Azure 机器学习推理路由器和连接要求
Azure 机器学习推理路由器是使用 Kubernetes 群集进行实时推理的关键组件。 本文介绍以下内容:
- 什么是 Azure 机器学习推理路由器
- 自动缩放的工作原理
- 如何配置和满足推理请求性能(每秒请求数和延迟)
- AKS 推理群集的连接要求
什么是 Azure 机器学习推理路由器
Azure 机器学习推理路由器是在 Azure 机器学习扩展部署时部署在 AKS 或 Arc Kubernetes 群集上的前端组件 (azureml-fe)。 它具有以下功能:
- 将来自群集负载均衡器或入口控制器的传入推理请求路由到相应的模型 Pod。
- 通过智能协调路由对所有传入推理请求进行负载均衡。
- 管理模型 Pod 自动缩放。
- 容错和故障转移功能,确保推理请求始终为关键商业应用程序提供服务。
以下步骤演示前端处理请求的方式:
- 客户端将请求发送到负载均衡器。
- 负载均衡器发送到其中一个前端。
- 前端为服务找到服务路由器(前端实例充当协调器)。
- 服务路由器选择后端,并将其返回到前端。
- 前端将请求转发到后端。
- 处理请求后,后端会向前端组件发送响应。
- 前端将响应传播回客户端。
- 前端通知服务路由器后端已完成处理,并可用于其他请求。
下图演示了此流:
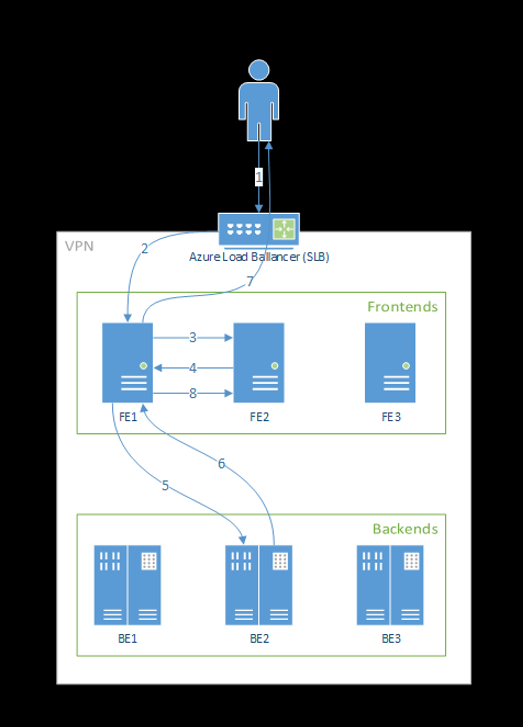
从上图中可以看出,Azure 机器学习扩展部署期间默认创建了 3 个 azureml-fe 实例,一个实例充当协调角色,其他实例则为传入的推理请求提供服务。 协调实例拥有关于模型 Pod 的所有信息,并决定哪个模型 Pod 为传入请求提供服务,而服务 azureml-fe 实例负责将请求路由到选定模型 Pod 并将响应传播回原始用户。
自动缩放
Azure 机器学习推理路由器可处理 Kubernetes 群集上所有模型部署的自动缩放。 由于所有推理请求都通过它进行,因此它具有自动缩放已部署模型所需的数据。
重要
不要为模型部署启用 Kubernetes 水平 Pod 自动缩放程序 (HPA) 。 这样做会导致两个自动缩放组件相互竞争。 Azureml-fe 设计用于自动缩放由 Azure 机器学习部署的模型,其中,HPA 必须根据 CPU 使用率或自定义指标配置等一般指标推测或估算模型利用率。
Azureml-fe 不会缩放 AKS 群集中的节点数,因为这可能会导致成本意外增加。 相反,它会在物理群集边界内缩放模型的副本数。 如果你需要缩放群集中的节点数,则可以手动缩放群集,或配置 AKS 群集自动缩放程序。
可以通过部署 YAML 中的 scale_settings 属性控制自动缩放。 以下示例演示了如何启用自动缩放:
# deployment yaml
# other properties skipped
scale_setting:
type: target_utilization
min_instances: 3
max_instances: 15
target_utilization_percentage: 70
polling_interval: 10
# other deployment properties continue
基于 utilization of the current container replicas 做出纵向扩展或缩减的决定。
utilization_percentage = (The number of replicas that are busy processing a request + The number of requests queued in azureml-fe) / The total number of current replicas
如果此数字超出 target_utilization_percentage,则会创建更多的副本。 如果它较低,则会减少副本。 默认情况下,目标利用率为 70%。
添加副本的决策是迫切而迅速的(大约 1 秒)。 删除副本的决策是保守的(大约 1 分钟)。
例如,如果想部署模型服务并想知道应该为每秒目标请求数 (RPS) 和目标响应时间配置多少实例(Pod/副本)。 可以使用以下代码计算所需的副本:
