管理标记项目
了解如何在 Azure 机器学习中管理标记项目。 本文的目标读者是负责管理文本或图像标记项目的项目经理。 有关如何创建项目的信息,请参阅设置文本标记项目或设置图像标记项目。
重要
本文中标记了“(预览版)”的项目目前为公共预览版。 该预览版在提供时没有附带服务级别协议,建议不要将其用于生产工作负载。 某些功能可能不受支持或者受限。 有关详细信息,请参阅适用于 Azure 预览版的补充使用条款。
运行和监视项目
初始化项目后,Azure 将开始运行它。 若要管理项目,请选择“数据标记”主页上的项目。
若要暂停或重新启动该项目,请在项目命令栏上切换“正在运行”状态。 只能在项目运行时标记数据。
监视进度
“仪表板”选项卡将显示标记任务的进度。

进度图显示已标记、已跳过、需要审查或尚未完成的项数。 将鼠标悬停在该图表上可以查看每个部分中的项数。
图表下方显示了已完成任务的标签分布。 在某些项目类型中,一个项可以有多个标签。 标签总数可能会超过总项数。
它还显示了标记人员的分布及其标记的项数。
中间部分显示包含未分配任务队列的表。 当 ML 辅助标记处于关闭状态时,此部分显示等待分配的手动任务数。
当 ML 辅助标记处于开启状态时,此部分还会显示:
- 队列中包含聚类项的任务。
- 队列中包含预标记项的任务。
此外,启用 ML 辅助标记后,可以向下滚动以查看 ML 辅助标记状态。 “作业”部分提供每个机器学习运行的链接。
- 训练 - 训练模型以预测标签。
- 验证 - 确定项预先标记是否使用此模型的预测。
- 推理 - 新项的预测运行。
- 特征化 - 聚类项(仅适用于图像分类项目)。

查看数据和标签
在“数据”选项卡上,预览数据集并查看已标记的数据。
提示
在审阅之前,请与任何其他可能的审阅者进行协调。 否则,可能会同时尝试批准同一个标签,这会阻止其中一个用户对其进行更新。
滚动已标记的数据以查看标签。 如果发现数据标记不正确,可以选择该数据,然后选择“拒绝”以删除标签,并将数据返回到未标记队列中。
已跳过项
一组适用于正在查看的项的筛选器。 默认情况下,可以查看已标记的数据。 选择“资产类型”筛选器,将类型切换到*“已跳过”查看已跳过的项。

如果认为应标记已跳过的数据,请选择“拒绝”以放回到未标记的队列中。 如果认为已跳过的数据与项目无关,请选择“接受”将其从项目中删除。
