了解在 CI/CD 工作流中使用 Databricks Git 文件夹的技术。 通过在工作区中配置 Databricks Git 文件夹,可以对 Git 存储库中的项目文件使用源代码管理,并且可以将它们集成到数据工程管道中。
下图概述了这些技术和工作流。
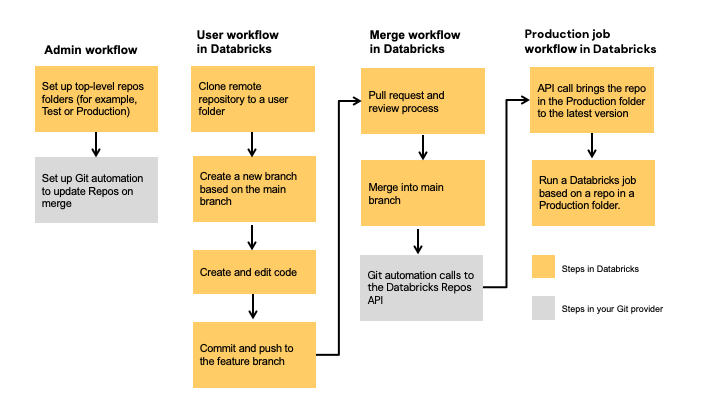
有关 Azure Databricks 的 CI/CD 的概述,请参阅 Azure Databricks 上的 CI/CD 是什么?。
开发流
Databricks Git 文件夹具有用户级文件夹。 用户级文件夹是在用户第一次克隆远程存储库时自动创建的。 可以将用户文件夹中的 Databricks Git 文件夹视为“本地签出”,它们与每个用户存在一对一的关系,用户可在其中更改其代码。
在 Databricks Git 文件夹内的用户文件夹中克隆你的远程存储库。 最佳做法是为工作创建一个新的功能分支,或选择一个先前创建的分支,而不是直接将更改提交并推送到主分支。 可以在该分支中进行更改,并提交和推送更改。 准备好合并代码后,可以在 Git 文件夹 UI 中执行此操作。
要求
此工作流要求你已设置 Git 集成。
注意
Databricks 建议每个开发人员在其自己的功能分支上工作。 有关如何解决合并冲突的信息,请参阅解决合并冲突。
Git 文件夹中的协作
在以下工作流中,使用一个名为 feature-b 的分支,该分支基于主分支。
- 将现有 Git 存储库克隆到 Databricks 工作区。
- 使用 Git 文件夹 UI 从主分支创建功能分支。 为简单起见,此示例使用了单个功能分支
feature-b。 可以创建并使用多个功能分支来完成工作。 - 对存储库中的 Azure Databricks 笔记本和其他文件进行修改。
- 提交更改并将其推送到 Git 提供程序。
- 参与者现在可将 Git 存储库克隆到其自己的用户文件夹中。
- 某位同事在新分支上工作,并对 Git 文件夹中的笔记本和其他文件进行更改。
- 参与者提交更改并将其推送到 Git 提供程序。
- 若要合并来自其他分支的更改或在 Databricks 中为 feature-b 分支变基,请在 Git 文件夹 UI 中使用以下工作流之一:
- 准备好将作业合并到远程存储库和
main分支时,请使用 Git 文件夹 UI 合并来自 feature-b 的更改。 如果愿意,可以改为直接将更改合并到支持 Git 文件夹的 Git 存储库。
生产作业工作流
Databricks Git 文件夹提供两个用于运行生产作业的选项:
- 选项 1:在作业定义中提供远程 Git 引用。 例如,在 Git 存储库的
main分支中运行特定笔记本。 - 选项 2:设置生产 Git 存储库并调用 Repos API 以编程方式更新该存储库。 针对克隆此远程存储库的 Databricks Git 文件夹运行作业。 Repos API 调用应该是作业中的第一个任务。
选项 1:使用远程存储库中的笔记本运行作业
通过使用远程 Git 存储库中的笔记本运行 Azure Databricks 作业,来简化作业定义过程并保留单一事实源。 此 Git 引用可以是 Git 提交、标记或分支,由你在作业定义中提供。
这有助于防止对生产作业进行意外更改,例如,当用户在生产存储库中进行本地编辑或切换分支时。 这样还可以自动完成 CD 步骤,因为你不需要在 Databricks 中创建单独的生产 Git 文件夹、管理其权限并使其保持更新状态。
请参阅将 Git 与作业配合使用。
选项 2:设置生产 Git 文件夹和 Git 自动化
此选项设置生产 Git 文件夹和自动化,以便在合并时更新 Git 文件夹。
步骤 1:设置顶级文件夹
管理员创建非用户顶级文件夹。 对于这些顶级文件夹,最常见的用例是创建开发、过渡和生产文件夹,其中包含用于开发、过渡和生产的适当版本或分支的 Databricks Git 文件夹。 例如,如果公司将 main 分支用于生产,则“生产”Git 文件夹必须有 main 分支在其中签出。
通常,工作区中的所有非管理员用户对这些顶级文件夹的访问权限都是只读的。 对于此类顶级文件夹,我们建议仅为服务主体提供“可编辑”和“可管理”权限,以避免工作区用户对生产代码进行意外的编辑。
步骤 2:使用 Git 文件夹 API 设置 Databricks Git 文件夹的自动更新
为了确保 Databricks 中的 Git 文件夹始终为最新版本,可以设置 Git 自动化以调用 Repos API。 在 Git 提供程序中设置自动化,这样可以在每次成功将 PR 合并到主分支后,在相应的 Git 文件夹上调用 Repos API 终结点,以将其更新到最新版本。
例如,在 GitHub 上这可以通过 GitHub Actions 来实现。 有关详细信息,请参阅 Repos API。
要从 Databricks 笔记本单元格中调用任何 Databricks REST API,请先安装 Databricks SDK 和 %pip install databricks-sdk --upgrade(针对最新的 Databricks REST API),然后从 databricks.sdk.core 中导入 ApiClient。
注意
如果 %pip install databricks-sdk --upgrade 返回错误“找不到包”,则之前该 databricks-sdk 包尚未安装。 在不使用 --upgrade 标志的情况下重新运行命令:%pip install databricks-sdk。
