数据引入管道的 DevOps
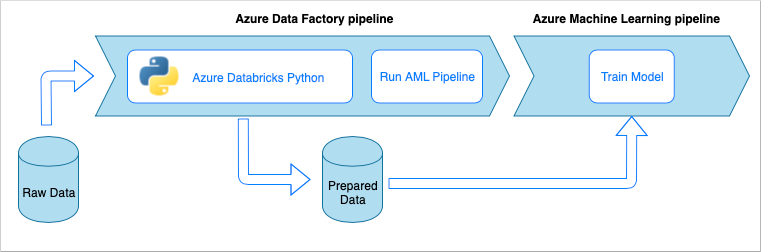
在大多数方案中,数据引入解决方案是脚本、服务调用以及协调所有活动的管道的复合体。 本文介绍如何将 DevOps 做法应用到常用数据引入管道的开发生命周期,以便准备数据来进行机器学习模型训练。 管道是使用以下 Azure 服务构建的:
- Azure 数据工厂:读取原始数据并协调数据准备。
- Azure Databricks:运行转换数据的 Python 笔记本。
- Azure Pipelines:实现持续集成和开发过程的自动化。
数据引入管道工作流
数据引入管道实现以下工作流:
- 原始数据将读取到 Azure 数据工厂 (ADF) 管道中。
- ADF 管道将数据发送到 Azure Databricks 群集,该群集运行 Python 笔记本以转换数据。
- 数据会存储到 Blob 容器中,Azure 机器学习可以在该容器中使用这些数据训练模型。
持续集成和交付概述
与许多软件解决方案一样,会有某个团队(例如“数据工程师”)在致力于它。 他们相互协作并共享相同的 Azure 资源,例如 Azure 数据工厂、Azure Databricks 和 Azure 存储帐户。 这些资源的集合构成了开发环境。 数据工程师为同一源代码库贡献代码。
持续集成和交付系统会自动执行生成、测试和交付(部署)解决方案的过程。 持续集成 (CI) 过程执行以下任务:
- 汇编代码
- 执行代码质量测试来检查代码
- 运行单元测试
- 生成经过测试的代码和 Azure 资源管理器模板等项目
持续交付 (CD) 过程将项目部署到下游环境。
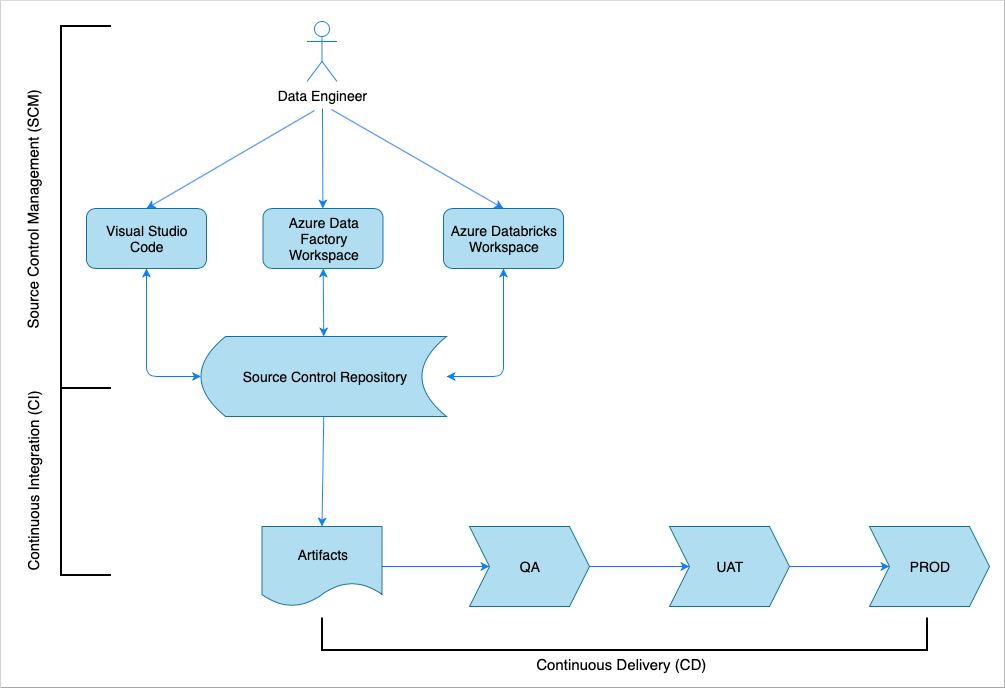
本文演示如何使用 Azure Pipelines 将 CI 和 CD 过程自动化。
源代码管理
若要跟踪更改并使得团队成员之间可以进行协作,需要进行源代码管理。 例如,将代码存储在 Azure DevOps、GitHub 或 GitLab 存储库中。 协作工作流基于分支模型。 例如,GitFlow。
Python 笔记本源代码
数据工程师可以在 IDE(例如 Visual Studio Code)本地或者直接在 Databricks 工作区中处理 Python 笔记本源代码。 代码更改完成后,代码更改会根据分支策略合并到存储库中。
提示
建议将代码存储在 .py 文件中,而不要以 .ipynb Jupyter Notebook 格式存储。 这样可以改善代码的可读性,并在 CI 过程中实现自动代码质量检查。
Azure 数据工厂源代码
Azure 数据工厂管道的源代码是 Azure 数据工厂工作区生成的 JSON 文件的集合。 通常,数据工程师会在 Azure 数据工厂工作区中使用可视化设计器,而不是直接处理源代码文件。
持续集成 (CI)
持续集成过程的最终目标是从源代码收集联合团队的工作,并为部署到下游环境做好准备。 与源代码管理一样,此过程对于 Python 笔记本和 Azure 数据工厂管道是不同的。
Python 笔记本 CI
Python 笔记本的 CI 过程从协作分支(例如 master 或 develop)获取代码并执行以下活动:
- 代码检查
- 单元测试
- 将代码保存为项目
以下代码片段演示如何在 Azure DevOps“yaml”管道中实现这些步骤:
steps:
- script: |
flake8 --output-file=$(Build.BinariesDirectory)/lint-testresults.xml --format junit-xml
workingDirectory: '$(Build.SourcesDirectory)'
displayName: 'Run flake8 (code style analysis)'
- script: |
python -m pytest --junitxml=$(Build.BinariesDirectory)/unit-testresults.xml $(Build.SourcesDirectory)