共识标记
如果项目使用共识标签,请审查那些没有达成共识的图像:
选择“数据”选项卡。
在左侧菜单上,选择“审查标签”。
在“审查标签”上方的命令栏上,选择“所有筛选器”。

在“标记的数据点”下,选择“需要审查的共识标签”,以仅显示标记人员未达成共识的图像。
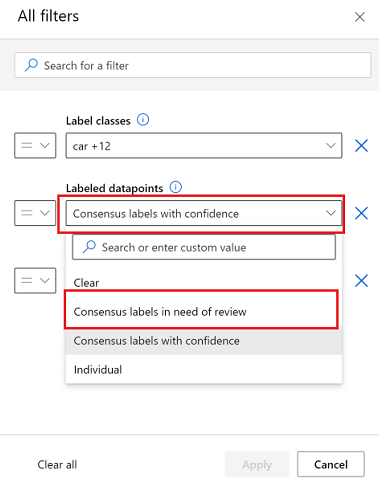
对于需要审查的每个图像,请选择“共识标签”下拉菜单以查看有冲突的标签。
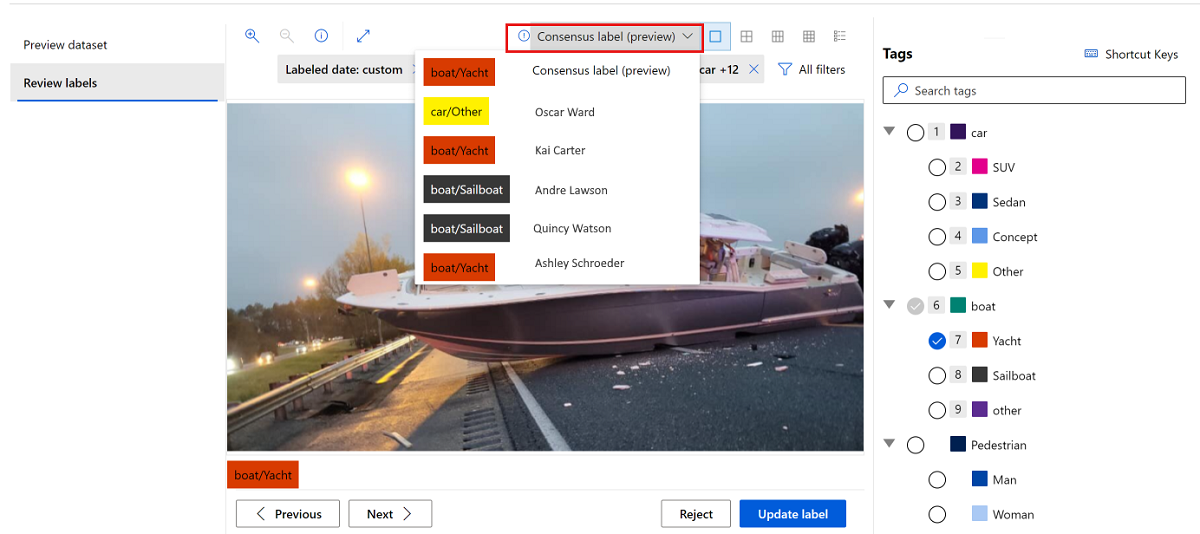
虽然可以选择单个标记人员以查看其标签,但若要更新或拒绝标签,必须使用顶部的选项“共识标签(预览版)”。




更改项目详细信息
在“详细信息”选项卡上查看和更改项目的详细信息。在此选项卡上,可以:
- 查看项目详细信息和输入数据集。
- 设置或清除“启用定期增量刷新”选项,或请求立即刷新。
- 查看用于在项目中存储已标记的输出的存储容器详细信息。
- 将标签添加到项目。
- 编辑为标签提供的说明。
- 更改 ML 辅助标记的设置,并启动标记任务。
向项目添加标签
在数据标签过程中,你可能想要添加更多标签以便对项目进行分类。 例如,你可能想要添加“未知”或“其他”标签来表明混淆的项目。
若要将一个或多个标签添加到项目,请执行以下操作:
在“数据标记”主页上,选择该项目。
在项目命令栏上,将状态从“正在运行”切换到“已暂停”以停止标记活动。
选择“详细信息”选项卡。
在左侧的列表中,选择“标签类别”。
修改标签。
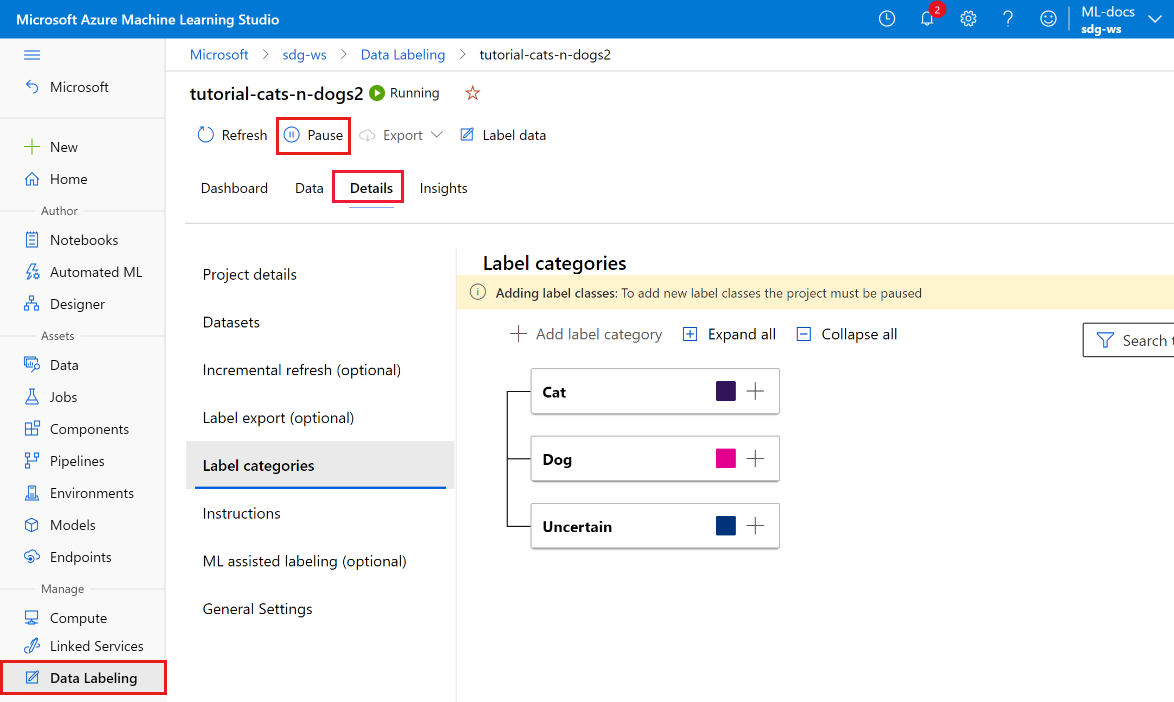
在窗体中,添加新标签。 然后选择如何继续该项目。 由于已更改可用标签,请选择如何处理已标记的数据:
- 重新开始,并删除所有现有标签。 如果要使用新的完整标签集开始标记,请选择此选项。
- 重新开始,并保留所有现有标签。 选择此选项可将所有数据标记为“未标记”,但保留现有标签作为先前标记的图像的默认标记。
- 继续,并保留所有现有标签。 选择此选项可以保留所有按原样标记的数据,并开始对尚未标记的数据使用新标签。
根据需要修改新标签的说明页。
添加所有新标签后,请将“已暂停”切换为“正在运行”以重启项目。
启动 ML 辅助标记任务
标记某些项后,ML 辅助标记会自动启动。 此自动阈值因项目而异。 如果你的项目至少包含一些标记的数据,则可以手动启动 ML 辅助训练运行。