还可以从笔记本运行 Databricks SDK API,以检索工作区的服务主体。 以下是使用 Python 和用于 Python 的 Databricks SDK 的示例。
还可以使用 curl 或 Terraform 之类的工具。 不能使用 Azure Databricks 用户界面。
要详细了解 Azure Databricks 上的服务主体,请参阅《管理服务主体》。 有关服务主体和 CI/CD 的信息,请参阅 CI/CD 的服务主体。 有关从笔记本中使用 Databricks SDK 的更多详细信息,请阅读《从 Databricks 笔记本中使用适用于 Python 的 Databricks SDK》。
将服务主体与 Databricks Git 文件夹配合使用
若要使用服务主体来运行上述工作流,请执行以下操作:
- 创建 Azure Databricks 的服务主体。
- 添加 git 凭证:使用 Git 提供程序 PAT 作为服务主体。
若要设置服务主体,然后添加 Git 提供程序凭据,请执行以下操作:
- 创建服务主体。 请参阅使用服务主体运行作业。
- 为服务主体创建 Microsoft Entra ID 令牌。
- 创建服务主体后,使用服务主体 API 将其添加到 Azure Databricks 工作区。
- 使用 Microsoft Entra ID 令牌和 Git 凭据 API 将 Git 提供程序凭据添加到工作区。
Terraform 集成
还可以使用 Terraform 和 databricks_repo 在全自动设置中管理 Databricks Git 文件夹:
resource "databricks_repo" "this" {
url = "https://github.com/user/demo.git"
}
要使用 Terraform 将 Git 凭据添加到服务主体,请添加以下配置:
provider "databricks" {
# Configuration options
}
provider "databricks" {
alias = "sp"
host = "https://....cloud.databricks.com"
token = databricks_obo_token.this.token_value
}
resource "databricks_service_principal" "sp" {
display_name = "service_principal_name_here"
}
resource "databricks_obo_token" "this" {
application_id = databricks_service_principal.sp.application_id
comment = "PAT on behalf of ${databricks_service_principal.sp.display_name}"
lifetime_seconds = 3600
}
resource "databricks_git_credential" "sp" {
provider = databricks.sp
depends_on = [databricks_obo_token.this]
git_username = "myuser"
git_provider = "azureDevOpsServices"
personal_access_token = "sometoken"
}
使用 Databricks Git 文件夹配置自动化 CI/CD 管道
下面是一个可以作为 GitHub Action 运行的简单自动化。
要求
- 已在 Databricks 工作区中创建 Git 文件夹,用于跟踪要合并到的基础分支。
- 你有一个 Python 包,用于创建要放入 DBFS 位置的项目。 代码必须符合以下条件:
- 更新与首选分支(例如
development)关联的存储库,以包含笔记本的最新版本。 - 生成任何项目并将其复制到库路径。
- 替换项目的上一个版本,以避免在作业中手动更新项目版本。
- 更新与首选分支(例如
创建自动 CI/CD 工作流
设置机密,使代码可以访问 Databricks 工作区。 将以下机密添加到 GitHub 存储库:
- DEPLOYMENT_TARGET_URL:将其设置为工作区 URL。 请勿包含
/?o子字符串。 - DEPLOYMENT_TARGET_TOKEN:将其设置为 Databricks 个人访问令牌 (PAT)。 可以按照 Azure Databricks 个人访问令牌身份验证中的说明生成 Databricks PAT。
- DEPLOYMENT_TARGET_URL:将其设置为工作区 URL。 请勿包含
导航到 Git 存储库的“操作”选项卡,然后单击“新建工作流”按钮。 在页面顶部,选择“自行设置工作流”并粘贴到以下脚本中:

# This is a basic automation workflow to help you get started with GitHub Actions. name: CI # Controls when the workflow will run on: # Triggers the workflow on push for main and dev branch push: paths-ignore: - .github branches: # Set your base branch name here - your-base-branch-name # A workflow run is made up of one or more jobs that can run sequentially or in parallel jobs: # This workflow contains a single job called "deploy" deploy: # The type of runner that the job will run on runs-on: ubuntu-latest environment: development env: DATABRICKS_HOST: ${{ secrets.DEPLOYMENT_TARGET_URL }} DATABRICKS_TOKEN: ${{ secrets.DEPLOYMENT_TARGET_TOKEN }} REPO_PATH: /Workspace/Users/someone@example.com/workspace-builder DBFS_LIB_PATH: dbfs:/path/to/libraries/ LATEST_WHEEL_NAME: latest_wheel_name.whl # Steps represent a sequence of tasks that will be executed as part of the job steps: # Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it - uses: actions/checkout@v3 - name: Setup Python uses: actions/setup-python@v3 with: # Version range or exact version of a Python version to use, using SemVer's version range syntax. python-version: 3.8 # Download the Databricks CLI. See https://github.com/databricks/setup-cli - uses: databricks/setup-cli@main - name: Install mods run: | pip install pytest setuptools wheel - name: Extract branch name shell: bash run: echo "##[set-output name=branch;]$(echo ${GITHUB_REF#refs/heads/})" id: extract_branch - name: Update Databricks Git folder run: | databricks repos update ${{env.REPO_PATH}} --branch "${{ steps.extract_branch.outputs.branch }}" - name: Build Wheel and send to Databricks DBFS workspace location run: | cd $GITHUB_WORKSPACE python setup.py bdist_wheel dbfs cp --overwrite ./dist/* ${{env.DBFS_LIB_PATH}} # there is only one wheel file; this line copies it with the original version number in file name and overwrites if that version of wheel exists; it does not affect the other files in the path dbfs cp --overwrite ./dist/* ${{env.DBFS_LIB_PATH}}${{env.LATEST_WHEEL_NAME}} # this line copies the wheel file and overwrites the latest version with it使用自己的环境变量值更新以下环境变量值:
- DBFS_LIB_PATH:要在此自动化中使用的 DBFS 中的库 (wheel) 的路径,以
dbfs:开头。 例如dbfs:/mnt/myproject/libraries。 - REPO_PATH:Databricks 工作区中要更新笔记本的 Git 文件夹的路径。
- LATEST_WHEEL_NAME:上次编译的 Python wheel 文件的名称 (
.whl)。 这用于避免在 Databricks 作业中手动更新 wheel 版本。 例如your_wheel-latest-py3-none-any.whl。
- DBFS_LIB_PATH:要在此自动化中使用的 DBFS 中的库 (wheel) 的路径,以
选择“提交更改…”,以 GitHub Actions 工作流的形式提交脚本。 合并此工作流的拉取请求后,转到 Git 存储库的“操作”选项卡,确认操作是否成功。