了解处理 Apache Ambari 中的 Apache Spark 有效负载时的最常见问题及其解决方法。
如何在群集上使用 Apache Ambari 配置 Apache Spark 应用程序?
可以优化 Spark 配置值,帮助避免出现 Apache Spark 应用程序 OutofMemoryError 异常。 以下步骤显示了 Azure HDInsight 中的默认 Spark 配置值:
使用群集凭据通过
https://CLUSTERNAME.azurehdidnsight.cn登录到 Ambari。 初始屏幕显示了概述仪表板。 HDInsight 4.0 在外观上略有不同。导航到“Spark2”>“配置” 。
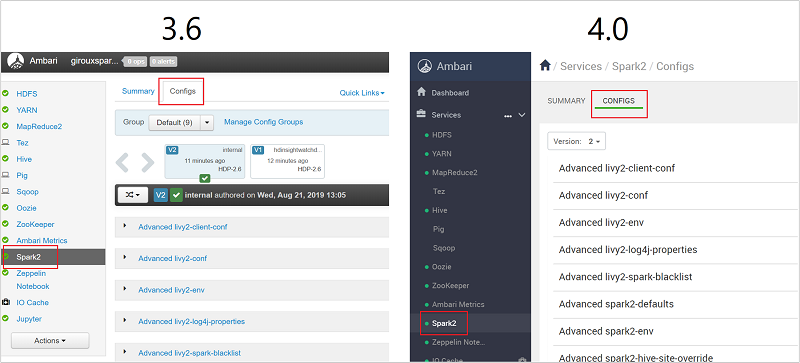
在配置列表中,选择并展开 Custom-spark2-Defaults。
找到需要调整的值设置,例如 spark.executor.memory。 在本例中,值 9728m 太大。
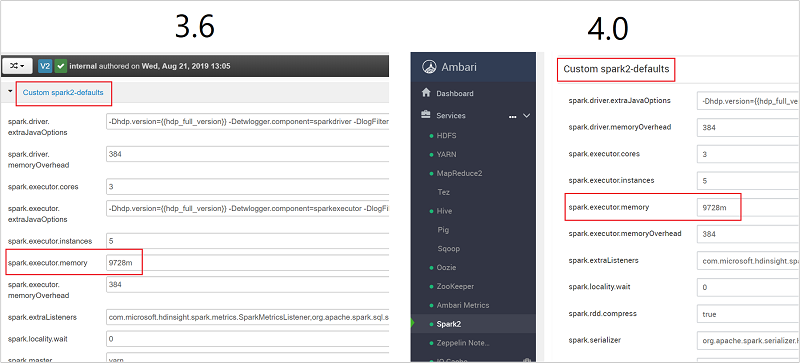
将值设置为建议的设置。 建议为此设置使用值 2048m。
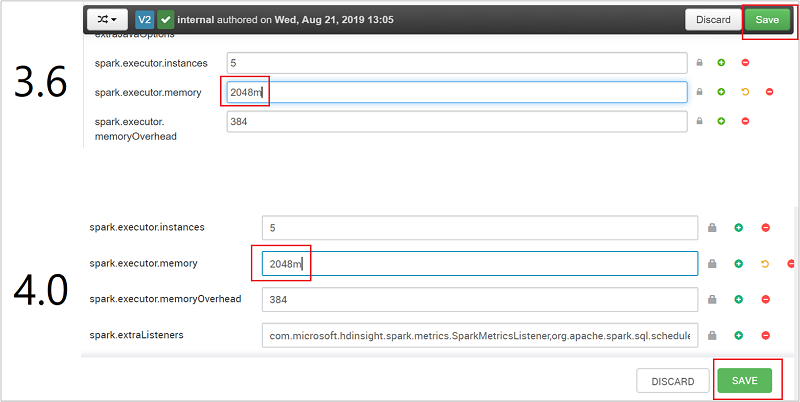
保存值,并保存配置。 选择“保存”。
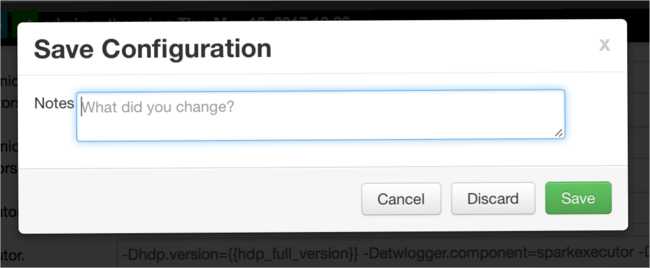
编写有关配置更改的注释,并选择“保存”。
如果有任何配置需要引以注意,系统会发出通知。 记下这些项,并选择“仍然继续”。

每次保存配置时,系统都会提示重启服务。 选择“重启”。
确认重启。
可以查看正在运行的进程。
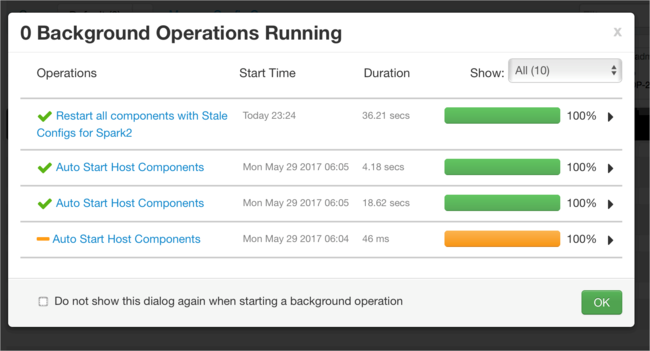
可以添加配置。 在配置列表中,依次选择“Custom-spark2-defaults”、“添加属性”。
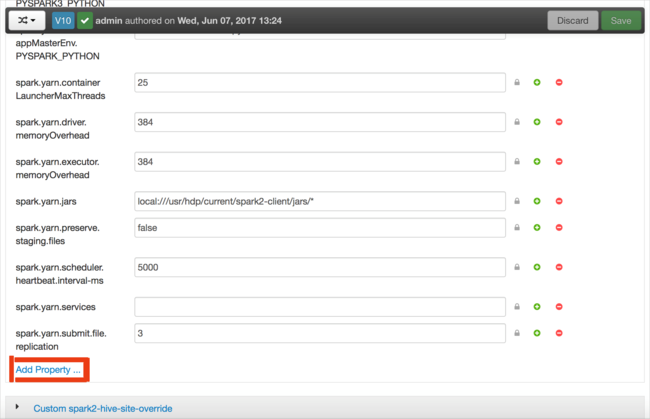
定义新属性。 可以使用对话框为特定的设置(例如数据类型)定义单个属性。 或者,可以定义多个属性(每行定义一个属性)。
在本示例中,使用值 4g 定义了 spark.driver.memory 属性。
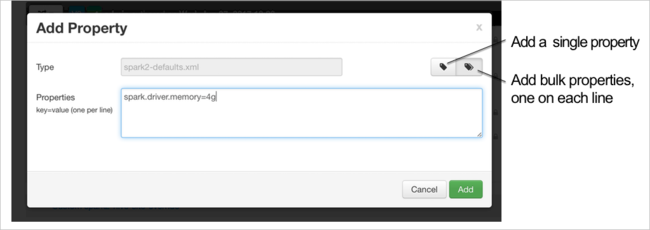
根据步骤 6 和 7 中所述保存配置并重启服务。
