什么是 Databricks 功能服务?
Databricks Feature Serving 使 Databricks 平台中的数据可供部署在 Azure Databricks 外部的模型或应用程序使用。 功能服务终结点会自动缩放来适应实时流量,并为服务功能提供高可用性、低延迟的服务。 本页介绍如何设置和使用功能服务。
使用 Databricks 功能服务,你可以为检索增强生成 (RAG) 应用程序提供结构化数据,并提供其他应用程序所需的功能,例如在 Databricks 外部提供的模型或 Unity Catalog 中需要基于数据的特性的任何其他应用程序。
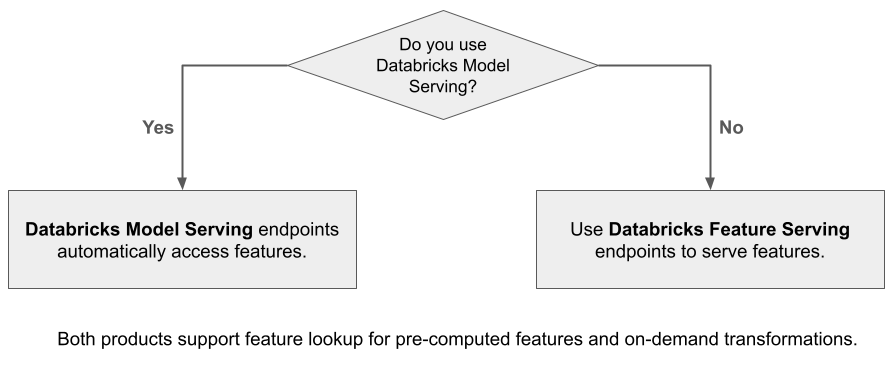
为何使用功能服务?
Databricks 功能服务提供了一个服务于预具体化和按需特性的单一界面。 还包括以下优势:
- 简单。 Databricks 可处理基础结构。 通过单个 API 调用,Databricks 可创建生产就绪的服务环境。
- 高可用性和可伸缩性。 功能服务终结点会自动纵向扩展和缩减以适应服务请求量。
- 安全性。 终结点部署在安全的网络边界中,并使用专用计算,在终结点被删除或缩放到零时就会终止。
要求
- Databricks Runtime 14.2 ML 或更高版本。
- 若要使用 Python API,功能服务需要
databricks-feature-engineering版本 0.1.2 或更高版本,该版本内置于 Databricks Runtime 14.2 ML 中。 对于早期 Databricks Runtime ML 版本,请使用%pip install databricks-feature-engineering>=0.1.2手动安装所需的版本。 如果使用 Databricks 笔记本,则必须通过在新单元格中运行以下命令来重启 Python 内核:dbutils.library.restartPython()。 - 若要使用 Databricks SDK,功能服务需要
databricks-sdk0.18.0 或更高版本。 若要手动安装所需的版本,请使用%pip install databricks-sdk>=0.18.0。 如果使用 Databricks 笔记本,则必须通过在新单元格中运行以下命令来重启 Python 内核:dbutils.library.restartPython()。
Databricks 功能服务提供了一个 UI 和多个编程选项,用于创建、更新、查询和删除终结点。 本文包括以下每个选项的说明:
- Databricks UI
- REST API
- Python API
- Databricks SDK
若要使用 REST API 或 MLflow 部署 SDK,必须具有 Databricks API 令牌。
重要
作为适用于生产场景的安全最佳做法,Databricks 建议在生产期间使用计算机到计算机 OAuth 令牌来进行身份验证。
对于测试和开发,Databricks 建议使用属于服务主体(而不是工作区用户)的个人访问令牌。 若要为服务主体创建令牌,请参阅管理服务主体的令牌。
功能服务的身份验证
有关身份验证的信息,请参阅对 Azure Databricks 资源的访问进行身份验证。
创建 FeatureSpec
FeatureSpec 是用户定义的一组功能和函数。 可以在一个 FeatureSpec 中合并功能和函数。 FeatureSpecs 由 Unity 目录储存和管理,并显示在目录资源管理器中。
在 FeatureSpec 中指定的表必须发布到第三方在线商店。 请参阅第三方在线存储。
必须使用 databricks-feature-engineering 包来创建 FeatureSpec。
from databricks.feature_engineering import (
FeatureFunction,
FeatureLookup,
FeatureEngineeringClient,
)
fe = FeatureEngineeringClient()
features = [
# Lookup column `average_yearly_spend` and `country` from a table in UC by the input `user_id`.
FeatureLookup(
table_name="main.default.customer_profile",
lookup_key="user_id",
feature_names=["average_yearly_spend", "country"]
