“执行 Python 脚本”组件
本文介绍 Azure 机器学习设计器中的“执行 Python 脚本”组件。
使用此组件运行 Python 代码。 有关 Python 体系结构和设计原理的详细信息,请参阅如何在 Azure 机器学习设计器中运行 Python 代码。
使用 Python,可以执行现有组件不支持的任务,例如:
- 使用
matplotlib将数据可视化。 - 使用 Python 库枚举工作区中的数据集和模型。
- 从“导入数据”组件不支持的源读取、加载和操作数据。
- 运行自己的深度学习代码。
支持的 Python 包
Azure 机器学习使用 Python 的 Anaconda 分发版,其中包括用于数据处理的许多常用实用工具。 我们将自动更新 Anaconda 版本。 当前版本为:
- Python 3.6 的 Anaconda 4.5 + 分发版
有关完整列表,请参阅预安装的 Python 包部分。
若要安装不在预安装列表中的包(例如 scikit-misc),请将以下代码添加到脚本中:
import os
os.system(f"pip install scikit-misc")
使用以下代码来安装包,以便提高性能(尤其是推理方面):
import importlib.util
package_name = 'scikit-misc'
spec = importlib.util.find_spec(package_name)
if spec is None:
import os
os.system(f"pip install scikit-misc")
注意
如果你的管道包含需要不在预安装列表中的包的多个“执行 Python 脚本”组件,请在每个组件中安装这些包。
警告
“执行 Python 脚本”组件不支持使用“apt-get”等命令来安装依赖于额外本机库的包(如 Java、PyODBC 等)。这是因为此组件仅在预安装了 Python 且具有非管理员权限的简单环境中执行。
访问当前工作区和已注册的数据集
可以参阅以下示例代码,在工作区中访问已注册的数据集:
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from azureml.core import Run
run = Run.get_context(allow_offline=True)
#access to current workspace
ws = run.experiment.workspace
#access to registered dataset of current workspace
from azureml.core import Dataset
dataset = Dataset.get_by_name(ws, name='test-register-tabular-in-designer')
dataframe1 = dataset.to_pandas_dataframe()
# If a zip file is connected to the third input port,
# it is unzipped under "./Script Bundle". This directory is added
# to sys.path. Therefore, if your zip file contains a Python file
# mymodule.py you can import it using:
# import mymodule
# Return value must be of a sequence of pandas.DataFrame
# E.g.
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
上传文件
“执行 Python 脚本”组件支持使用 Azure 机器学习 Python SDK 来上传文件。
以下示例演示如何在“执行 Python 脚本”组件中上传映像文件:
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Imports up here can be used to
import pandas as pd
# The entry point function must have two input arguments:
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
