分区和示例组件
本文介绍 Azure 机器学习设计器中的一个组件。
使用分区和采样组件来对数据集执行采样或从数据集创建分区。
采样是机器学习中的一个重要工具,因为通过采样可以减小数据集的大小,同时使值的比率保持相同。 该组件支持机器学习中几个重要的相关任务:
将数据划分为多个大小相同的小节。
可以将分区用于交叉验证,或用于将事例分配给随机组。
将数据分成组,然后处理特定组中的数据。
将事例随机分配给不同的组后,可能需要修改只与一个组关联的特征。
采样。
可以提取一定百分比的数据,应用随机采样,也可以选择一列用于均衡数据集并对其值进行分层采样。
创建更小的数据集用于测试。
如果存在大量数据,可以在设置管道时使用前 n 行,然后在构建模型时转为使用完整数据集。 也可以使用采样创建更小的数据集,以便在开发环境中使用。
配置组件
此组件支持采用下列方法将数据划分为分区或进行采样。 请先选择方法,然后设置方法所需的其他选项。
- 头
- 采样
- 分配到折叠
- 选取折叠
获取数据集中的前 N 行
使用此模式只能获取前 n 行。 如果要使用少量行测试管道,而不需要以任何方式均衡数据或对其进行采样,则此选项很有用。
在界面中将“分区和采样”组件添加到管道,并连接数据集。
分区模式或采样模式:将此选项设置为“Head”。
要选择的行数:输入要返回的行数。
行数必须为非负整数。 如果所选行数大于数据集中的行数,则返回整个数据集。
提交管道。
组件输出单个数据集,其中只包含指定行数。 始终从数据集的顶部开始读行。
创建数据样本
此选项支持简单随机采样或分层随机采样。 如果要创建用于测试的小型代表性样本数据集,则可以使用它。
将“分区和采样”组件添加到管道,并连接数据集。
分区或采样模式:将此选项设置为“采样”。
采样率:请输入介于 0 和 1 之间的值。 此值指定输出数据集应包含的行数占源数据集中行数的百分比。
例如,如果只需要占原始数据集一半的数据,则输入
0.5,表示采样率应为 50%。根据指定的比率,随机排列输入数据集中的行,并将其有选择地放入输出数据集。
用于采样的随机种子:(可选)输入一个要用作种子值的整数。
如果希望每次都按相同的方式划分多个行,则此选项非常重要。 默认值为 0,表示根据系统时钟生成起始种子。 此值可能会导致每次运行管道的结果略有不同。
用于采样的分层拆分:如果数据集中的行在采样之前按某些键列平均划分,请选择此选项。
对于用于采样的分层键列,请选择一个单独的分层列,以供划分数据集时使用。 然后,将数据集中的行划分如下:
所有输入行均按指定分层列中的值分组(分层)。
对每个组中的行进行随机排列。
将每个组有选择地添加到输出数据集中以满足指定比例。
提交管道。
使用此选项时,组件将输出单个数据集,其中包含数据的代表性采样。 不会输出数据集的未采样部分。
将数据拆分到多个分区
要将数据集划分为数据子集时,请使用此选项。 要创建自定义数量的折叠以用于交叉验证,或将行拆分为多个组,此选项也很有用。
