Azure 机器学习中的深度学习与机器学习
本文介绍深度学习与机器学习,以及它们在人工智能这一更广泛的范畴中的适用程度如何。 了解可基于 Azure 机器学习构建的深度学习解决方案,如欺诈检测、语音和人脸识别、情绪分析以及时序预测。
有关为解决方案选择算法的指南,请参阅机器学习算法备忘单。
深度学习、机器学习和 AI
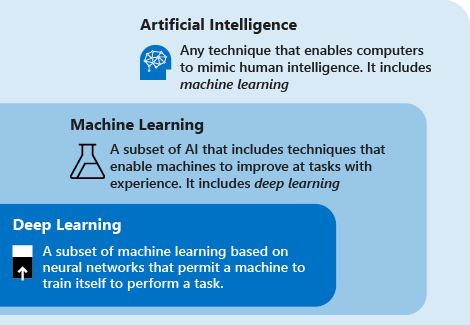
请查看以下定义来了解深度学习、机器学习与AI:
深度学习是机器学习的子集,它基于人工神经网络。 学习过程之所以是深度性的,是因为人工神经网络的结构由多个输入、输出和隐藏层构成。 每个层包含的单元可将输入数据转换为信息,供下一层用于特定的预测任务。 得益于这种结构,机器可以通过自身的数据处理进行学习。
机器学习是人工智能的子集,它采用可让机器凭借经验在任务中做出改善的技术(例如深度学习)。 学习过程基于以下步骤:
- 将数据馈送到算法中。 (在此步骤中,可向模型提供更多信息,例如,通过执行特征提取。)
- 使用此数据训练模型。
- 测试并部署模型。
- 使用部署的模型执行自动化预测任务。 (换言之,调用并使用部署的模型来接收模型返回的预测。)
人工智能 (AI) 是使机器能够模拟人类智能的技术。 其中包括机器学习。
生成式 AI 是人工智能的一部分,可使用深度学习等技术生成新的内容。 例如,可以使用生成式 AI 创建图像、文本或音频。 这些模型利用大量预先训练的知识来生成此内容。
使用机器学习和深度学习技术,可以构建所需的计算机系统和应用程序来执行通常与人类智能相关的任务。 这些任务包括图像识别、语音识别和语言翻译。
深度学习与机器学习的技术
获得机器学习和深度学习的概述后,接下来让我们比较这两种技术。 在机器学习中,需要告知算法如何使用更多信息做出准确的预测(例如,通过执行特征提取)。 在深度学习中,得益于人工神经网络结构,算法可以了解如何通过自身的数据处理做出准确预测。
下表更详细地比较了这两种技术:
| 所有机器学习 | 仅限深度学习 | |
|---|---|---|
| 数据点数 | 可以使用少量的数据做出预测。 | 需要使用大量的训练数据做出预测。 |
| 硬件依赖项 | 可在低端机器上工作。 不需要大量的计算能力。 | 依赖于高端机器。 本身就能执行大量的矩阵乘法运算。 GPU 可以有效地优化这些运算。 |
| 特征化过程 | 需要可准确识别且由用户创建的特征。 | 从数据中习得高级特征,并自行创建新的特征。 |
| 学习方法 | 将学习过程划分为较小的步骤。 然后,将每个步骤的结果合并成一个输出。 | 通过端到端地解决问题来完成学习过程。 |
| 执行时间 | 花费几秒到几小时的相对较少时间进行训练。 | 通常需要很长的时间才能完成训练,因为深度学习算法涉及到许多层。 |
| 输出 | 输出通常是一个数值,例如评分或分类。 | 输出可以采用多种格式,例如文本、评分或声音。 |
什么是迁移学习?
