AutoML 中预测相关的常见问题
适用于: Python SDK azure-ai-ml v2(当前版本)
Python SDK azure-ai-ml v2(当前版本)
本文解答了自动化机器学习 (AutoML) 中预测相关的常见问题。 有关 AutoML 中预测方法的一般信息,请参阅 AutoML 中的预测方法概述一文。
如何开始在 AutoML 中生成预测模型?
首先,可以阅读设置 AutoML 以训练时序预测模型一文。 我们还提供了多个 Jupyter 笔记本动手示例:
为什么 AutoML 处理我的数据时速度缓慢?
我们一直在努力让 AutoML 更快、更可缩放。 作为常规预测平台,AutoML 在大型模型空间中执行广泛的数据验证、复杂特征工程和搜索。 这种复杂性意味着需要大量时间,具体取决于数据和配置。
运行时速度慢的一个常见原因是在包含大量时序的数据上使用默认设置训练 AutoML。 许多预测方法的成本随序列数缩放。 例如,指数平滑和 Prophet 等方法会为训练数据中的每个时序训练模型。
AutoML 的“多模型”功能可通过跨计算群集分布训练作业来扩展到这些方案, 并已成功应用于具有数百万个时序的数据。 有关详细信息,请参阅许多模型文章部分。 还可以了解一下在备受瞩目的竞赛数据集上多模型的成功。
如何让 AutoML 更快?
请参阅“为什么 AutoML 处理我的数据时速度缓慢”的解答,了解在你的情况中 AutoML 缓慢的原因。
请考虑以下配置更改,它们可能会加快作业速度:
- 阻止时序模型,如 ARIMA 和 Prophet。
- 关闭回溯功能,如延迟和滚动窗口。
- 减少:
- 试用/迭代次数。
- 试用/迭代超时。
- 试验超时。
- 交叉验证折叠数。
- 确保已启用提前终止。
应使用哪种建模配置?
AutoML 预测支持四种基本配置:
| 配置 | 场景 | 优点 | 缺点 |
|---|---|---|---|
| 默认 AutoML | 如果数据集具有少量历史行为大致相似的时序,则建议使用。 | - 易于从代码/SDK 或 Azure 机器学习工作室进行配置。 - AutoML 可以跨不同时序进行学习,因为回归模型会在训练中将所有序列汇集在一起。 有关详细信息,请参阅模型分组。 |
- 如果训练数据中的时序具有不同行为,则回归模型可能不太准确。 - 如果训练数据中存在大量序列,则时序模型的训练可能需要很长时间。 有关详细信息,请参阅“为什么 AutoML 处理我的数据时速度缓慢?”的解答。 |
| AutoML 与深度学习 | 对于具有超过 1000 个观察结果的数据集,以及可能具有大量表现出复杂模式的时序,建议使用。 启用后,AutoML 将在训练期间扫描时序卷积神经网络 (TCN) 模型。 有关详细信息,请参阅启用深度学习。 | - 易于从代码/SDK 或 Azure 机器学习工作室进行配置。 - 由于 TCN 会汇集所有系列的数据,所以会有交叉学习机会。 - 由于深度神经网络 (DNN) 模型容量较大,所以准确度可能更高。 有关详细信息,请参阅 AutoML 中的预测模型。 |
- 由于 DNN 模型的复杂性,训练可能需要更长的时间。 - 具有少量历史记录的系列不太可能受益于这些模型。 |
| 许多模型 | 如果需要以可缩放的方式训练和管理大量预测模型,建议使用。 有关详细信息,请参阅许多模型文章部分。 | - 可缩放。 - 当时序彼此具有差异性行为时,准确度可能更高。 |
- 无跨时序学习。 - 无法从 Azure 机器学习工作室配置或运行多模型作业。 当前只能使用代码/SDK 体验。 |
| 分层时序 (HTS) | 如果数据中的序列具有嵌套的分层结构,并且需要在层次结构的聚合级别训练或进行预测,建议使用。 有关详细信息,请参阅分层时序预测文章部分。 | - 在聚合级别进行训练可以减少叶节点时序中的干扰,并可能使模型的准确性更高。 - 可以通过从训练级别聚合或分解预测来检索层次结构的任何级别的预测。 |
- 需要提供用于训练的聚合级别。 AutoML 当前没有用于查找最佳级别的算法。 |
注意
建议在启用深度学习时将计算节点与 GPU 配合使用,以充分利用高 DNN 容量。 与仅使用 CPU 的节点相比,训练时间要快得多。 有关详细信息,请参阅 GPU 优化虚拟机大小一文。
注意
HTS 的设计初衷是用于需要在层次结构中的聚合级别进行训练或预测的任务。 对于只需要叶节点训练和预测的分层数据,请转而使用许多模型。
如何防止过度拟合和数据泄露?