displayName: 'Run unit tests'
- task: PublishTestResults@2
condition: succeededOrFailed()
inputs:
testResultsFiles: '$(Build.BinariesDirectory)/*-testresults.xml'
testRunTitle: 'Linting & Unit tests'
failTaskOnFailedTests: true
displayName: 'Publish linting and unit test results'
- publish: $(Build.SourcesDirectory)
artifact: di-notebooks
该管道使用 flake8 执行 Python 代码检查。 它运行源代码中定义的单元测试,并发布检查和测试结果以便在 Azure 管道执行屏幕中显示。
如果Lint 分析和单元测试成功,管道会将源代码复制到项目存储库,供后续的部署步骤使用。
Azure 数据工厂 CI
Azure 数据工厂管道的 CI 过程是数据引入管道的瓶颈。 不会执行持续集成。 Azure 数据工厂的可部署项目是 Azure 资源管理器模板的集合。 生成这些模板的唯一方式是单击 Azure 数据工厂工作区中的“发布”按钮。
- 数据工程师将源代码从其功能分支合并到协作分支(例如 master 或 develop)。
- 已被授予权限的人员单击“发布”按钮,从协作分支中的源代码生成 Azure 资源管理器模板。
- 工作区会验证管道(将其视为 Lint 分析和单元测试),生成 Azure 资源管理器模板(将其视为生成),并将生成的模板保存到同一代码存储库中的技术分支 adf_publish(将其视为发布项目)。 此分支由 Azure 数据工厂工作区自动创建。
必须确保生成的 Azure 资源管理器模板不区分环境。 这意味着,所有在不同环境中可能会有所不同的值均会参数化。 Azure 数据工厂足够智能,可将大多数此类值作为参数公开。 例如,在以下模板中,Azure 机器学习工作区的连接属性将作为参数公开:
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"factoryName": {
"value": "devops-ds-adf"
},
"AzureMLService_servicePrincipalKey": {
"value": ""
},
"AzureMLService_properties_typeProperties_subscriptionId": {
"value": "0fe1c235-5cfa-4152-17d7-5dff45a8d4ba"
},
"AzureMLService_properties_typeProperties_resourceGroupName": {
"value": "devops-ds-rg"
},
"AzureMLService_properties_typeProperties_servicePrincipalId": {
"value": "6e35e589-3b22-4edb-89d0-2ab7fc08d488"
},
"AzureMLService_properties_typeProperties_tenant": {
"value": "72f988bf-86f1-41af-912b-2d7cd611db47"
}
}
}
但是,你可能想要公开 Azure 数据工厂工作区默认不会处理的自定义属性。 在本文所述的方案中,Azure 数据工厂管道将调用一个处理数据的 Python 笔记本。 该笔记本接受包含输入数据文件名的参数。
import pandas as pd
import numpy as np
data_file_name = getArgument("data_file_name")
data = pd.read_csv(data_file_name)
labels = np.array(data['target'])
...