),
# Calculate a new feature called `spending_gap` - the difference between `ytd_spend` and `average_yearly_spend`.
FeatureFunction(
udf_name="main.default.difference",
output_name="spending_gap",
# Bind the function parameter with input from other features or from request.
# The function calculates a - b.
input_bindings={"a": "ytd_spend", "b": "average_yearly_spend"},
),
]
# Create a `FeatureSpec` with the features defined above.
# The `FeatureSpec` can be accessed in Unity Catalog as a function.
fe.create_feature_spec(
name="main.default.customer_features",
features=features,
)
创建终结点
FeatureSpec 定义了终结点。 有关详细信息,请参阅 Python API 文档或 Databricks SDK 文档。
REST API
curl -X POST -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints \
-H 'Content-Type: application/json' \
-d '"name": "customer-features",
"config": {
"served_entities": [
{
"entity_name": "main.default.customer_features",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
]
}'
Databricks SDK - Python
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
workspace = WorkspaceClient()
# Create endpoint
workspace.serving_endpoints.create(
name="my-serving-endpoint",
config = EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
)
Python API
from databricks.feature_engineering.entities.feature_serving_endpoint import (
ServedEntity,
EndpointCoreConfig,
)
fe.create_feature_serving_endpoint(
name="customer-features",
config=EndpointCoreConfig(
served_entities=ServedEntity(
feature_spec_name="main.default.customer_features",
workload_size="Small",
scale_to_zero_enabled=True,
instance_profile_arn=None,
)
)
)
若要查看终结点,请单击 Databricks UI 左侧边栏中的“服务”。 当状态为“就绪”时,终结点可以响应查询。
获取终结点
可以使用 Databricks SDK 或 Python API 获取终结点的元数据和状态。
Databricks SDK - Python
endpoint = workspace.serving_endpoints.get(name="customer-features")
# print(endpoint)
Python API
endpoint = fe.get_feature_serving_endpoint(name="customer-features")
# print(endpoint)
查询终结点
可以使用 REST API、MLflow 部署 SDK 或服务 UI 查询终结点。
以下代码展示了如何在使用 MLflow 部署 SDK 时设置凭据并创建客户端。
# Set up credentials
export DATABRICKS_HOST=...
export DATABRICKS_TOKEN=...
# Set up the client
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
注意