AutoML 使用机器学习最佳做法(例如交叉验证模型选择)来缓解许多过度拟合问题。 但是,存在其他可能导致过度拟合的来源:
输入数据包含派生自具有简单公式的目标的特征列。 例如,作为目标精确倍数的特征可以达到近乎完美的训练分数。 但是,该模型可能无法通用化为样本外数据。 我们建议在模型训练之前浏览数据,并删除“泄露”目标信息的列。
训练数据使用未来不可知的特征,一直到预测的边界。 AutoML 的回归模型目前假定所有特征在预测范围内都是已知的。 我们建议在训练之前浏览数据,并删除任何仅在历史中已知的特征列。
在数据的训练、验证或测试部分之间存在明显的结构差异(制度更迭)。 例如,想一想 COVID-19 大流行对 2020 年和 2021 年几乎任何商品的需求的影响。 这是制度更迭的经典范例。 由于制度更迭导致的过度拟合是需要解决的最具有挑战性的问题,因为它高度依赖于场景,并且可能需要深入了解才能识别。
作为第一道防线,请尝试保留总历史记录的 10 到 20% 用于验证数据或交叉验证数据。 如果训练历史记录较短,则并不总是可以保留此数量的验证数据,但这是最佳做法。 有关详细信息,请参阅训练和验证数据。
如果我的训练作业获得完美的验证分数,这意味着什么?
查看训练作业中的验证指标时,可能会看到完美分数。 完美分数意味着验证集的预测值和实际值相同或几乎相同。 例如,均方根误差等于 0.0 或 R2 分数为 1.0。
完美验证分数通常表示模型严重过度拟合,这可能是由于数据泄露导致的。 最佳操作方案是检查数据是否发生泄露,并删除导致泄漏的列。
如果我的时序数据没有定期间隔的观测值,该怎么办?
AutoML 的预测模型都要求训练数据定期对日历进行观测。 此要求包括每月或每年的观测等情况,其中两次观测的天数可能会有所不同。 在两种情况下,依赖于时间的数据可能无法满足此要求:
数据具有明确定义的频率,但缺少在系列中产生间隙的观测值。 在这种情况下,AutoML 会尝试检测频率,补全新的观测值缺口,并插补缺少的目标值和特征值。 用户可选择通过 SDK 设置或 Web UI 配置插补方法。 有关详细信息,请参阅自定义特征化。
数据没有明确定义的频率。 也就是说,观测之间的持续时间没有明显的模式。 比如来自销售点系统的事务数据就是一个示例。 在这种情况下,可以设置 AutoML 以将数据聚合到所选频率。 可以选择最适合数据和建模目标的常规频率。 有关详细信息,请参阅数据聚合。
如何选择主要指标?
主要指标非常重要,因为它对验证数据的价值决定了扫描和选择期间的最佳模型。 在预测任务中,标准化均方根误差 (NRMSE) 和标准化平均绝对误差 (NMAE) 通常是主要指标的最佳选择。
若要在它们之间进行选择,请注意,NRMSE 会比 NMAE 更多地惩罚训练数据中的离群值,因为它使用误差的平方。 如果希望模型对离群值不那么敏感,则 NMAE 可能是更好的选择。 有关详细信息,请参阅回归和预测指标。
注意
不建议使用 R2 分数 (R2) 作为预测的主要指标。
注意
AutoML 不支持将自定义或用户提供的函数作为主要指标。 必须选择一个 AutoML 支持的预定义主要指标。
如何提高模型的准确性?
- 确保为你的数据以最佳方式配置 AutoML。 有关详细信息,请参阅“应使用哪种建模配置?”的解答。
- 查看预测食谱笔记本,获取生成和改进预测模型的分步指南。
- 在多个预测周期中使用反向测试评估模型。 此过程能够提供更可靠的预测误差估算,并为你提供衡量改进的基线。 有关示例,请参阅反向测试笔记本。
- 如果数据有干扰,请考虑将其聚合为较粗糙的频率,以提高信噪比。 有关详细信息,请参阅频率和目标数据聚合。
- 添加可能有助于预测目标的新特征。 在选择训练数据时,主题专业知识大有帮助。
- 比较验证和测试指标值,并确定所选模型是否欠拟合或过度拟合了数据。 此知识可指导你进行更好的训练配置。 例如,你可能会决定需要使用更多的交叉验证折叠来响应过度拟合。
在训练数据和配置相同的情况下,AutoML 会始终选择同一个最佳模型吗?