此名称对于 Dev、QA、UAT 和 PROD 环境是不同的。 在包含多个活动的复杂管道中,可能存在多个自定义属性。 最好是将所有这些值收集到一个位置,并将其定义为管道变量:
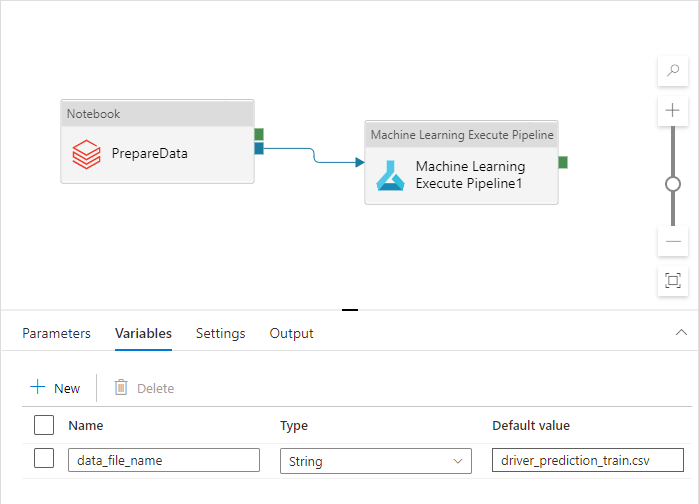
管道活动在实际使用管道变量时可以引用它们:
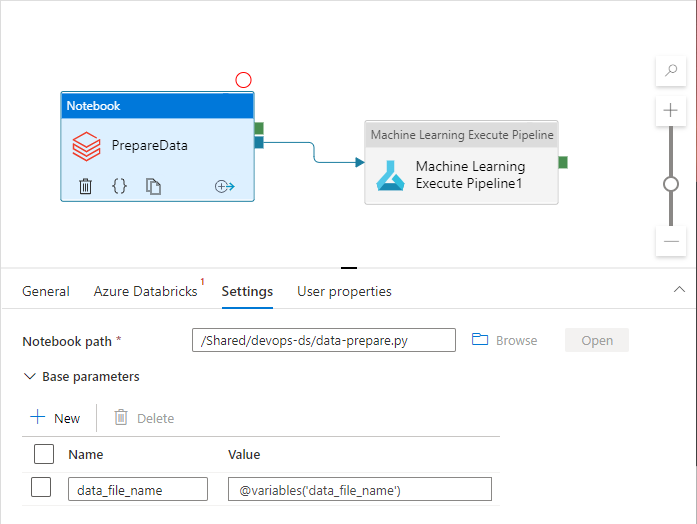
"Microsoft.DataFactory/factories/pipelines": {
"properties": {
"variables": {
"*": {
"defaultValue": "="
}
}
}
}
这样,在单击“发布”按钮时,会强制 Azure 数据工厂工作区将变量添加到参数列表中:
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"factoryName": {
"value": "devops-ds-adf"
},
...
