(SSD)”,因为存储成本低于运行 GPU 计算的成本。
读取 V1 数据资产
本部分介绍了如何在 V2 作业中读取 V1 FileDataset 和 TabularDataset 数据实体。
读取 FileDataset
在 Input 对象中,将 type 指定为 AssetTypes.MLTABLE,将 mode 指定为 InputOutputModes.EVAL_MOUNT:
注意
若要使用无服务器计算,请删除此代码中的 compute="cpu-cluster",。
若要详细了解 MLClient 对象、MLClient 对象初始化选项以及连接到工作区的方式,请访问连接到工作区。
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<filedataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
job = command(
code="./src", # Local path where the code is stored
command="ls ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the job status
returned_job.services["Studio"].endpoint
读取 TabularDataset
在 Input 对象中,将 type 指定为 AssetTypes.MLTABLE,将 mode 指定为 InputOutputModes.DIRECT:
注意
若要使用无服务器计算,请删除此代码中的 compute="cpu-cluster",。
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<tabulardataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.DIRECT
)
}
job = command(
code="./src", # Local path where the code is stored
command="python train.py --inputs ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the status of the job
returned_job.services["Studio"].endpoint