“规范化数据”组件
本文介绍 Azure 机器学习设计器中的一个组件。
使用此组件通过规范化来转换数据集。
规范化是一种通常用于机器学习数据准备的方法。 规范化旨在将数据集中数值列的值更改为使用通用范围,而不会扭曲值范围内的差异或丢失信息。 一些算法还需要通过规范化正确建立数据模型。
例如,假设输入数据集包含值范围从 0 到 1 的列以及另一个值范围从 10,000 到 100,000 的列。 如果在建模期间尝试将值作为特征合并,数字范围的巨大差异可能会导致问题。
“规范化”通过创建新值来保持源数据中的一般分布和比率,同时将值保持在模型中使用的所有数字列所采用的范围内,避免了这些问题。
此组件提供多种用于转换数值数据的选项:
- 可以将所有值更改为 0-1 范围,也可以将值转换为百分位数而不是绝对值。
- 可以将规范化应用于单个列或同一数据集中的多个列。
- 如果需要重复管道或对其他数据应用相同的规范化步骤,则可以以规范化转换形式保存这些步骤,并将其应用于具有相同架构的其他数据集。
警告
某些算法要求在训练模型之前对数据进行规范化。 其他算法执行自己的数据缩放或规范化。 因此,选择构建预测模型所使用的机器学习算法时,请务必在对训练数据应用规范化之前,查看算法的数据要求。
配置规范化数据
使用此组件一次只能应用一种规范化方法。 因此,同一规范化方法会应用于所选的所有列。 若要使用不同的规范化方法,请使用“规范化数据”的第二个实例。
将“规范化数据”组件添加到管道。 可以在 Azure 机器学习的“数据转换”下的“缩放和约简”类别中找到此组件 。
连接包含所有数值的至少一列的数据集。
使用列选择器选择要规范化的数值列。 如果不选择单个列,则默认包括输入中的所有数值类型列,并对所有选定列应用同一规范化流程。
如果包括不应规范化的数值列,这可能会导致奇怪的结果! 请务必仔细检查列。
如果未检测到数值列,请检查列元数据,验证列的数据类型是否是支持的数值类型。
提示
若要确保将特定类型的列作为输入提供,请尝试在使用“规范化数据”组件之前使用在数据集中选择列组件。
选中时,对常量列使用 0:如果任何数值列包含一个不变值,请选择此选项。 这可确保在规范化操作中不会使用这样的列。
从“转换方法”下拉列表中,选择要应用于所有选定列的单个数学函数。
Zscore:将所有值转换为 z-score。
使用以下公式转换列中的值:
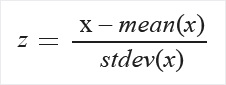
分别针对每个列计算平均偏差和标准偏差。 使用总体标准偏差。
MinMax:min-max 规范化器将每个特征线性重缩放为 [0,1] 区间。
移动每个特征的值以重缩放为 [0,1] 区间,使最小值为 0,然后除以新的最大值(这是初始最大值和初始最小值之间的差异)。
使用以下公式转换列中的值:

Logistic:使用以下公式转换列中的值:

LogNormal:此选项将所有值转换为对数范围。
使用以下公式转换列中的值:

此处,μ 和 σ 为分布的参数,根据数据按经验计算为分别针对每一列的最大似然估计。
TanH:所有值转换为双曲正切。
使用以下公式转换列中的值:

提交管道,或双击“规范化数据”组件,然后选择“运行所选项”。
结果
“规范化数据”组件会生成两个输出:
若要查看转换后的值,请右键单击组件,然后选择“可视化”。
默认情况下,值会立即转换。 如果要将转换后的值与原始值进行比较,请使用添加列组件来重新组合数据集并以并排方式查看列。
若要保存转换,以便将相同的规范化方法应用于另一个数据集,请选择该组件,然后选择右侧面板中“输出”选项卡下的“注册数据集”。
然后,可以从左侧导航窗格的“转换”组中加载已保存的转换,并使用应用转换将其应用到具有相同架构的数据集。
后续步骤
请参阅 Azure 机器学习可用的组件集。