作为安全最佳做法,在使用自动化工具、系统、脚本和应用进行身份验证时,Databricks 建议使用属于服务主体(而不是工作区用户)的个人访问令牌。 若要为服务主体创建令牌,请参阅管理服务主体的令牌。
使用 API 查询终结点
本部分包括使用 REST API 或 MLflow 部署 SDK 查询终结点的示例。
REST API
curl -X POST -u token:$DATABRICKS_API_TOKEN $ENDPOINT_INVOCATION_URL \
-H 'Content-Type: application/json' \
-d '{"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280}
]}'
MLflow 部署 SDK
重要
以下示例使用 MLflow 部署 SDK 中的 predict() API。 此 API 是实验性的,API 定义可能会发生变化。
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
response = client.predict(
endpoint="test-feature-endpoint",
inputs={
"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280},
]
},
)
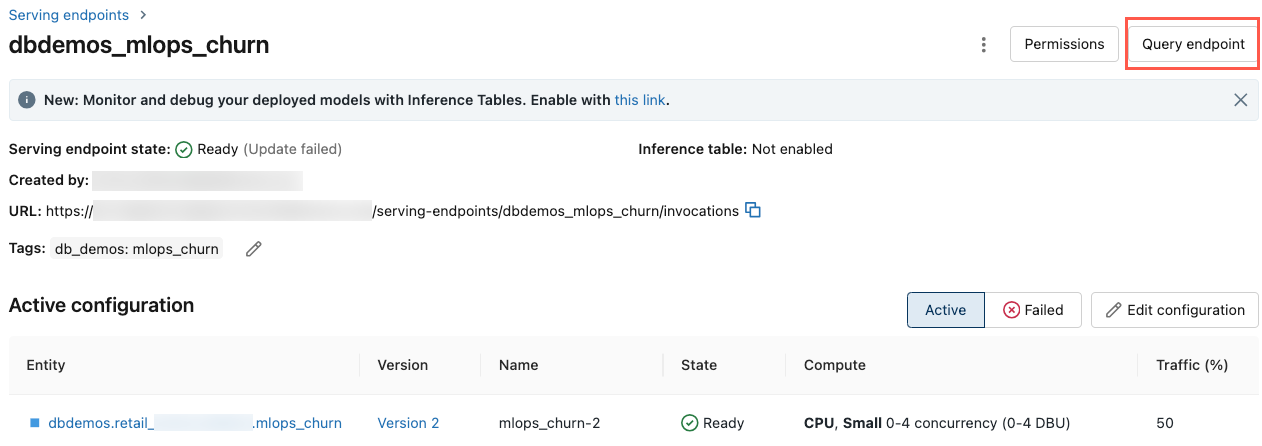
使用 UI 查询终结点
可以直接从服务 UI 查询服务终结点。 UI 包含可用于查询终结点的生成的代码示例。
在 Azure Databricks 工作区的左侧导航栏中,单击“服务”。
单击要查询的终结点。
在屏幕右上角,单击“查询终结点”。
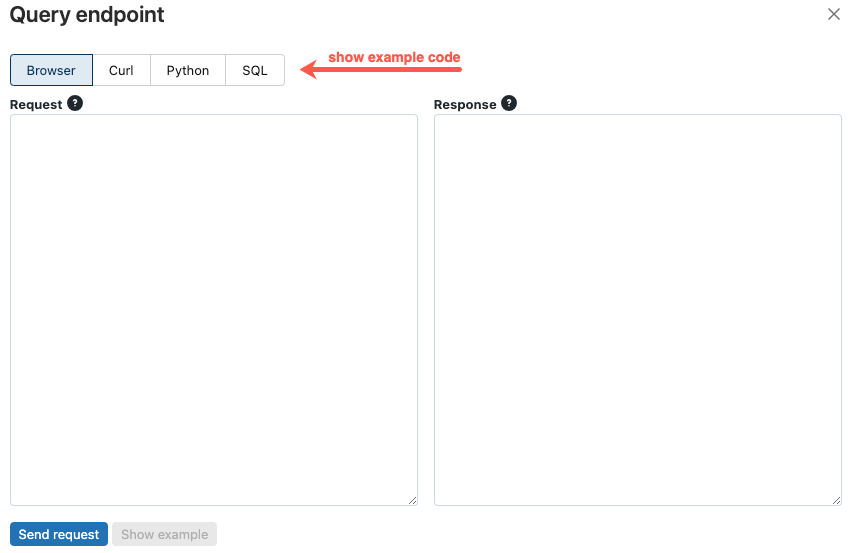
在“请求”框中,键入 JSON 格式的请求正文。
单击“发送请求”。
// Example of a request body.
{
"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280}
]
}
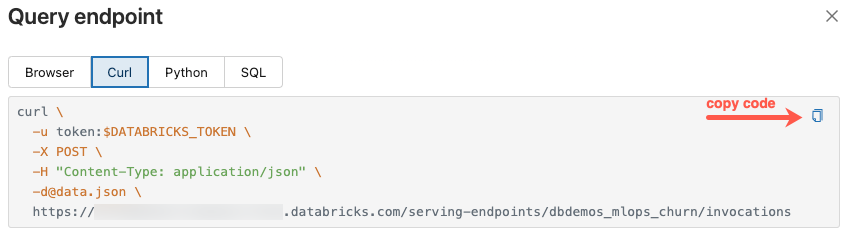
“查询终结点”对话框包含用 curl、Python 和 SQL 生成的示例代码。 单击选项卡查看并复制示例代码。
若要复制代码,请单击文本框右上角的复制图标。
更新终结点
可以使用 REST API、Databricks SDK 或服务 UI 更新终结点。
使用 API 更新终结点
REST API
curl -X PUT -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>/config \
-H 'Content-Type: application/json' \
-d '"served_entities": [
{
"name": "customer-features",
"entity_name": "main.default.customer_features_new",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
]'
Databricks SDK - Python
workspace.serving_endpoints.update_config(
name="my-serving-endpoint",
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
使用 UI 创建终结点
按照以下步骤使用服务 UI:
- 在 Azure Databricks 工作区的左侧导航栏中,单击“服务”。
- 在表中,单击要更新的终结点的名称。 会显示终结点屏幕。
- 在屏幕右上角,单击“编辑终结点”。
- 在编辑服务终结点对话框中,根据需要编辑终结点设置。
- 单击“更新”以保存更改。

删除终结点
警告
此操作不可逆。
可以使用 REST API、Databricks SDK 或服务 UI 删除终结点。
使用 API 删除终结点
REST API
curl -X DELETE -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>
Databricks SDK - Python
workspace.serving_endpoints.delete(name="customer-features")
Python API
fe.delete_feature_serving_endpoint(name="customer-features")
使用 UI 删除终结点
按照以下步骤使用服务 UI 删除终结点:
- 在 Azure Databricks 工作区的左侧导航栏中,单击“服务”。
- 在表中,单击要删除的终结点的名称。 会显示终结点屏幕。
- 在屏幕右上角单击串形菜单
 ,然后选择“删除”。
,然后选择“删除”。

示例笔记本
以下笔记本演示了如何使用 Databricks SDK 通过 Databricks 联机表创建功能服务终结点。