plt.savefig(img_file)
from azureml.core import Run
run = Run.get_context(allow_offline=True)
run.upload_file(f"graphics/{img_file}", img_file)
# Return value must be of a sequence of pandas.DataFrame
# For example:
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
管道运行完成后,可以在组件的右侧面板中预览图像。
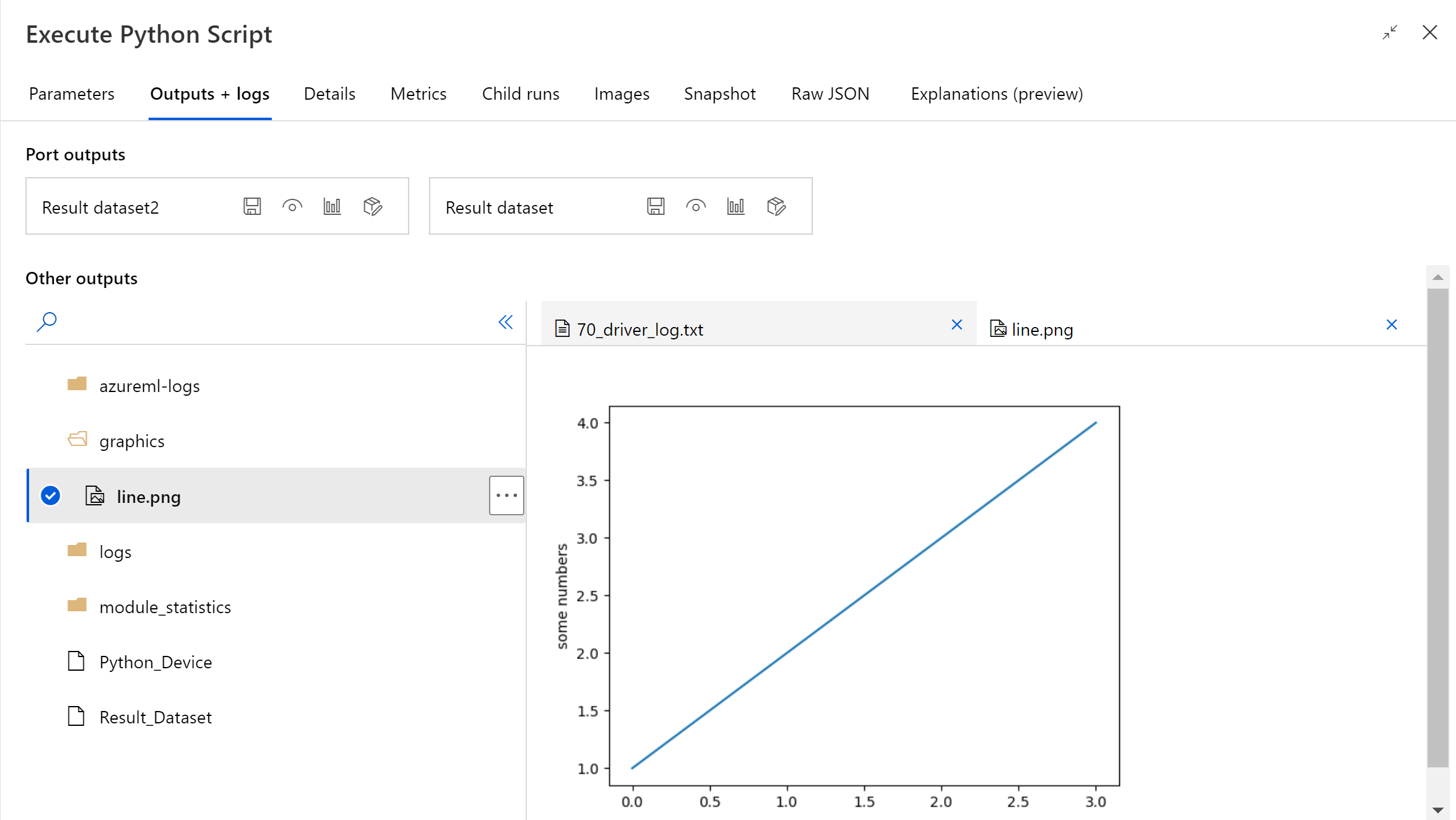
你还可以使用以下代码将文件上传到任何数据存储。 只能预览存储帐户中的文件。
import pandas as pd
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be None.
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
import os
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
# Set path
path = "./img_folder"
os.mkdir(path)
plt.savefig(os.path.join(path,img_file))
# Get current workspace
from azureml.core import Run
run = Run.get_context(allow_offline=True)
ws = run.experiment.workspace
# Get a named datastore from the current workspace and upload to specified path
from azureml.core import Datastore
datastore = Datastore.get(ws, datastore_name='workspacefilestore')
datastore.upload(path)
return dataframe1,
如何配置“执行 Python 脚本”
“执行 Python 脚本”组件包含可用作起点的示例 Python 代码。 若要配置“执行 Python 脚本”组件,需要提供一组输入,并在“Python 脚本”文本框中提供要执行的 Python 代码。
将“执行 Python 脚本”组件添加到管道中。
从设计器中,在 Dataset1 上添加并连接要用于输入的任何数据集。 在 Python 脚本中将此数据集引用为 DataFrame1。
数据集的使用是可选的。 如果想使用 Python 生成数据,或者使用 Python 代码将数据直接导入组件中,请使用此组件。
该组件支持在 Dataset2 上添加第二个数据集。 在 Python 脚本中将第二个数据集引用为 DataFrame2。
如果加载时包含此组件,则存储在 Azure 机器学习中的数据集会自动转换为 Pandas 数据帧。
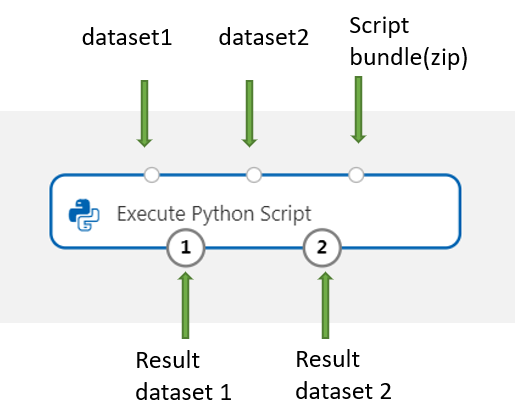
若要包括新的 Python 包或代码,请将包含这些自定义资源的压缩文件连接到脚本绑定端口。 或者,如果脚本大于 16 KB,请使用脚本绑定端口以避免错误,如命令行超过 16597 个字符的限制。
- 将脚本和其他自定义资源捆绑到一个 zip 文件中。
- 将 zip 文件作为“文件数据集”上传到工作室。
- 从设计器创作页面左侧组件窗格中的“数据集”列表中拖动数据集组件。
- 将数据集组件连接到“执行 Python 脚本”组件的“脚本捆绑”端口。
在管道执行期间,可以使用已上传的压缩存档中包含的任何文件。 如果存档中包含目录结构,则会保留结构。
重要
对于脚本捆绑包中的文件,请使用唯一且有意义的名称,因为针对内置服务保留了某些常用词(例如
test、app等)。下面是一个脚本绑定示例,其中包含一个 Python 脚本文件和一个 txt 文件:
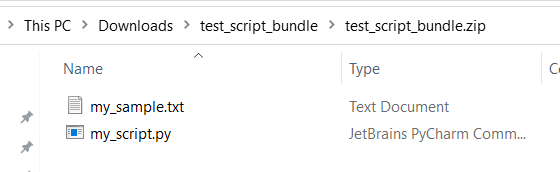
下面是
my_script.py的内容:def my_func(dataframe1): return dataframe1以下是示例代码,显示了如何使用脚本绑定中的文件:
import pandas as pd from my_script import my_func def azureml_main(dataframe1 = None, dataframe2 = None): # Execution logic goes here print(f'Input pandas.DataFrame #1: {dataframe1}') # Test the custom defined Python function dataframe1 = my_func(dataframe1) # Test to read custom uploaded files by relative path with open('./Script Bundle/my_sample.txt', 'r') as text_file: sample = text_file.read() return dataframe1, pd.DataFrame(columns=["Sample"], data=[[sample]])在“Python 脚本”文本框中,键入或粘贴有效的 Python 脚本。
注意
编写脚本时请细致谨慎。 确保没有语法错误,例如使用未声明的变量或未导入的组件或函数。 请特别注意预安装的组件列表。 要导入未列出的组件,请在脚本中安装相应的包,例如:
import os os.system(f"pip install scikit-misc")“Python 脚本”文本框中预先填充了注释中的某些说明,以及用于数据访问和输出的示例代码。 你必须编辑或替换此代码。 遵循有关缩进和大小写的 Python 约定:
- 该脚本必须包含一个名为
azureml_main的函数作为该组件的入口点。 - 入口点函数必须有两个输入参数
Param<dataframe1>和Param<dataframe2>,即使脚本中没有使用这些参数。 - 连接到第三个输入端口的压缩文件将被解压缩并存储在目录
.\Script Bundle中,该目录还会添加到 Pythonsys.path中。
如果 zip 文件包含
mymodule.py,请使用import mymodule导入它。可以向设计器返回两个数据集,数据集必须是
pandas.DataFrame类型的序列。 可以在 Python 代码中创建其他输出,并将其直接写入到 Azure 存储。- 该脚本必须包含一个名为
提交管道。
如果组件已完成,请检查输出是否符合预期。
如果组件出现故障,则需要进行一些故障排除。 选择组件,然后在右侧窗格中打开“输出+日志”。 打开 70_driver_log.txt,并搜索“in azureml_main”,然后可以找到导致错误的行。 例如,“File "/tmp/tmp01_ID/user_script.py", line 17, in azureml_main”表示错误发生在 Python 脚本的第 17 行。
结果
嵌入的 Python 代码的任何计算结果都必须以 pandas.DataFrame 形式提供,该格式将自动转换为 Azure 机器学习数据集格式。 然后,可以将结果与管道中的其他组件一起使用。
组件返回两个数据集:
结果数据集 1,由 Python 脚本中返回的第一个 pandas 数据帧定义。
结果数据集 2,由 Python 脚本中返回的第二个 pandas 数据帧定义。
预安装的 Python 包
预安装的包如下:
- adal==1.2.2
- applicationinsights==0.11.9
- attrs==19.3.0
- azure-common==1.1.25
- azure-core==1.3.0
- azure-graphrbac==0.61.1
- azure-identity==1.3.0
- azure-mgmt-authorization==0.60.0
- azure-mgmt-containerregistry==2.8.0
- azure-mgmt-keyvault==2.2.0
- azure-mgmt-resource==8.0.1
- azure-mgmt-storage==8.0.0
- azure-storage-blob==1.5.0
- azure-storage-common==1.4.2
- azureml-core==1.1.5.5
- azureml-dataprep-native==14.1.0
- azureml-dataprep==1.3.5
- azureml-defaults==1.1.5.1
