用于 Visual Studio Code 的 Databricks 扩展提供了 Visual Studio Code 中的其他功能,让你能够轻松地定义、部署和运行 Databricks 资产捆绑包,将 CI/CD 最佳做法应用于 Azure Databricks 作业、增量实时表管道和 MLOps Stacks。 请参阅什么是 Databricks 资产捆绑包?。
若要安装适用于 Visual Studio Code 的 Databricks 扩展,请参阅安装适用于 Visual Studio Code 的 Databricks 扩展。
项目中的 Databricks 资产捆绑包支持
适用于 Visual Studio Code 的 Databricks 扩展为 Databricks 资产捆绑包项目添加了以下功能:
- 通过 Visual Studio Code UI,轻松进行 Databricks 资产捆绑包的身份验证和配置,包括 AuthType 配置文件选择。 请参阅Visual Studio Code 的 Databricks 扩展的身份验证设置。
- Databricks 扩展面板中的“目标”选择器可在捆绑包目标环境之间快速切换。 请参阅更改目标部署工作区。
- 扩展面板中的“替代捆绑包中的作业群集”选项可启用简单的群集替代。
- “捆绑包资源浏览器”视图,可以使用 Visual Studio Code UI 浏览捆绑包资源,只需单击一下鼠标即可将本地 Databricks 资产捆绑包的资源部署到远程 Azure Databricks 工作区,然后直接从 Visual Studio Code 转到工作区中已部署的资源。 请参阅捆绑包资源浏览器。
- 捆绑包变量视图,让你能够使用 Visual Studio Code UI 浏览和编辑捆绑包变量。 请参阅捆绑包变量视图。
捆绑包资源浏览器
适用于 Visual Studio Code 的 Databricks 扩展中的捆绑包资源资源管理器视图使用项目捆绑包配置中的作业和管道定义来显示资源。 使用该视图还可以部署和运行资源,并在远程 Azure Databricks 工作区中导航到这些资源。 有关捆绑包配置资源的信息,请参阅资源。
例如,给定一个简单的作业定义:
resources:
jobs:
my-notebook-job:
name: "My Notebook Job"
tasks:
- task_key: notebook-task
existing_cluster_id: 1234-567890-abcde123
notebook_task:
notebook_path: notebooks/my-notebook.py
扩展中的捆绑包资源浏览器视图显示笔记本作业资源:
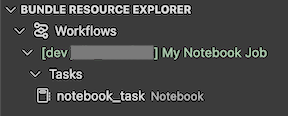
若要部署捆绑包,请单击云(部署捆绑包)图标。
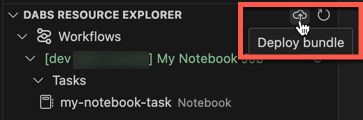
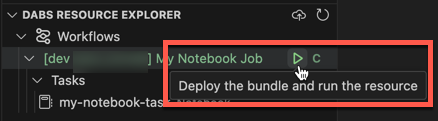
若要运行作业,请在“捆绑包资源浏览器”视图中,选择作业的名称,在本示例中为“我的笔记本作业”。 接下来,单击“播放”(部署捆绑包并运行资源)图标。
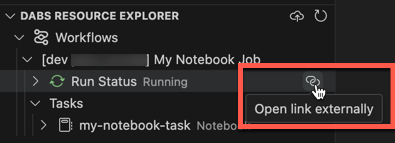
若要查看正在运行的作业,请在捆绑包资源浏览器视图中展开作业名称,单击“运行状态”,然后单击“链接”(外部打开链接)图标。
捆绑包变量视图
适用于 Visual Studio Code 的 Databricks 扩展中的捆绑包变量视图显示在捆绑包配置中定义的任何自定义变量和关联设置。 还可以使用“捆绑包变量视图”直接定义变量。 这些值替代在捆绑包配置文件中设置的值。 有关自定义变量的信息,请参阅自定义变量。
例如,扩展中的捆绑包变量视图将显示以下内容:

对于在此捆绑包配置中定义的变量 my_custom_var:
variables:
my_custom_var:
description: "Max workers"
default: "4"
resources:
jobs:
my_job:
name: my_job
tasks:
- task_key: notebook_task
job_cluster_key: job_cluster
notebook_task:
notebook_path: ../src/notebook.ipynb
job_clusters:
- job_cluster_key: job_cluster
new_cluster:
spark_version: 13.3.x-scala2.12
node_type_id: i3.xlarge
autoscale:
min_workers: 1
max_workers: ${var.my_custom_var}