使用 Microsoft Entra ID 服务主体运行作业
作业提供了一种非交互式的方式来运行 Azure Databricks 群集中的应用程序,例如,ETL 作业或应按计划运行的数据分析任务。 通常,这些作业以创建它们的用户身份运行,但这可能有一些限制:
- 创建并运行作业取决于具有适当权限的用户。
- 只有创建作业的用户才能访问作业。
- 用户可能已从 Azure Databricks 工作区中删除。
使用服务帐户(与应用程序而不是特定用户关联的帐户)是解决这些限制的常用方法。 在 Azure 中,可使用 Microsoft Entra ID 应用程序和服务主体来创建服务帐户。
这一点非常重要,尤其是服务主体控制对存储在 Azure Data Lake Storage Gen2 帐户中的数据的访问时。 使用这些服务主体运行作业允许作业访问存储帐户中的数据,并提供对数据访问范围的控制。
本教程介绍如何创建 Microsoft Entra ID 应用程序和服务主体,并使该服务主体成为作业的所有者。 你还将了解如何向不拥有作业的其他组授予作业运行权限。 下面简要概述了本教程涉及的的任务:
- 在 Microsoft Entra ID 中创建一个服务主体。
- 在 Azure Databricks 中创建个人访问令牌 (PAT)。 你将使用 PAT 对 Databricks REST API 进行身份验证。
- 使用 Databricks SCIM API 将服务主体作为非管理用户添加到 Azure Databricks。
- 在 Azure Databricks 中创建 Azure Key Vault 支持的机密范围。
- 授予服务主体对机密范围的读取权限。
- 在 Azure Databricks 中创建一个作业,并将该作业群集配置为从机密范围读取机密。
- 将作业的所有权转移给服务主体。
- 通过将作业作为服务主体运行来测试该作业。
如果没有 Azure 订阅,请在开始前创建一个试用版订阅。
注意
不能使用启用了凭据直通的群集来运行服务主体拥有的作业。 如果作业需要服务主体才能访问 Azure 存储,请参阅使用 Azure 凭据连接到 Azure Data Lake Storage Gen2 或 Blob 存储。
要求
要完成本教程,需要以下各项:
- 拥有在 Microsoft Entra ID 租户中注册应用程序所需权限的用户帐户。
- 要在其中运行作业的 Azure Databricks 工作区中的管理权限。
- 用于向 Azure Databricks 发出 API 请求的工具。 本教程使用 cURL,但你可以使用任何允许你提交 REST API 请求的工具。
在 Microsoft Entra ID 中创建一个服务主体
服务主体是 Microsoft Entra ID 应用程序的标识。 创建将用于运行作业的服务主体:
- 在 Azure 门户中,选择“Microsoft Entra ID”>“应用注册”>“新建注册”。 输入应用程序的名称,然后单击“注册”。
- 转到“证书和机密”,单击“新建客户端机密”,并生成一个新的客户端机密。 将机密复制并保存在安全的位置。
- 转到“概述”,记下“应用程序(客户端) ID”和“目录(租户) ID” 。
创建 Azure Databricks 个人访问令牌
你将使用 Azure Databricks 个人访问令牌 (PAT) 对 Databricks REST API 进行身份验证。 创建可用于发出 API 请求的 PAT:
- 转到 Azure Databricks 工作区。
- 单击屏幕右上角的用户名,然后单击“设置”。
- 单击“开发人员”。
- 在“访问令牌”旁边,单击“管理”。
- 单击“生成新令牌”。
- 复制并保存令牌值。
提示
此示例使用个人访问令牌,但你可以对大多数 API 使用 Microsoft Entra ID 令牌。 最佳做法是,使用 PAT 执行管理配置任务,而使用 Microsoft Entra ID 令牌处理生产工作负载。
可以仅出于安全目的将 PAT 的生成限制为管理员。 有关详细信息,请参阅监视和管理个人访问令牌。
将服务主体添加到 Azure Databricks 工作区
使用服务主体 API 将 Microsoft Entra ID 服务主体添加到工作区。 还必须授予服务主体启动自动作业群集的权限。 可以通过 allow-cluster-create 权限授予此权限。 打开终端并使用 Databricks CLI 运行以下命令,以添加服务主体并授予所需的权限:
databricks service-principals create --json '{
"schemas":[
"urn:ietf:params:scim:schemas:core:2.0:ServicePrincipal"
],
"applicationId":"<application-id>",
"displayName": "test-sp",
"entitlements":[
{
"value":"allow-cluster-create"
}
]
}'
将 <application-id> 替换为 Microsoft Entra ID 应用程序注册的 Application (client) ID。
在 Azure Databricks 中创建 Azure Key Vault 支持的机密范围
机密范围提供机密的安全存储和管理。 需要将与服务主体关联的机密存储在机密范围中。 可将机密存储在 Azure Databricks 机密范围或 Azure Key Vault 支持的机密范围中。 以下说明介绍了 Azure Key Vault 支持的选项:
- 在 Azure 门户中创建 Azure Key Vault 实例。
- 创建由 Azure Key Vault 实例支持的 Azure Databricks 机密范围。
步骤 1:创建 Azure Key Vault 实例
在 Azure 门户中,选择“Key Vault”>“+ 添加”并为 Key Vault 命名。
单击“查看 + 创建” 。
验证完成后,单击“创建”。
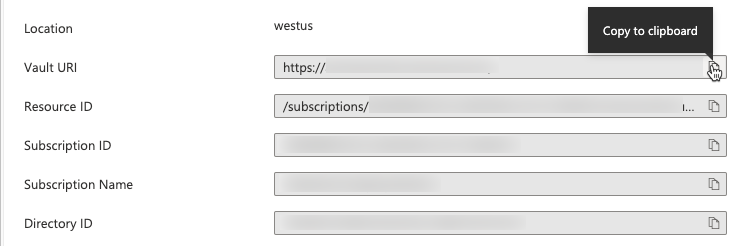
创建 Key Vault 之后,转到新 Key Vault 的“属性”页。
复制并保存“保管库 URI”和“资源 ID” 。
步骤2:创建 Azure Key Vault 支持的机密范围
Azure Databricks 资源可以通过创建 Key Vault 支持的机密范围来引用存储在 Azure Key Vault 中的机密。 创建 Azure Databricks 机密范围:
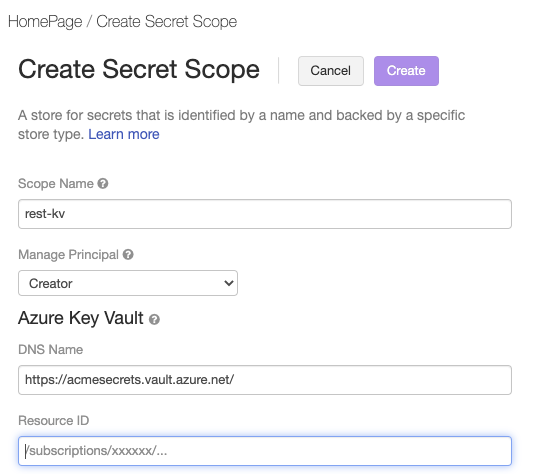
转到“Azure Databricks 创建机密范围”页面 (
https://<per-workspace-url>/#secrets/createScope)。 将per-workspace-url替换为 Azure Databricks 工作区的唯一每工作区 URL。输入“范围名称”。
为在步骤 1: 创建 Azure Key Vault 实例中创建的 Azure Key Vault 输入“保管库 URI”和“资源 ID”值。
单击 “创建” 。
将客户端机密保存到 Azure Key Vault
在 Azure 门户中,转到“Key Vault”服务。
选择在步骤 1:创建 Azure Key Vault 实例中创建的 Key Vault。
在“设置”>“机密”下,单击“生成/导入”。
选择“手动”上传选项,并在“值”字段中输入客户端机密。
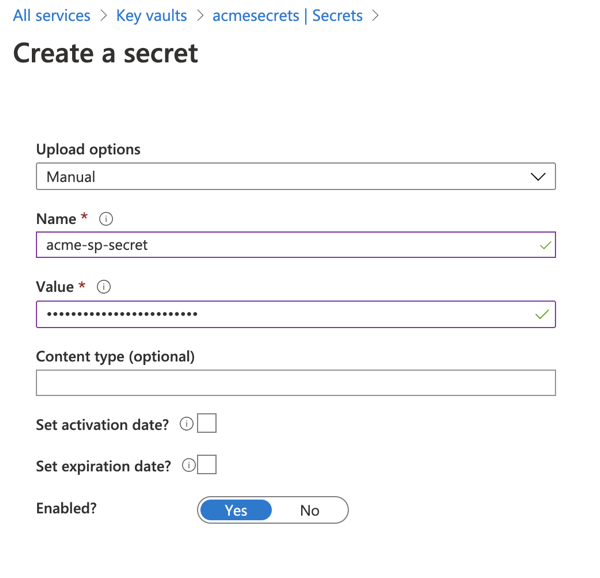
单击“创建”。
授予服务主体对机密范围的读取访问权限
你已创建了机密范围,并将服务主体的客户端机密存储在该范围中。 接下来,需要授予服务主体从机密范围读取机密的权限。
打开终端并使用 Databricks CLI 运行以下命令:
databricks secrets put-acl <scope-name> <application-id> READ
- 将
<scope-name>替换为包含客户端机密的 Azure Databricks 机密范围的名称。 - 将
<application-id>替换为 Microsoft Entra ID 应用程序注册的Application (client) ID。
在 Azure Databricks 中创建一个作业,并将群集配置为从机密范围读取机密
现在,你已准备好创建一个可以作为新服务主体运行的作业。 你将使用在 Azure Databricks UI 中创建的笔记本,并添加配置以允许作业群集检索服务主体的机密。
转到 Azure Databricks 登陆页并选择“新建”>“笔记本”。 为笔记本命名,然后选择“SQL”作为默认语言。
在笔记本的第一个单元格中输入
SELECT 1。 这是一个简单的命令,如果成功,只显示 1。 如果你已授予服务主体对 Azure Data Lake Storage Gen 2 中特定文件或路径的访问权限,则可以改为从这些路径读取。转到“工作流”并单击“创建作业”。 为作业和任务命名,单击“选择笔记本”,然后选择刚刚创建的笔记本。
单击群集信息旁边的“编辑”。
在“配置群集”页面上,单击“高级选项” 。
在“Spark”选项卡上,输入以下 Spark 配置:
fs.azure.account.auth.type.<storage-account>.dfs.core.chinacloudapi.cn OAuth fs.azure.account.oauth.provider.type.<storage-account>.dfs.core.chinacloudapi.cn org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider fs.azure.account.oauth2.client.id.<storage-account>.dfs.core.chinacloudapi.cn <application-id> fs.azure.account.oauth2.client.secret.<storage-account>.dfs.core.chinacloudapi.cn {{secrets/<secret-scope-name>/<secret-name>}} fs.azure.account.oauth2.client.endpoint.<storage-account>.dfs.core.chinacloudapi.cn https://login.chinacloudapi.cn/<directory-id>/oauth2/token- 将
<storage-account>替换为包含数据的存储帐户的名称。 - 将
<secret-scope-name>替换为包含客户端机密的 Azure Databricks 机密范围的名称。 - 将
<application-id>替换为 Microsoft Entra ID 应用程序注册的Application (client) ID。 - 将
<secret-name>替换为与机密范围中的客户端机密值关联的名称。 - 将
<directory-id>替换为 Microsoft Entra ID 应用程序注册的Directory (tenant) ID。
- 将
将作业的所有权转移给服务主体
一个作业只能有一个所有者,因此你需要将作业的所有权从你自己转移到服务主体。 若要确保其他用户可以管理作业,还可以向组授予“可以管理”权限。 在本例中,我们使用权限 API 来设置这些权限。
打开终端并使用 Databricks CLI 运行以下命令:
databricks permissions set jobs <job-id> --json '{
"access_control_list": [
{
"service_principal_name": "<application-id>",
"permission_level": "IS_OWNER"
},
{
"group_name": "admins",
"permission_level": "CAN_MANAGE"
}
]
}'
- 将
<job-id>替换为作业的唯一标识符。 若要查找作业 ID,请点击边栏中的“工作流程”,然后单击作业名称。 作业 ID 位于“作业详细信息”侧面板中。 - 将
<application-id>替换为 Microsoft Entra ID 应用程序注册的Application (client) ID。
该作业还需要对笔记本的读取权限。 使用 Databricks CLI 运行以下命令来授予所需的权限:
databricks permissions set notebooks <notebook-id> --json '{
"access_control_list": [
{
"service_principal_name": "<application-id>",
"permission_level": "CAN_READ"
}
]
}'
- 将
<notebook-id>替换为与作业关联的笔记本的 ID。 若要查找 ID,请转到 Azure Databricks 工作区中的笔记本,并在笔记本的 URL 中查找notebook/后面的数字 ID。 - 将
<application-id>替换为 Microsoft Entra ID 应用程序注册的Application (client) ID。
测试作业
使用服务主体运行作业的方式与使用用户身份运行作业的方式相同,无论是通过 UI、API 还是 CLI。 使用 Azure Databricks UI 测试作业:
- 转到 Azure Databricks UI 中的“工作流”并选择作业。
- 单击 “立即运行” 。
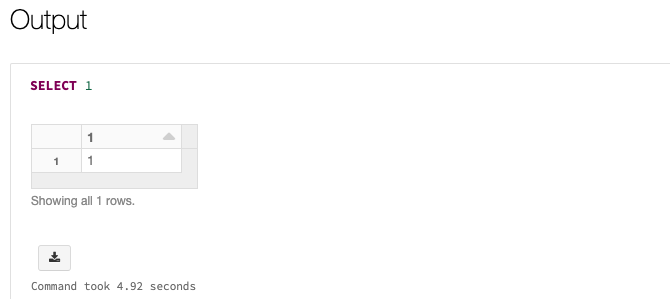
如果一切正常运行,你将看到作业的状态为“成功”。 可在 UI 中选择作业以验证输出:
了解详细信息
若要详细了解创建和运行作业,请参阅创建并运行 Azure Databricks 作业。