注意
按需训练不适用于 2022 年 12 月之前创建的项目。 若要使用此功能,请创建一个新项目。
若要启动新的 ML 辅助训练运行,请执行以下操作:
- 在项目顶部,选择“详细信息”。
- 在左侧菜单中,选择“ML 辅助标记”。
- 在页面底部附近,对于“按需训练”,选择“启动”。
导出标签
若要导出标签,请在项目命令栏上选择“导出”按钮。 随时可以导出标签数据以进行机器学习试验。
如果项目类型为“语义分段(预览版)”,则会创建 Azure MLTable 数据资产。
对于所有其他项目类型,可以将图像标签导出为:
- CSV 文件。 Azure 机器学习将在位于 Labeling/export/csv 内的某个文件夹中创建 CSV 文件。
- COCO 格式文件。 Azure 机器学习将在位于 Labeling/export/coco 内的某个文件夹中创建 COCO 文件。
- 具有标记的 Azure 机器学习数据集。
- CSV 文件。 Azure 机器学习将在位于 Labeling/export/csv 内的某个文件夹中创建 CSV 文件。
- COCO 格式文件。 Azure 机器学习将在位于 Labeling/export/coco 内的某个文件夹中创建 COCO 文件。
- Azure MLTable 数据资产。
导出 CSV 或 COCO 文件时,当文件准备好下载时,会短暂出现一条通知。 选择“下载文件”链接以下载结果。 还可以在顶部栏的“通知”部分找到通知:
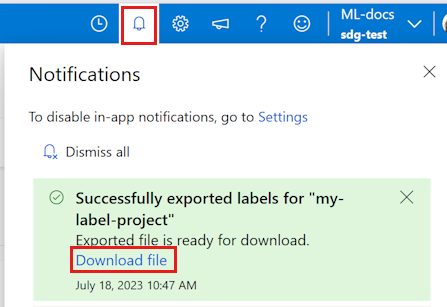
在机器学习的“数据”部分访问导出的 Azure 机器学习数据集和数据资产。 数据详细信息页还提供了可用于使用 Python 访问标签的示例代码。
将标记数据导出到 Azure 机器学习数据集后,可以使用 AutoML 构建基于标记数据训练的计算机视觉模型。 有关详细信息,请参阅设置 AutoML 以使用 Python 训练计算机视觉模型。
导入标签(预览)
如果 Azure MLTable 数据资产或 COCO 文件包含当前数据的标签,则可以将这些标签导入项目。 例如,你可能拥有从之前的标记项目中使用相同数据导出的标签。 导入标签功能仅适用于图像项目。