AutoML 的模型搜索过程不是确定性的,因此在数据和配置相同的情况下,它并不总是选择相同的模型。
如何解决内存不足的错误?
有两种类型的内存错误:
- RAM 内存不足
- 磁盘内存不足
首先,请确保以最佳方式为数据配置 AutoML。 有关详细信息,请参阅“应使用哪种建模配置?”的解答。
对于默认的 AutoML 设置,可以使用具有更多 RAM 的计算节点来解决 RAM 内存不足错误。 一条一般规则是,可用 RAM 的量应至少是原始数据的 10 倍,才能使用默认设置运行 AutoML。
可以通过删除计算群集并创建新群集来解决磁盘内存不足错误。
AutoML 支持哪些高级预测方案?
AutoML 支持以下高级预测方案:
- 分位数预测
- 通过滚动预测进行可靠的模型评估
- 超出预测范围的预测
- 训练和预测周期之间存在时间差距时进行预测
有关示例和详细信息,请参阅高级预测方案笔记本。
如何查看预测训练作业中的指标?
若要查找训练和验证指标值,请参阅在工作室中查看作业或运行的相关信息。 你可以从工作室中的 AutoML 作业 UI 转到模型并选择“指标”选项卡,查看在 AutoML 中训练的任何预测模型的指标。
如何调试预测训练作业的故障?
如果 AutoML 预测作业失败,工作室 UI 中会显示一条错误消息,它可帮助诊断和解决问题。 除错误消息之外,有关失败的最佳信息来源是作业的驱动程序日志。 有关查找驱动程序日志的说明,请参阅使用 MLflow 查看作业/运行信息。
注意
对于多模型或 HTS 作业,训练通常在多节点计算群集上。 每个节点 IP 地址都存在这些作业的日志。 在这种情况下,需要在每个节点中搜索错误日志。 错误日志以及驱动程序日志位于每个节点 IP 的 user_logs 文件夹中。
如何部署预测训练作业中的模型?
可以通过以下任一方式部署预测训练作业中的模型:
- 联机终结点:可以检查部署中使用的评分文件,或单击工作室的终结点页上的“测试”选项卡,了解部署预期的输入结构。 有关示例,请参阅此笔记本。 有关联机部署的详细信息,请参阅将 AutoML 模型部署到联机终结点。
- 批处理终结点:此部署方法要求你开发自定义评分脚本。 有关示例,请参阅此笔记本。 有关批处理部署的详细信息,请参阅使用批处理终结点进行批量评分。
对于 UI 部署,我们建议使用以下选项之一:
- 实时终结点
- 批处理终结点
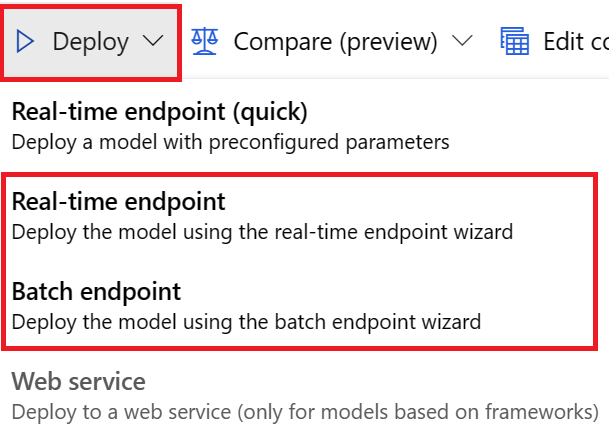
请不要使用第一个选项,即“实时终结点(快速)”。
注意
目前,我们不支持通过 SDK、CLI 或 UI 部署预测训练作业中的 MLflow 模型。 如果尝试此操作,将遇到错误。
什么是工作区、环境、试验、计算实例或计算目标?
如果你不熟悉 Azure 机器学习的概念,请先阅读“什么是 Azure 机器学习?”一文和“什么是 Azure 机器学习工作区?”一文。
后续步骤
- 详细了解如何设置 AutoML 来训练时序预测模型。
- 了解 AutoML 中时序预测的日历功能。
- 了解 AutoML 如何使用机器学习生成预测模型。
- 了解 AutoML 用于预测的滞后特征。