"data-ingestion-pipeline_properties_variables_data_file_name_defaultValue": {
"value": "driver_prediction_train.csv"
}
}
}
JSON 文件中的值是在管道定义中配置的默认值。 部署 Azure 资源管理器模板时,这些值预期会由目标环境值重写。
持续交付 (CD)
持续交付过程提取项目并将其部署到第一个目标环境。 它通过运行测试来确保解决方案可正常运行。 如果测试成功,则继续部署到下一个环境。
CD Azure 管道由多个表示环境的阶段组成。 每个阶段包含部署,以及执行以下步骤的作业:
- 将 Python 笔记本部署到 Azure Databricks 工作区
- 部署 Azure 数据工厂管道
- 运行管道
- 检查数据引入结果
可以使用审批和门限(就部署过程如何在环境链中递进提供额外的控制)来配置管道阶段。
部署 Python 笔记本
以下代码片段定义一个将 Python 笔记本复制到 Databricks 群集的 Azure 管道部署:
- stage: 'Deploy_to_QA'
displayName: 'Deploy to QA'
variables:
- group: devops-ds-qa-vg
jobs:
- deployment: "Deploy_to_Databricks"
displayName: 'Deploy to Databricks'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: deploynotebooks@0
inputs:
notebooksFolderPath: '$(Pipeline.Workspace)/di-notebooks'
workspaceFolder: '/Shared/devops-ds'
displayName: 'Deploy (copy) data processing notebook to the Databricks cluster'
CI 生成的项目将自动复制到部署代理,并在 $(Pipeline.Workspace) 文件夹中提供。 在本例中,部署任务引用包含 Python 笔记本的 di-notebooks 项目。 此部署使用 Databricks Azure DevOps 扩展将笔记本文件复制到 Databricks 工作区。
Deploy_to_QA 阶段包含对 Azure DevOps 项目中定义的 devops-ds-qa-vg 变量组的引用。 此阶段中的步骤引用此变量组中的变量(例如 $(DATABRICKS_URL) 和 $(DATABRICKS_TOKEN))。 其思路是,下一阶段(例如 Deploy_to_UAT)将使用其自己的 UAT 范围内的变量组中定义的相同变量名称运行。
部署 Azure 数据工厂管道
Azure 数据工厂的可部署项目是一个 Azure 资源管理器模板。 它将通过“Azure 资源组部署”任务来部署,如以下代码片段所示:
- deployment: "Deploy_to_ADF"
displayName: 'Deploy to ADF'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: AzureResourceGroupDeployment@2
displayName: 'Deploy ADF resources'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
resourceGroupName: $(RESOURCE_GROUP)
location: $(LOCATION)
csmFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateForFactory.json'
csmParametersFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateParametersForFactory.json'
overrideParameters: -data-ingestion-pipeline_properties_variables_data_file_name_defaultValue "$(DATA_FILE_NAME)"
数据文件名参数的值取自 QA 阶段变量组中定义的 $(DATA_FILE_NAME) 变量。 类似地,可以重写 ARMTemplateForFactory.json 中定义的所有参数。 如果未重写,则使用默认值。
运行管道并检查数据引入结果
下一步是确保部署的解决方案可正常运行。 以下作业定义使用 PowerShell 脚本运行 Azure 数据工厂管道,并在 Azure Databricks 群集上执行一个 Python 笔记本。 该笔记本检查是否已正确引入数据,并验证名称为 $(bin_FILE_NAME) 的结果数据文件。
- job: "Integration_test_job"
displayName: "Integration test job"
dependsOn: [Deploy_to_Databricks, Deploy_to_ADF]
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: AzurePowerShell@4
displayName: 'Execute ADF Pipeline'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
ScriptPath: '$(Build.SourcesDirectory)/adf/utils/Invoke-ADFPipeline.ps1'
ScriptArguments: '-ResourceGroupName $(RESOURCE_GROUP) -DataFactoryName $(DATA_FACTORY_NAME) -PipelineName $(PIPELINE_NAME)'
azurePowerShellVersion: LatestVersion
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: executenotebook@0
inputs:
notebookPath: '/Shared/devops-ds/test-data-ingestion'
existingClusterId: '$(DATABRICKS_CLUSTER_ID)'
executionParams: '{"bin_file_name":"$(bin_FILE_NAME)"}'
displayName: 'Test data ingestion'
- task: waitexecution@0
displayName: 'Wait until the testing is done'
作业中的最后一个任务检查笔记本执行结果。 如果返回了错误,则将管道执行状态设置为 failed。
将各个部分组合到一起
完整的 CI/CD Azure 管道包括以下阶段:
- CI
- 部署到 QA
- 部署到 Databricks + 部署到 ADF
- 集成测试
此管道包含许多“部署”阶段,阶段数目与现有的目标环境数目相同。 每个“部署”阶段包含两个并行运行的部署,以及一个在部署后运行的用于在环境中测试解决方案的作业。