- azureml-designer-classic-modules==0.0.118
- azureml-designer-core==0.0.31
- azureml-designer-internal==0.0.18
- azureml-model-management-sdk==1.0.1b6.post1
- azureml-pipeline-core==1.1.5
- azureml-telemetry==1.1.5.3
- backports.tempfile==1.0
- backports.weakref==1.0.post1
- boto3==1.12.29
- botocore==1.15.29
- cachetools==4.0.0
- certifi==2019.11.28
- cffi==1.12.3
- chardet==3.0.4
- click==7.1.1
- cloudpickle==1.3.0
- configparser==3.7.4
- contextlib2==0.6.0.post1
- cryptography==2.8
- cycler==0.10.0
- dill==0.3.1.1
- distro==1.4.0
- docker==4.2.0
- docutils==0.15.2
- dotnetcore2==2.1.13
- flask==1.0.3
- fusepy==3.0.1
- gensim==3.8.1
- google-api-core==1.16.0
- google-auth==1.12.0
- google-cloud-core==1.3.0
- google-cloud-storage==1.26.0
- google-resumable-media==0.5.0
- googleapis-common-protos==1.51.0
- gunicorn==19.9.0
- idna==2.9
- imbalanced-learn==0.4.3
- isodate==0.6.0
- itsdangerous==1.1.0
- jeepney==0.4.3
- jinja2==2.11.1
- jmespath==0.9.5
- joblib==0.14.0
- json-logging-py==0.2
- jsonpickle==1.3
- jsonschema==3.0.1
- kiwisolver==1.1.0
- liac-arff==2.4.0
- lightgbm==2.2.3
- markupsafe==1.1.1
- matplotlib==3.1.3
- more-itertools==6.0.0
- msal-extensions==0.1.3
- msal==1.1.0
- msrest==0.6.11
- msrestazure==0.6.3
- ndg-httpsclient==0.5.1
- nimbusml==1.6.1
- numpy==1.18.2
- oauthlib==3.1.0
- pandas==0.25.3
- pathspec==0.7.0
- pip==20.0.2
- portalocker==1.6.0
- protobuf==3.11.3
- pyarrow==0.16.0
- pyasn1-modules==0.2.8
- pyasn1==0.4.8
- pycparser==2.20
- pycryptodomex==3.7.3
- pyjwt==1.7.1
- pyopenssl==19.1.0
- pyparsing==2.4.6
- pyrsistent==0.16.0
- python-dateutil==2.8.1
- pytz==2019.3
- requests-oauthlib==1.3.0
- requests==2.23.0
- rsa==4.0
- ruamel.yaml==0.15.89
- s3transfer==0.3.3
- scikit-learn==0.22.2
- scipy==1.4.1
- secretstorage==3.1.2
- setuptools==46.1.1.post20200323
- six==1.14.0
- smart-open==1.10.0
- urllib3==1.25.8
- websocket-client==0.57.0
- werkzeug==0.16.1
- wheel==0.34.2
后续步骤
请参阅 Azure 机器学习可用的组件集。