将“分区和采样”组件添加到管道,并连接数据集。
对于分“区或采样模式”,选择“分配到折叠” 。
在分区中使用替换:如果希望将采样行放回到行池中以允许重用,请选择此选项。 因此,可以将同一行分配到多个折叠。
如果不使用替换(默认选项),则不会将采样行放回到行池中以允许重用。 因此,只能将每行分配到一个折叠。
随机拆分:如果要将行随机分配到折叠,请选择此选项。
如果不选择此选项,则通过轮询机制方法将行分配到折叠。
随机种子:(可选)输入一个要用作种子值的整数。 如果希望每次都按相同的方式划分多个行,则此选项非常重要。 否则,默认值 0 表示将使用随机起始种子。
指定分区方法:使用以下选项,指示如何将数据分配到每个分区:
平均分区:使用此选项可使每个分区中的行数相等。 若要指定输出分区的数目,请在“指定要平均拆分的折叠数”框中输入整数。
使用自定义比例进行分区:使用此选项可以用逗号分隔的列表指定每个分区的大小。
例如,假设要创建三个分区。 第一个分区将包含 50% 的数据。 其余两个分区每个包含 25% 的数据。 在“以逗号分隔的比例列表”框中,输入以下数字: .5、.25、.25。
所有分区大小的总和必须正好是 1。
如果输入的数字加起来小于 1,则将创建一个额外的分区来容纳剩余的行。 例如,如果输入的值为 .2 和 .3,则会创建第三个分区,用于容纳所有行的其余 50%。
如果输入的数字加起来大于 1,则在运行管道时会引发错误。
分层拆分:如果希望在拆分时对行进行分层,请选择此选项,然后选择“分层列”。
提交管道。
如果选择此选项,该组件将输出多个数据集。 数据集根据指定的规则分区。
使用预定义分区中的数据
如果已将数据集划分为多个分区,而现在想要依次加载每个分区以进行进一步分析或处理,请使用此选项。
将“分区和示例”组件添加到管道。
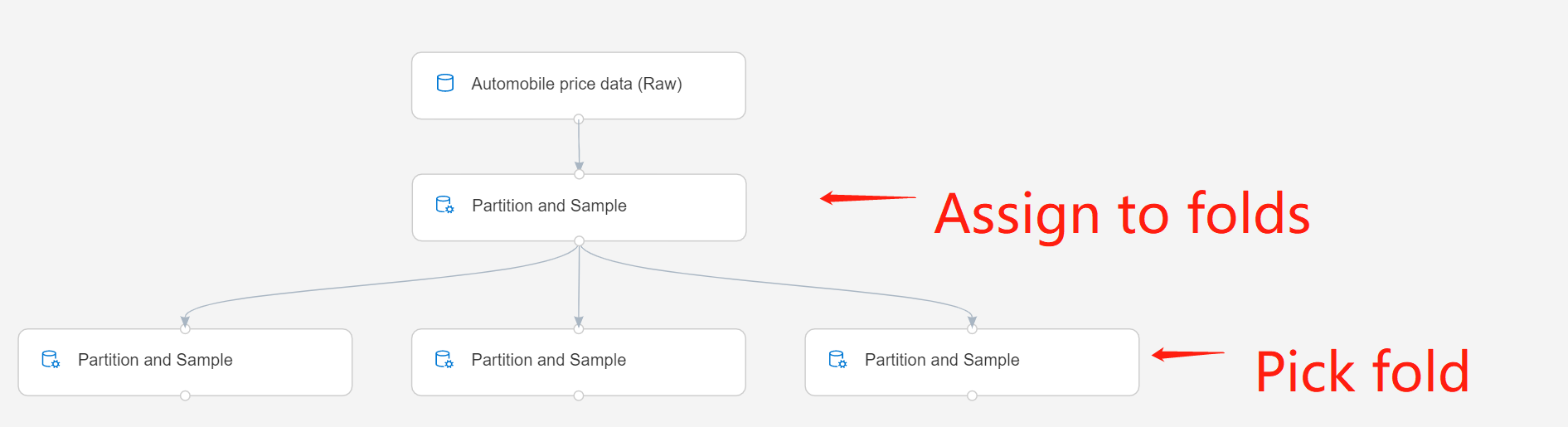
将组件连接到前一个“分区和示例”实例的输出。 此实例必须使用“分配到折叠”选项才能生成一定数量的分区。
分区模式或采样模式:选择“选取折叠”。
指定要采样的折叠:通过输入分区索引来选择要使用的分区。 分区索引从 1 开始。 例如,如果将数据集划分为三个部分,则分区的索引分别为 1、2 和 3。
如果输入无效的索引值,则会引发设计时错误:“Error 0018:数据集包含无效数据。”
除了将数据集按折叠分组,还可以将数据集分成两个组:目标折叠和其他所有内容。 为此,请输入单个折叠的索引,然后选择选项“选取所选折叠的补集”,以获取除指定折叠中数据以外的所有内容。
如果使用多个分区,则必须添加更多的“分区和示例”组件实例来处理每个分区。
例如,第二行的“分区和示例”组件设置为“分配到折叠”,第三行的组件设置为“拾取折叠”。
提交管道。
使用此选项,组件输出一个数据集,其中仅包含分配给该折叠的行。
注意
不能直接查看折叠指定情况。 此信息仅存在于元数据中。
后续步骤
请参阅 Azure 机器学习可用的组件集。