以下 yaml 代码片段中汇编了该管道的示例实现:
variables:
- group: devops-ds-vg
stages:
- stage: 'CI'
displayName: 'CI'
jobs:
- job: "CI_Job"
displayName: "CI Job"
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- script: pip install --upgrade flake8 flake8_formatter_junit_xml
displayName: 'Install flake8'
- checkout: self
- script: |
flake8 --output-file=$(Build.BinariesDirectory)/lint-testresults.xml --format junit-xml
workingDirectory: '$(Build.SourcesDirectory)'
displayName: 'Run flake8 (code style analysis)'
- script: |
python -m pytest --junitxml=$(Build.BinariesDirectory)/unit-testresults.xml $(Build.SourcesDirectory)
displayName: 'Run unit tests'
- task: PublishTestResults@2
condition: succeededOrFailed()
inputs:
testResultsFiles: '$(Build.BinariesDirectory)/*-testresults.xml'
testRunTitle: 'Linting & Unit tests'
failTaskOnFailedTests: true
displayName: 'Publish linting and unit test results'
# The CI stage produces two artifacts (notebooks and ADF pipelines).
# The pipelines Azure Resource Manager templates are stored in a technical branch "adf_publish"
- publish: $(Build.SourcesDirectory)/$(Build.Repository.Name)/code/dataingestion
artifact: di-notebooks
- checkout: git://${{variables['System.TeamProject']}}@adf_publish
- publish: $(Build.SourcesDirectory)/$(Build.Repository.Name)/devops-ds-adf
artifact: adf-pipelines
- stage: 'Deploy_to_QA'
displayName: 'Deploy to QA'
variables:
- group: devops-ds-qa-vg
jobs:
- deployment: "Deploy_to_Databricks"
displayName: 'Deploy to Databricks'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: deploynotebooks@0
inputs:
notebooksFolderPath: '$(Pipeline.Workspace)/di-notebooks'
workspaceFolder: '/Shared/devops-ds'
displayName: 'Deploy (copy) data processing notebook to the Databricks cluster'
- deployment: "Deploy_to_ADF"
displayName: 'Deploy to ADF'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: AzureResourceGroupDeployment@2
displayName: 'Deploy ADF resources'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
resourceGroupName: $(RESOURCE_GROUP)
location: $(LOCATION)
csmFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateForFactory.json'
csmParametersFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateParametersForFactory.json'
overrideParameters: -data-ingestion-pipeline_properties_variables_data_file_name_defaultValue "$(DATA_FILE_NAME)"
- job: "Integration_test_job"
displayName: "Integration test job"
dependsOn: [Deploy_to_Databricks, Deploy_to_ADF]
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: AzurePowerShell@4
displayName: 'Execute ADF Pipeline'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
ScriptPath: '$(Build.SourcesDirectory)/adf/utils/Invoke-ADFPipeline.ps1'
ScriptArguments: '-ResourceGroupName $(RESOURCE_GROUP) -DataFactoryName $(DATA_FACTORY_NAME) -PipelineName $(PIPELINE_NAME)'
azurePowerShellVersion: LatestVersion
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: executenotebook@0
inputs:
notebookPath: '/Shared/devops-ds/test-data-ingestion'
existingClusterId: '$(DATABRICKS_CLUSTER_ID)'
executionParams: '{"bin_file_name":"$(bin_FILE_NAME)"}'
displayName: 'Test data ingestion'
- task: waitexecution@0
displayName: 'Wait until the testing is done'