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
azureml-fe 的性能
azureml-fe 能以良好的延迟达到 5000 的每秒请求数 (QPS),平均开销不超过 3 毫秒,在 99% 的情况下不超过 15 毫秒。
注意
如果 RPS 要求高于 10K,请考虑以下选项:
- 增加
azureml-fePod 的资源请求/限制,默认情况下,它的限制为 2 个 vCPU 和 1.2G 内存资源。 - 增加
azureml-fe的实例数。 默认情况下,Azure 机器学习为每个群集创建 3 个或 1 个azureml-fe实例。- 此实例计数取决于 Azure 机器学习扩展的
inferenceRouterHA配置。 - 增大的实例计数无法保留,因为在扩展升级后,它将被你配置的值覆盖。
- 此实例计数取决于 Azure 机器学习扩展的
- 请联系 Azure 专家寻求帮助。
了解 AKS 推理集群的连接要求
AKS 群集使用以下两种网络模型之一进行部署:
- Kubenet 网络 - 通常在部署 AKS 群集时创建和配置网络资源。
- Azure 容器网络接口 (CNI) 网络 - AKS 群集连接到现有的虚拟网络资源和配置。
对于 Kubenet 网络,已为 Azure 机器学习服务适当创建和配置了网络。 对于 CNI 网络,需要了解连接要求,并确保用于 AKS 推理的 DNS 解析和出站连接。 例如,如果使用防火墙阻止网络流量,可能需要执行其他步骤。
下图显示了 AKS 推理的连接要求。 黑色箭头代表实际的通信,蓝色箭头代表域名。 可能需要将这些主机的条目添加到防火墙或自定义 DNS 服务器。
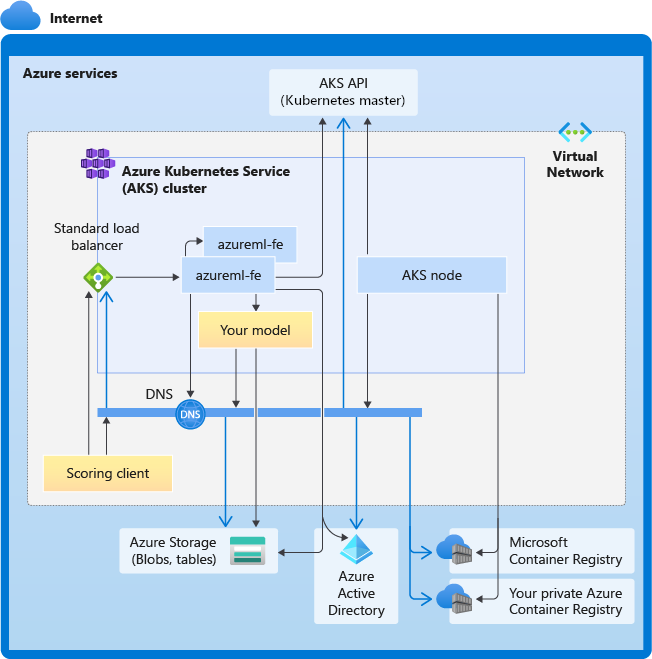
要查看常规的 AKS 连接要求,请参阅控制 Azure Kubernetes 服务中群集节点的出口流量。
若要访问防火墙后的 Azure 机器学习服务,请参阅配置入站和出站网络流量。
总体 DNS 解析要求
现有 VNet 中的 DNS 解析由用户控制。 例如,防火墙或自定义 DNS 服务器。 以下主机必须是可访问的:
| 主机名 | 使用者 |
|---|---|
<cluster>.hcp.<region>.azmk8s.io |
AKS API 服务器 |
mcr.microsoft.com |
Microsoft Container Registry (MCR) |
<ACR name>.azurecr.io |
Azure 容器注册表 (ACR) |
<account>.blob.core.chinacloudapi.cn |
Azure 存储帐户(Blob 存储) |
api.azureml.ms |
Microsoft Entra 身份验证 |
ingest-vienna<region>.kusto.chinacloudapi.cn |
Kusto 终结点用于上传遥测数据 |
按时间顺序排列的连接性要求:从群集创建到模型部署
在部署 azureml-fe 之后,它将立即尝试启动,这需要:
- 解析 AKS API 服务器的 DNS
- 查询 AKS API 服务器以发现自身的其他实例(这是一个多 Pod 服务)
- 连接到其自身的其他实例
启动 azureml-fe 后,需要使用以下连接才能正常工作:
- 连接到 Azure 存储以下载动态配置
- 为 Microsoft Entra 身份验证服务器 api.azureml.ms 解析 DNS,并在部署的服务使用 Microsoft Entra 身份验证时与其通信。
- 查询 AKS API 服务器以发现已部署的模型
- 与已部署的模型 Pod 进行通信
在模型部署时,要成功进行模型部署,AKS 节点应能够:
- 为客户的 ACR 解析 DNS
- 从客户的 ACR 下载映像
- 为存储模型的 Azure BLOB 解析 DNS
- 从 Azure Blob 下载模型
部署模型并启动服务后,azureml-fe 将使用 AKS API 自动发现它,并准备将请求路由到该模型。 它必须能够与模型 Pod 通信。
注意
如果部署的模型需要任何连接(例如查询外部数据库或其他 REST 服务,下载 BLOB 等),则应启用这些服务的 DNS 解析和出站通信。