若要导入标签,请在项目命令栏上选择“导入”按钮。 随时可以导入已标记的数据以进行机器学习试验。
从 COCO 文件或 Azure MLTable 数据资产导入。
数据映射
必须指定映射到“图像”字段的列。 还可以选择映射数据中存在的其他列。 例如,如果数据包含“标签”列,则可以将其映射到“类别”字段。 如果数据包含“置信度”列,则可以将其映射到“置信度”字段。
如果要导入之前项目的标签,则这些标签的格式必须与要创建的标签的格式相同。 例如,如果要创建边界框标签,导入的标签也必须是边界框标签。
导入选项
选择如何处理导入的标签:
- 作为预标记数据 - 选择此选项可将导入的标签用作预标记数据。 然后,标记员可以查看预标记数据,并在提交标签之前更正任何错误。
- 作为最终标签 - 选择此选项可将标签导入为最终标签。 只有尚未包含标签的数据才会作为任务呈现给标记员。
标记人员的访问权限
可以通过“参与者”或“所有者”角色访问工作区的任何人都可以在项目中标记数据。
你还可添加用户并自定义权限,使它们能够访问标记,但是无法访问工作区的其他部分或者你的标记项目。 有关详细信息,请参阅将用户添加到数据标记项目。
排查问题
如果你在管理项目时发现任何以下问题,请使用这些提示:
| 问题 | 解决方法 |
|---|---|
| 只能使用在 Blob 数据存储中创建的数据集。 | 此问题是当前版本的已知限制。 |
| 从项目使用的数据集中移除数据会导致项目中出现错误。 | 不要从标记项目中使用的数据集版本中移除数据。 创建用于删除数据的数据集的新版本。 |
| 创建项目后,项目将在较长时间内处于“正在初始化”状态。 | 手动刷新页面。 初始化应该按每秒大约 20 个数据点的速率完成。 没有自动刷新是一个已知问题。 |
| 新标记的项在数据评审中不可见。 | 若要加载所有标记的项,请选择“第一个”按钮。 按下“第一个”按钮会返回到列表的最前面,并加载所有标记的数据。 |
| 无法将任务集分配给特定的标记人员。 | 此问题是当前版本的已知限制。 |
对象检测疑难解答
| 问题 | 解决方法 |
|---|---|
| 如果在标记对象检测时选择 Esc 键,则会创建大小为零的标签,并且标签提交将失败。 | 若要删除标签,请选择标签旁边的 X 删除图标。 |
如果在创建项目时遇到问题,请参阅排查创建数据标记项目时出现的问题