这些更改会应用到整个群集,但可以在提交 Spark 作业时将其覆盖。
如何在群集上使用 Jupyter Notebook 配置 Apache Spark 应用程序?
在 Jupyter Notebook 第一个单元中的 %%configure 指令后面,使用有效的 JSON 格式指定 Spark 配置。 根据需要更改实际值:

如何在群集上使用 Apache Livy 配置 Apache Spark 应用程序?
使用 cURL 等 REST 客户端将 Spark 应用程序提交到 Livy。 使用如下所示的命令。 根据需要更改实际值:
curl -k --user 'username:password' -v -H 'Content-Type: application/json' -X POST -d '{ "file":"wasb://container@storageaccountname.blob.core.chinacloudapi.cn/example/jars/sparkapplication.jar", "className":"com.microsoft.spark.application", "numExecutors":4, "executorMemory":"4g", "executorCores":2, "driverMemory":"8g", "driverCores":4}'
如何在群集上使用 spark-submit 配置 Apache Spark 应用程序?
使用如下所示的命令启动 spark-shell。 根据需要更改实际配置值:
spark-submit --master yarn-cluster --class com.microsoft.spark.application --num-executors 4 --executor-memory 4g --executor-cores 2 --driver-memory 8g --driver-cores 4 /home/user/spark/sparkapplication.jar
额外阅读
在 HDInsight 群集上提交 Apache Spark 作业
后续步骤
如果你的问题未在本文中列出,或者无法解决问题,请访问以下渠道之一获取更多支持:
如果需要更多帮助,可以从 Azure 门户提交支持请求。 从菜单栏中选择“支持” ,或打开“帮助 + 支持” 中心。