训练深度学习模型通常需要大量的训练数据、高端计算资源(GPU、TPU)和较长的训练时间。 在你不具备上述任何条件的情况下,可以使用一种称为“迁移学习”的技术来缩短训练过程。
迁移学习是一种将解决某个问题时获得的知识应用于虽然不同但却相关的问题的技术。
由于神经网络结构的原因,第一组层通常包含较低层次的特征,而最后一组层则包含更接近相关领域的较高层次的特征。 通过重新调整最终层在新领域或问题中的用途,可以显著减少训练新模型所需的时间、数据和计算资源量。 例如,如果已有一个识别汽车的模型,则可使用迁移学习重新调整该模型的用途,使之也识别卡车、摩托车和其他类型的车辆。
了解如何使用 Azure 机器学习中的开源框架将迁移学习应用于图像分类:使用迁移学习训练深度学习 PyTorch 模型
深度学习用例
由于采用人工神经网络结构,在识别图像、声音、视频和文本等非结构化数据中的模式时,深度学习具有卓越的性能。 出于此原因,深度学习正在快速变革许多行业,包括医疗保健、能源、金融和运输。 这些行业正在反思传统的业务流程。
以下段落介绍了深度学习的一些最常见应用场合。 在 Azure 机器学习中,你可以使用你基于开源框架构建的模型,也可以使用所提供的工具构建模型。
命名实体识别
命名实体识别是一种深度学习方法,它提取一段文本作为输入,然后将其转换为预先指定的类。 此新信息可以是邮政编码、日期和产品 ID。 然后,可将此信息存储在结构化架构中以生成地址列表,或将其用作标识验证引擎的基准。
对象检测
深度学习已应用于许多对象检测用例。 对象检测用于识别图像中的对象(如汽车或人员),并使用边框提供每个对象的位置。
对象检测已在游戏、零售、旅游和自动驾驶汽车等行业中使用。
图像说明生成
与图像识别一样,在图像说明中,对于给定的图像,系统必须生成一段说明来描述图像的内容。 如果可以在照片中检测和标记对象,则下一步是将这些标签转换为描述性的句子。
通常,图像说明应用程序使用卷积神经网络来识别图像中的对象,然后使用递归神经网络将标签转换为一致的句子。
机器翻译
机器翻译提取某种语言的单词或句子,并自动将其翻译成另一种语言。 机器翻译由来已久,但深度学习能够在两个具体的方面实现令人印象深刻的结果:自动翻译文本(以及将语音翻译成文本)和自动翻译图像。
神经网络可以使用相应的数据转换来理解文本、音频和视觉信号。 机器翻译可用于识别较大音频文件中的声音片段,并将口述单词或图像听录为文本。
文本分析
基于深度学习方法的文本分析涉及到分析大量文本数据(例如医疗文档或开支收据)、识别模式,并从中创建有条理的简洁信息。
公司可以使用深度学习来执行文本分析,以检测内幕交易以及政府法规的合规性。 另一个常见示例是保险欺诈:人们经常使用文本分析来分析大量的文件,以识别欺诈性保险索赔的可能性。
人工神经网络
人工神经网络由连接的节点层构成。 深度学习模型使用包含大量层的神经网络。
以下部分探讨最流行的人工神经网络拓扑。
前馈神经网络
前馈神经网络是最简单的人工神经网络类型。 在前馈网络中,信息只朝一个方向移动:从输入层移向输出层。 前馈神经网络通过使某个输入经历一系列隐藏层来转换该输入。 每个层由一组神经元组成,每个层完全连接到前一层中的所有神经元。 最后一个完全连接的层(输出层)代表生成的预测。
循环神经网络 (RNN)
递归神经网络是广泛使用的人工神经网络。 这些网络保存层的输出,并将其馈送回到输入层,以帮助预测该层的结果。 递归神经网络具有极高的学习能力。 它们广泛应用于时序预测、学习手写和识别语言等复杂任务。
卷积神经网络 (CNN)
卷积神经网络是特别高效的人工神经网络,它提供独特的体系结构。 层组织成三个维度:宽度、高度和深度。 一个层中的神经元不会连接到下一层中的所有神经元,而只连接到下一层神经元的较小区域。 最终输出化简为沿深度维组织的单个概率评分向量。
卷积神经网络已在视频识别、图像识别和推荐器系统等领域中使用。
生成对抗网络 (GAN)
生成对抗网络是为创建真实内容(如映像)而训练的生成模型。 它由两个称为“生成器”和“鉴别器”的网络组成。 这两个网络同时进行训练。 在训练过程中,生成器使用随机噪音来创建新合成数据(与真实数据非常相似)。 鉴别器将生成器的输出作为输入,并使用实际数据来确定生成的内容是真实内容还是合成内容。 两个网络彼此竞争。 生成器正在尝试生成与真实内容几乎没有差别的合成内容,而鉴别器正在尝试将输入正确分类为真实或合成内容。 这一输出随后将被用来更新两个网络的权重,帮助它们更好地实现各自的目标。
生成对抗网络用于解决映像转换和时限进度等问题。
Transformers
转换器是一种模型体系结构,适用于解决包含序列(如文本或时序数据)的问题。 它们包含编码器层和解码器层。 编码器接受输入,并将其映射到包含上下文等信息的数值表示形式。 解码器使用编码器中的信息生成输出,例如已翻译文本。 使转换器不同于包含编码器和解码器的其他体系结构的是关注子层。 关注是指根据其上下文相对于序列中其他输入的重要性,专注于输入的特定部分。 例如,在总结一篇新闻文章时,并不是所有句子都与描述中心思想相关。 通过把重点放在文章的关键词上,总结可以用一句话来完成,即标题。
转换器已用于解决自然语言处理问题,例如翻译、文本生成、问题解答和文本摘要。
转换器的一些著名实现有:
- Bidirectional Encoder Representations from Transformers (BERT)
- Generative Pre-trained Transformer 2 (GPT-2)
- Generative Pre-trained Transformer 3 (GPT-3)
后续步骤
以下文章介绍了在 Azure 机器学习中使用开源深度学习模型的更多选项: