Databricks Git 文件夹和 Git 集成具有在以下部分中指定的限制。 有关常规信息,请参阅 Databricks 限制。
跳转到:
文件和存储库限制
Azure Databricks 不会对存储库的大小强制施加限制。 但是:
- 工作分支限制为 1 GB。
- 大于 10 MB 的文件无法在 Azure Databricks UI 中查看。
- 单个工作区文件有单独的大小限制。 有关更多详细信息,请阅读限制。
Databricks 建议在存储库中:
- 所有工作区资产和文件的总数不超过 20,000 个。
对于任何 Git 操作,内存使用量限制为 2 GB,磁盘写入限制为 4 GB。 由于限制是按操作,因此如果尝试克隆当前大小为 5 GB 的 Git 存储库,则会失败。 但如果在一个操作中克隆大小为 3 GB 的 Git 存储库,然后稍后向其添加 2 GB,则下一个拉取操作将成功。
如果存储库超出了这些限制,则可能会收到错误消息。 克隆存储库时也可能收到超时错误,但该操作可在后台完成。
若要使用大于大小限制的存储库,请尝试稀疏签出。
如果必须编写在群集关闭后不想保留的临时文件,将临时文件写入到 $TEMPDIR 可以避免超过分支大小限制,并且如果 CWD 位于工作区文件系统中,则产生的性能会优于写入当前工作目录 (CWD)。 有关详细信息,请参阅应在 Azure Databricks 上的什么位置编写临时文件?。
每个工作区的最大 Git 文件夹数
每个工作区最多可以有 2,000 个 Git 文件夹。 如果需要更多文件夹,请联系 Databricks 支持部门。
如何在工作区中恢复从 Git 文件夹删除的文件
对 Git 文件夹执行的工作区操作因文件可恢复性而异。 某些操作允许通过回收站文件夹进行恢复,而另一些操作则不允许。 以前提交并推送到远程分支的文件可以使用远程 Git 存储库的 Git 提交历史记录进行还原。 下表概述了每个操作的行为和可恢复性:
| 操作 | 文件是否可恢复? |
|---|---|
| 使用工作区浏览器删除文件 | 是,来自回收站文件夹 |
| 放弃包含 Git 文件夹对话框的新文件 | 是,来自回收站文件夹 |
| 放弃包含 Git 文件夹对话框的修改文件 | 否,文件已消失 |
reset(硬)用于未提交的文件修改 |
否,文件修改已消失 |
reset(硬)用于未提交的新创建的文件 |
否,文件修改已消失 |
| 使用 Git 文件夹对话框切换分支 | 是,来自远程 Git 存储库 |
| Git 文件夹对话框中的其他 Git 操作(提交和推送等) | 是,来自远程 Git 存储库 |
从 Repos API 更新 /repos/id 的 PATCH 操作 |
是,来自远程 Git 存储库 |
如果这些文件之前已提交并推送到远程存储库,则可以使用 Git 命令行(或其他 Git 工具),从远程分支历史记录中恢复通过 Git 操作从工作区 UI 中的 Git 文件夹删除的文件。 工作区操作因文件可恢复性而异。 某些操作允许通过回收站进行恢复,而另一些操作则不允许。 以前提交并推送到远程分支的文件可以通过 Git 提交历史记录进行还原。 下表概述了每个操作的行为和可恢复性:
单存储库支持
Databricks 建议不要创建由 monorepo 支持的 Git 文件夹,其中 monorepo 是大型、单一组织的 Git 存储库,在许多项目中有数千个文件。
Git 文件夹中支持的资产类型
Git 文件夹仅支持某些 Azure Databricks 资产类型。 支持的资产类型可以序列化、受版本控制并推送到支持 Git 存储库。
目前,支持的资产类型包括:
| 资产类型 | 详细信息 |
|---|---|
| 文件 | 文件是序列化数据,可以包含从库、二进制文件、代码到图像的任何内容。 有关详细信息,请参阅什么是工作区文件? |
| 笔记本 | 笔记本专指 Databricks 支持的笔记本文件格式。 笔记本未序列化,因此它们被视为独立于文件的 Azure Databricks 资产类型。 Git 文件夹通过文件扩展名(例如 .ipynb)或文件扩展名与文件内容中特殊标记的组合(例如 .py 源文件开头的 # Databricks notebook source 注释)来确定笔记本。 |
| 文件夹 | 文件夹是一个特定于 Azure Databricks 的结构,它表示有关 Git 中文件逻辑分组的序列化信息。 与预期一样,在查看 Azure Databricks Git 文件夹或使用 Azure Databricks CLI 访问该文件夹时,用户会将其当作“文件夹”。 |
Git 文件夹中当前不支持的 Azure Databricks 资产类型包括以下各项:
- DBSQL 查询
- 警报
- 仪表板(包括旧仪表板)
- 试验
- Genie spaces
在 Git 中使用资产时,请观察文件命名的以下限制:
- 即使文件扩展名不同,文件夹也不能包含与同一 Git 存储库中另一个笔记本、文件或文件夹同名的笔记本。 (对于源格式的笔记本,针对 Python 的扩展名为
.py,针对 Scala 的扩展名为.scala、针对 SQL 的扩展名为.sql,针对 R 的扩展名为.r。对于 IPYNB 格式的笔记本,扩展名为.ipynb。)例如,不能在同一 Git 文件夹中使用名为test1.py的源格式笔记本和名为test1的 IPYNB 笔记本,因为源格式的 Python 笔记本文件 (test1.py) 将序列化为test1,并且会发生冲突。 - 文件名不支持字符
/。 例如,在 Git 文件夹中不能有一个名为i/o.py的文件。
如果尝试对具有这些模式的名称的文件执行 Git 操作,将收到“提取 Git 状态时出错”消息。 如果意外收到此错误,请查看 Git 存储库中资产的文件名。 如果找到了名称具有这些冲突模式的文件,请重命名它们,然后重试操作。
注意
可以将现有不受支持的资产移动到 Git 文件夹中,但无法将这些资产的更改提交回存储库。 无法在 Git 文件夹中创建新的不受支持的资产。
笔记本格式
| 笔记本源格式 | 详细信息 |
|---|---|
| source | 可以是带有表示代码语言的标准文件后缀的任何代码文件,例如 .py、.scala、.r 和 .sql。 “source”笔记本被视为文本文件,在提交回 Git 存储库时不会包含任何关联的输出。 |
| IPYNB (Jupyter) | IPYNB 文件以 .ipynb 结尾,如果进行了配置,它可将 Databricks Git 文件夹中的输出(如可视化效果)推送到后端 Git 存储库。 IPYNB 笔记本可以包含 Databricks 笔记本支持的任何语言的代码(即使 py 是 .ipynb 的一部分)。 |
Databricks 会使用两种类型的高级、Databricks 特定的笔记本格式:source 和 IPYNB (Jupyter)。 当用户以 source 格式提交笔记本时,Azure Databricks 平台会提交一个带有语言后缀(例如,.py、.sql、.scala 或 .r)的平面文件。 source 格式的笔记本仅包含源代码,不包含输出,如表显示和可视化效果,这些输出是运行笔记本的结果。
但是,IPYNB (Jupyter) 格式具有与之关联的输出,在推送生成这些工件的 .ipynb 笔记本时,它们会自动推送到支持 Git 文件夹的 Git 存储库。 如果想将输出与代码一起提交,请使用 IPYNB 笔记本格式,并设置配置以允许用户提交任何生成的输出。 因此,对于通过 Git 文件夹推送到远程 Git 存储库的笔记本,IPYNB 还支持更好的查看体验。
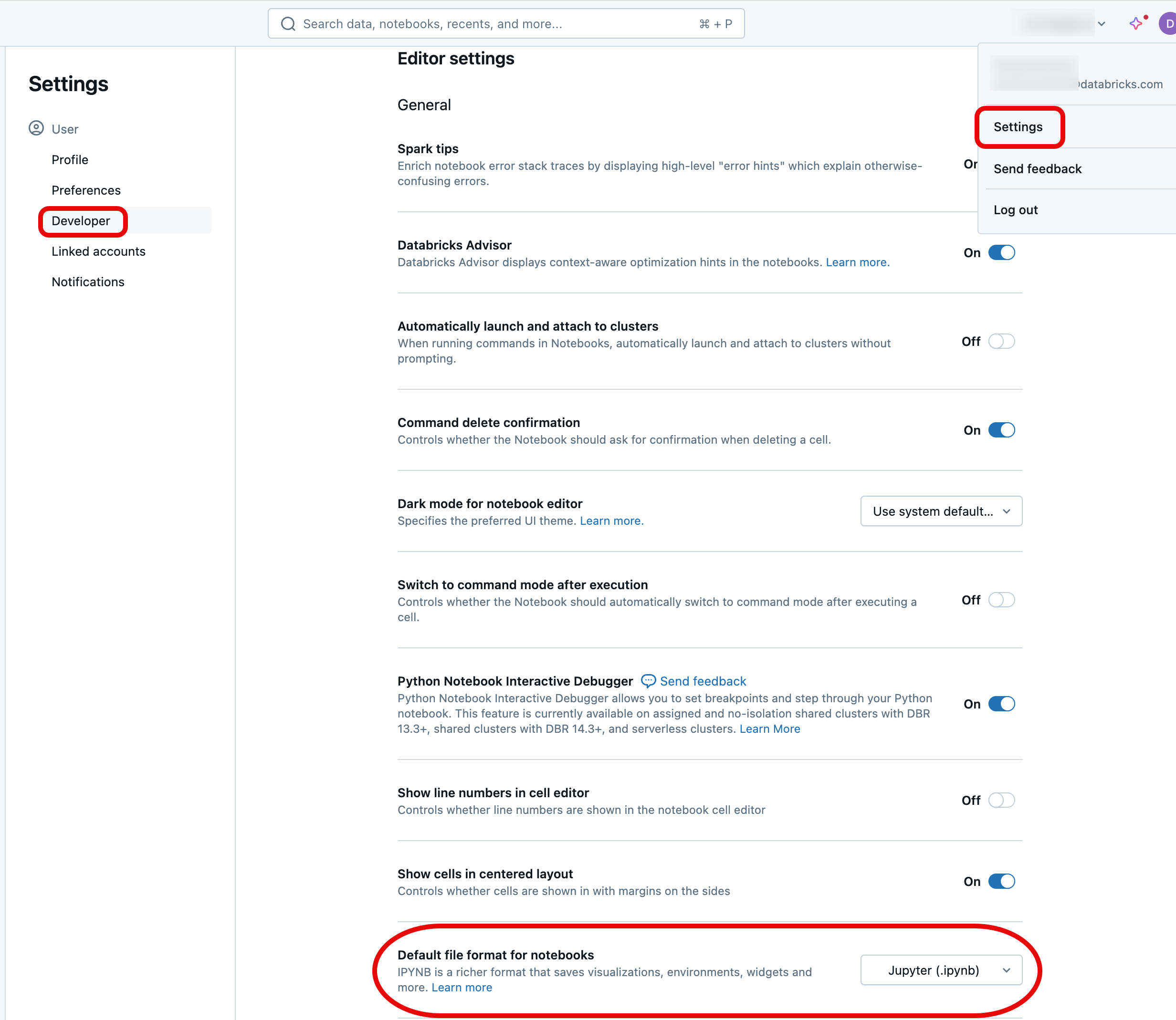
在 Databricks 上创建新笔记本时,IPYNB 笔记本是默认格式。 若要将默认格式更改为 Databricks 源格式,请登录到 Azure Databricks 工作区,单击页面右上角的配置文件,然后单击“设置”并导航到“开发人员”。 在“编辑器设置”标题下更改笔记本格式的默认设置。
如果希望在运行笔记本后将输出推送回存储库,请使用 IPYNB (Jupyter) 笔记本。 如果你只想运行笔记本并在 Git 中管理它,请使用 source 格式,例如 .py。
有关支持的笔记本格式的更多详细信息,请参阅导出和导入 Databricks 笔记本。
注意
什么是“输出”?
输出是在 Databricks 平台上运行笔记本的结果,包括表格显示和可视化效果。
除了文件扩展名之外,还可以如何判断笔记本使用的是什么格式?
在 Databricks 管理的笔记本顶部,通常有一个单行注释来指示格式。 例如,对于 .py“source”笔记本,你将看到类似于这样的行:
# Databricks notebook source
对于 .ipynb 文件,文件后缀用于指示它是“ipynb”笔记本格式。
Databricks Git 文件夹中的 IPYNB 笔记本
Git 文件夹中提供了对 Jupyter 笔记本(.ipynb 文件)的支持。 可以使用 .ipynb 笔记本来克隆存储库,在 Azure Databricks 中工作,然后将其作为 .ipynb 笔记本提交和推送。 笔记本仪表板之类的元数据将被保留。 管理员可以对是否可以提交输出进行控制。
允许提交 .ipynb 笔记本输出
默认情况下,Git 文件夹的管理员设置不允许提交 .ipynb 笔记本输出。 工作区管理员可以更改此设置:
转到“工作区设置”>“开发”。
在“Repos”>“允许 Repos 导出 IPYNB 输出”下,选择“允许: IPYNB 输出可以关闭”。

重要
当包含输出时,可视化效果和仪表板配置将保留为 .ipynb 文件格式。
控制 IPYNB 笔记本输出工件提交
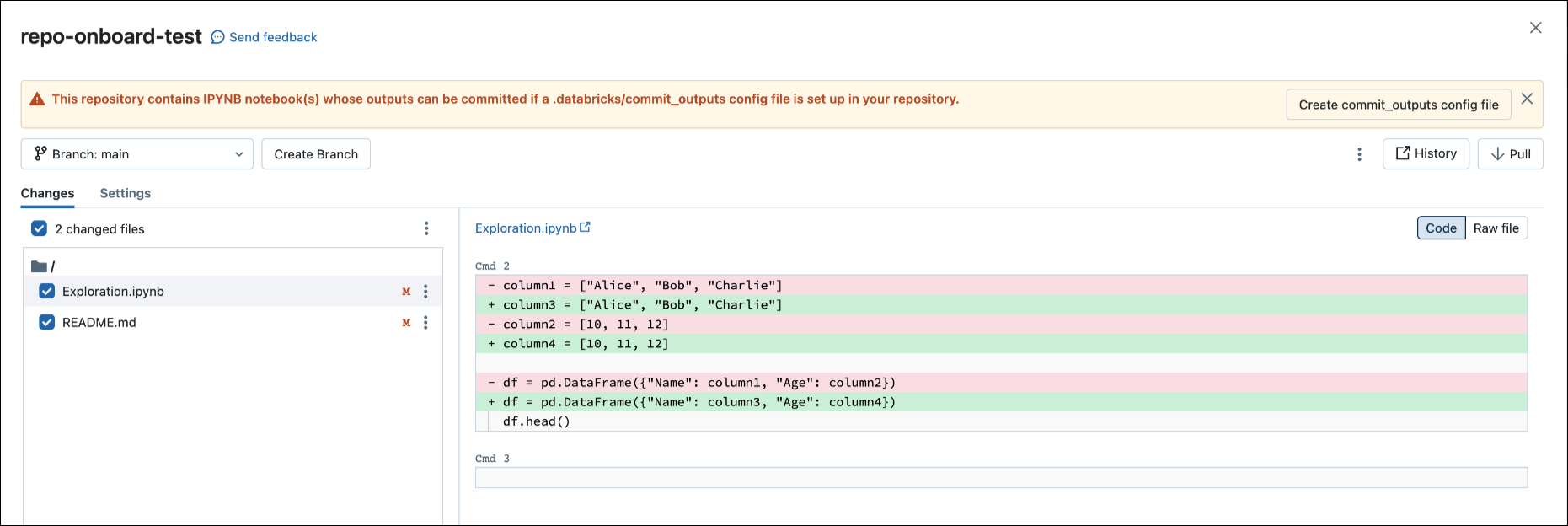
提交 .ipynb 文件时,Databricks 会创建配置文件来用于控制提交输出的方式:.databricks/commit_outputs。
如果存储库中有
.ipynb笔记本文件,但没有配置文件,请打开 Git 状态模式。在通知对话框中,单击“创建 commit_outputs 文件”。
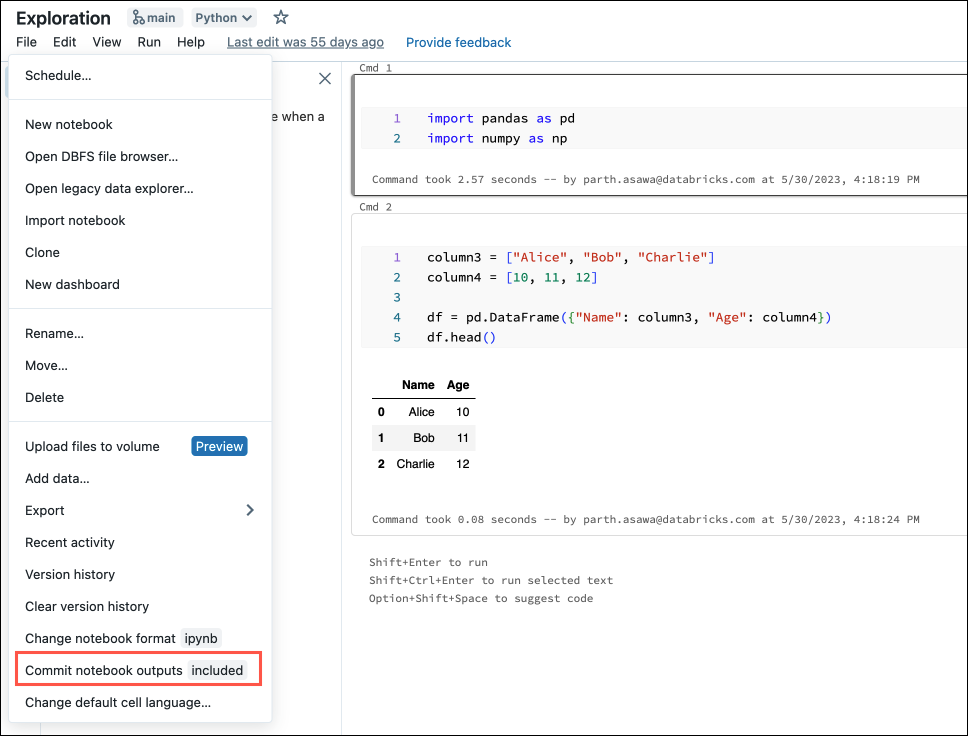
还可以从“文件”菜单生成配置文件。 “文件”菜单具有相关控件,可用于自动更新配置文件,以指定是包含还是排除特定笔记本的输出。
在“文件”菜单中,选择“提交笔记本输出”。
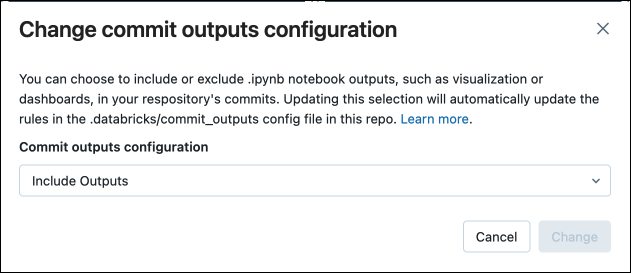
在对话框中,确认提交笔记本输出的选择。
将源笔记本转换为 IPYNB
可以通过 Azure Databricks UI 将 Git 文件夹中的现有源笔记本转换为 IPYNB 笔记本。
在工作区中打开一个源笔记本。
从工作区菜单中选择“文件”,然后选择“更改笔记本格式 [source]”。 如果笔记本已采用 IPYNB 格式,则“[source]”在菜单元素中将是“[ipynb]”。
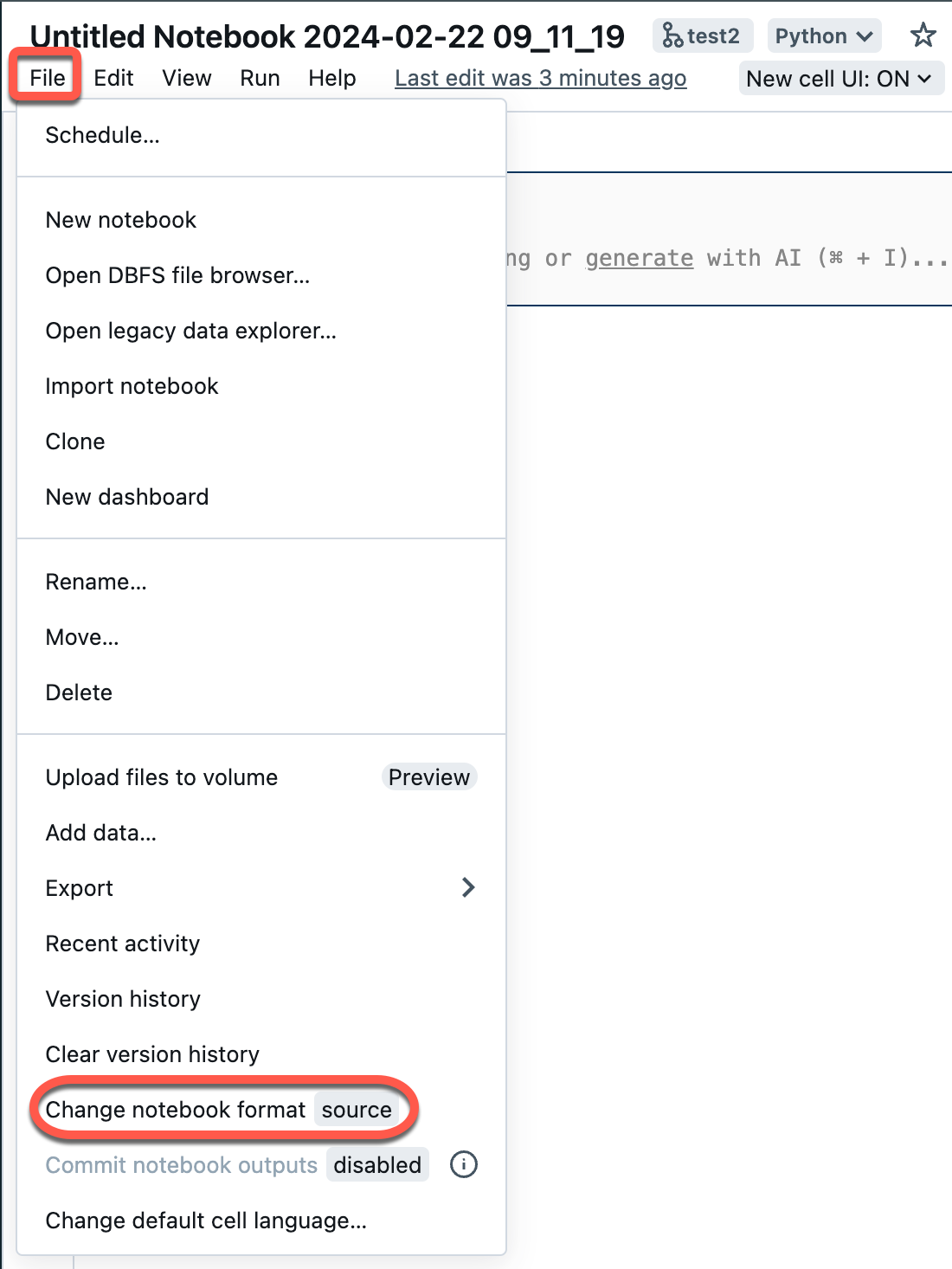
在模式对话框中,选择“Jupyter notebook 格式 (.ipynb)”,然后单击“更改”。
也可执行以下操作:
- 创建新的
.ipynb笔记本。 - 将差异视为“代码差异”(单元格中的代码更改)或“原始差异”(表示为 JSON 语法的代码更改,包括元数据之类的笔记本输出)。
有关 Azure Databricks 支持的笔记本类型的详细信息,请参阅导出和导入 Databricks 笔记本。
常见问题解答:Git 文件夹配置
Azure Databricks 存储库内容存储在何处?
存储库的内容暂时克隆到控制平面中的磁盘上。 Azure Databricks 笔记本文件存储在控制平面数据库中,与主工作区中的笔记本一样。 非笔记本文件最多在磁盘上存储 30 天。
Git 文件夹是否支持本地或自承载 Git 服务器?
如果可以通过 Internet 访问服务器,Databricks Git 文件夹将支持 GitHub Enterprise、Bitbucket Server、Azure DevOps Server 和 GitLab 自承载集成。 有关将 Git 文件夹与本地 Git 服务器集成的详细信息,请阅读 Git 文件夹的 Git 代理服务器。
若要与 Bitbucket Server、GitHub Enterprise Server 或无法访问 Internet 的 GitLab 自托管订阅实例集成,请与 Azure Databricks 帐户团队联系。
Git 文件夹支持哪些 Databricks 资产类型?
有关受支持的资产类型的详细信息,请阅读 Git 文件夹中支持的资产类型。
Git 文件夹是否支持 .gitignore 文件?
是的。 如果将某个文件添加到存储库,并且不希望 Git 跟踪该文件,请创建一个 .gitignore 文件或使用从远程存储库克隆的文件,并添加文件名(包括文件扩展名)。
.gitignore 仅适用于 Git 未跟踪的文件。 如果将 Git 已跟踪的文件添加到 .gitignore 文件,则该文件仍将由 Git 跟踪。
是否可以创建不是用户文件夹的顶级文件夹?
是的,管理员可以创建单一深度的顶级文件夹。 Git 文件夹不支持其他文件夹级别。
Git 文件夹是否支持 Git 子模块?
否。 可以克隆包含 Git 子模块的存储库,但不会克隆子模块。
Azure 数据工厂 (ADF) 是否支持 Git 文件夹?
是的。
源管理
为什么在拉取或签出其他分支时笔记本仪表板会消失?
这目前是一个限制,因为 Azure Databricks 笔记本源文件不存储笔记本仪表板信息。
如需在 Git 存储库中保留仪表板,请将笔记本格式更改为 .ipynb(Jupyter 笔记本格式)。 默认情况下,.ipynb 支持仪表板和可视化定义。 如果要保留图形数据(数据点),则必须提交包含输出的笔记本。
若要了解如何提交 .ipynb 笔记本输出,请参阅允许提交 .ipynb 笔记本输出。
Git 文件夹是否支持分支合并?
是的。 也可以创建拉取请求并通过 Git 提供程序进行合并。
能否从 Azure Databricks 存储库中删除分支?
否。 若要删除分支,必须在 Git 提供程序中工作。
如果在群集上安装了一个库,而存储库内的文件夹中包含一个同名的库,将导入哪个库?
将导入存储库中的库。 有关 Python 中的库优先级的详细信息,请参阅 Python 库优先级。
是否可以在不依赖外部业务流程工具的情况下,在运行作业之前从 Git 中拉取最新版本的存储库?
不是。 通常,可以将此操作集成为 Git 服务器上的预提交,可在每次推送到分支(主/生产)时都更新生产存储库。
是否可以导出存储库?
可以导出笔记本、文件夹或整个存储库。 无法导出非笔记本文件。 如果导出整个存储库,将不包括非笔记本文件。 若要导出,请使用 Databricks CLI 中的 workspace export 命令或使用工作区 API。
安全性、身份验证和令牌
Microsoft Entra ID 的条件访问策略 (CAP) 出现问题
尝试克隆存储库时,可能会在以下情况下收到“拒绝访问”的错误消息:
- Azure Databricks 配置为将 Azure DevOps 与 Microsoft Entra ID 身份验证配合使用。
- 你已在 Azure DevOps 中启用条件访问策略且启用了 Microsoft Entra ID 条件访问策略。
若要解决此问题,请为 Azure Databricks IP 地址或用户的条件访问策略 (CAP) 添加排除项。
有关详细信息,请参阅条件访问策略。
包含 Azure AD 令牌的允许列表
如果使用 Azure Active Directory (AAD) 向 Azure DevOps 进行身份验证,则默认允许列表将 Git URL 限制为以下内容:
dev.azure.comvisualstudio.com
有关详细信息,请参阅允许列表限制使用远程存储库。
Azure Databricks Git 文件夹的内容是否加密?
Azure Databricks Git 文件夹的内容将由 Azure Databricks 使用默认密钥进行加密。 除非加密 Git 凭据,否则不支持使用客户管理的密钥进行加密。
GitHub 令牌在 Azure Databricks 中的存储方式和位置是? 谁有权从 Azure Databricks 访问?
- 身份验证令牌存储在 Azure Databricks 控制平面中,Azure Databricks 员工只能通过经审核的临时凭据获取访问权限。
- Azure Databricks 记录这些令牌的创建和删除操作,但不记录其使用情况。 Azure Databricks 会通过日志记录跟踪 Git 操作,这些日志可用于审核 Azure Databricks 应用程序的令牌使用情况。
- GitHub 企业审核令牌使用情况。 其他 Git 服务也可能进行 Git 服务器审核。
Git 文件夹是否支持提交 GPG 签名?
否。
Git 文件夹是否支持 SSH?
否,仅 HTTPS。
将 Azure Databricks 连接到不同租户中的 Azure DevOps 存储库时出错
尝试在单独的租户中连接到 DevOps 时,可能会收到消息 Unable to parse credentials from Azure Active Directory account。 如果 Azure DevOps 项目与 Azure Databricks 位于不同的 Microsoft Entra ID 租户中,则需要使用 Azure DevOps 中的访问令牌。 请参阅使用 DevOps 令牌连接到 Azure DevOps。
CI/CD 和 MLOps
传入更改清除笔记本状态
更改笔记本源代码的 Git 操作会导致笔记本状态丢失,包括单元格输出、注释、版本历史记录和小组件。 例如,git pull 可以更改笔记本的源代码。 在这种情况下,Databricks Git 文件夹必须覆盖现有笔记本才能导入更改。 git commit 和 push 或创建新分支不会影响笔记本源代码,因此在这些操作中会保留笔记本状态。
重要
MLflow 试验不适用于使用 DBR 14.x 或更低版本的 Git 文件夹。
是否可以在存储库中创建 MLflow 试验?
有两种类型的 MLflow 试验:工作区和笔记本。 有关两种类型的 MLflow 试验的详细信息,请参阅使用 MLflow 试验组织训练运行。
在 Git 文件夹中,可以为任一类型的 MLflow 试验调用 mlflow.set_experiment("/path/to/experiment") 并将运行记录到其中,但该试验和关联的运行不会被签入源代码管理中。
工作区 MLflow 试验
你无法在 Databricks Git 文件夹(Git 文件夹)中创建工作区 MLflow 试验。 如果多个用户使用单独的 Git 文件夹协作处理同一 ML 代码,则日志 MLflow 将运行到在常规工作区文件夹中创建的 MLflow 试验。
笔记本 MLflow 试验
可以在 Databricks Git 文件夹中创建笔记本试验。 如果将笔记本作为 .ipynb 文件签入源代码管理,可以将 MLflow 运行记录到自动创建的和关联的 MLflow 试验。 有关更多详细信息,请参阅创建笔记本试验。
防止 MLflow 试验中的数据丢失
使用源代码在远程存储库中的 Databricks 作业创建的笔记本 MLflow 试验存储在临时存储位置。 这些试验最初会在工作流执行后保留,但之后在计划内的临时存储内文件移除期间,它们将面临被删除的风险。 Databricks 建议将工作区 MLflow 试验与作业和远程 Git 源一起使用。
警告
切换到不包含笔记本的分支时,可能会丢失关联的 MLflow 试验数据。 如果在 30 天内未访问前一分支,则此丢失将成为永久丢失。
若要在 30 天到期前恢复缺失的试验数据,请将笔记本重命名为原始名称,打开笔记本,单击右侧窗格中的“试验”图标(这也会有效地调用 mlflow.get_experiment_by_name() API),你将能看到恢复的试验和运行。 30 天后,将清除任何无主 MLflow 试验,以满足 GDPR 合规性策略。
为防止这种情况,Databricks 建议完全避免重命名存储库中的笔记本,或者在重命名笔记本后立即单击右侧窗格中的“试验”图标。
在 Git 操作进行期间,如果笔记本作业在工作区中运行,会发生什么情况?
在 Git 操作进行期间的任何时候,存储库中的一些笔记本可能已更新,而其他笔记本未更新。 这可能会导致不可预知的行为。
例如,假设 notebook A 使用 %run 命令调用 notebook Z。 如果在 Git 操作期间运行的作业启动最新版本的 notebook A,但 notebook Z 尚未更新,则笔记本 A 中的 %run 命令可能会启动较旧版本的 notebook Z。
在 Git 操作期间,笔记本状态不可预知,作业可能会失败,或者从不同的提交运行 notebook A 和 notebook Z。
为了避免这种情况,请改用基于 Git 的作业(其中源是 Git 提供程序,而不是工作区路径)。 有关更多详细信息,请参阅将 Git 与作业配合使用。
资源
有关 Databricks 工作区文件的详细信息,请参阅什么是工作区文件?。