增量实时表引入了多个新的 Python 代码构造,用于在管道中定义具体化视图和流式处理表。 Python 对开发管道的支持基于 PySpark 数据帧和结构化流式处理 API 的基础知识。
对于不熟悉数据帧的用户,Python 和 Databricks 建议使用 SQL 接口。 请参阅使用 SQL 开发管道代码。
有关增量实时表 Python 语法的完整参考,请参阅增量实时表 Python 语言参考。
用于管道开发的 Python 基础知识
创建增量实时表数据集的 Python 代码必须返回数据帧。
所有增量实时表 Python API 都在 dlt 模块中实现。 使用 Python 实现的 Delta Live Tables 管道代码必须显式导入 Python 笔记本和文件顶部的 dlt 模块。
增量实时表特定的 Python 代码与其他类型的 Python 代码不同,这一关键方式是:Python 管道代码不直接调用执行数据引入和转换以创建增量实时表数据集的函数。 取而代之的是,增量实时表会解释配置到管道的所有源代码文件中的 dlt 模块中的修饰器函数,并生成数据流图。
重要
要避免管道运行时出现意外行为,请不要在定义数据集的函数中包含可能具有副作用的代码。 要了解详细信息,请参阅Python 参考。
使用 Python 创建具体化视图或流式处理表
@dlt.table 修饰器告知增量实时表,根据函数返回的结果创建具体化视图或流式处理表。 批处理读取的结果会创建具体化视图,而流式读取的结果则创建流式处理表。
默认情况下,具体化视图和流式处理表名称是从函数名称推断而来。 以下代码示例显示创建具体化视图和流式处理表的基本语法:
注意
这两个函数引用 samples 目录中的同一个表,而且使用同一修饰器函数。 这些示例突出显示了具体化视图和流式处理表的基本语法的唯一区别是使用 spark.read 与 spark.readStream。
并非所有的数据源都支持流式读取。 某些数据源应始终使用流式处理语义进行处理。
import dlt
@dlt.table()
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dlt.table()
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
(可选)可使用 @dlt.table 修饰器中的 name 参数指定表名。 以下示例展示具体化视图和流式处理表的此模式:
import dlt
@dlt.table(name = "trips_mv")
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dlt.table(name = "trips_st")
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
从对象存储加载数据
增量实时表支持从 Azure Databricks 所支持的所有格式加载数据。 请参阅数据格式选项。
注意
这些示例使用自动装载到工作区中 /databricks-datasets 下的数据。 Databricks 建议使用卷路径或云 URI,以引用存储在云对象存储中的数据。 请参阅什么是 Unity Catalog 卷?。
在针对存储在云对象存储中的数据配置增量引入工作负荷时,Databricks 建议使用自动加载程序和流式处理表。 请参阅什么是自动加载程序?。
以下示例使用自动加载程序从 JSON 文件创建流式处理表:
import dlt
@dlt.table()
def ingestion_st():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
以下示例使用批处理语义读取 JSON 目录并创建具体化视图:
import dlt
@dlt.table()
def batch_mv():
return spark.read.format("json").load("/databricks-datasets/retail-org/sales_orders")
使用预期以验证数据
可使用预期以设置和强制执行数据质量约束。 请参阅使用 Delta Live Tables 管理数据质量。
以下代码使用 @dlt.expect_or_drop 定义名为 valid_data 的预期,该预期可删除数据引入过程中为 null 的记录:
import dlt
@dlt.table()
@dlt.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders_valid():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
查询管道中定义的具体化视图和流式处理表
使用 LIVE 架构查询管道中定义的其他具体化视图和流式处理表。
以下示例定义四种数据集:
- 名为
orders的流式处理表,可加载 JSON 数据。 - 名为
customers的具体化视图,可加载 CSV 数据。 - 名为
customer_orders的具体化视图,可连接orders和customers数据集的记录,将顺序时间戳强制转换为日期,以及选择customer_id、order_number、state和order_date字段。 - 名为
daily_orders_by_state的具体化视图,可聚合每种状态的每日订单数。
import dlt
from pyspark.sql.functions import col
@dlt.table()
@dlt.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
@dlt.table()
def customers():
return spark.read.format("csv").option("header", True).load("/databricks-datasets/retail-org/customers")
@dlt.table()
def customer_orders():
return (spark.read.table("LIVE.orders")
.join(spark.read.table("LIVE.customers"), "customer_id")
.select("customer_id",
"order_number",
"state",
col("order_datetime").cast("int").cast("timestamp").cast("date").alias("order_date"),
)
)
@dlt.table()
def daily_orders_by_state():
return (spark.read.table("LIVE.customer_orders")
.groupBy("state", "order_date")
.count().withColumnRenamed("count", "order_count")
)
在 for 循环中创建表
可使用 Python for 循环以编程方式创建多个表。 如果有多个数据源或目标数据集,这些数据源或目标数据集仅因几个参数而异,这就非常有用,减少了需要维护的总代码数量和代码冗余。
该 for 循环按串行顺序评估逻辑,但在为数据集完成规划后,管道会并行运行逻辑。
重要
使用此模式定义数据集时,确保传递给 for 循环的值列表始终是累加的。 如果以前在管道中定义的数据集从将来的管道运行中省略,该数据集会自动从目标架构中删除。
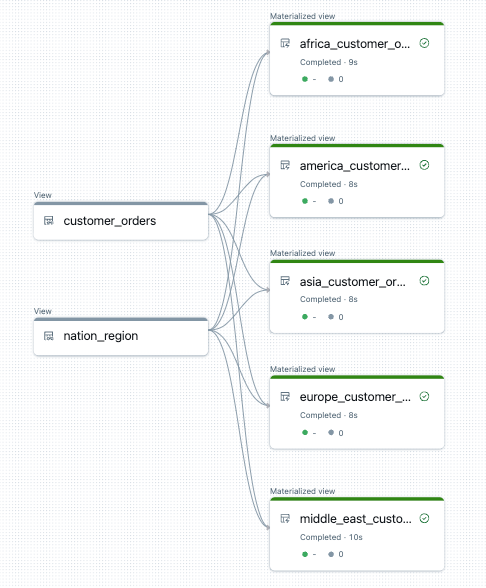
以下示例会创建五个表,用于按区域筛选客户订单。 在这里,区域名称用于设置目标具体化视图的名称和筛选源数据。 临时视图用于定义构造最终具体化视图中使用的源表的连接。
import dlt
from pyspark.sql.functions import collect_list, col
@dlt.view()
def customer_orders():
orders = spark.read.table("samples.tpch.orders")
customer = spark.read.table("samples.tpch.customer")
return (orders.join(customer, orders.o_custkey == customer.c_custkey)
.select(
col("c_custkey").alias("custkey"),
col("c_name").alias("name"),
col("c_nationkey").alias("nationkey"),
col("c_phone").alias("phone"),
col("o_orderkey").alias("orderkey"),
col("o_orderstatus").alias("orderstatus"),
col("o_totalprice").alias("totalprice"),
col("o_orderdate").alias("orderdate"))
)
@dlt.view()
def nation_region():
nation = spark.read.table("samples.tpch.nation")
region = spark.read.table("samples.tpch.region")
return (nation.join(region, nation.n_regionkey == region.r_regionkey)
.select(
col("n_name").alias("nation"),
col("r_name").alias("region"),
col("n_nationkey").alias("nationkey")
)
)
# Extract region names from region table
region_list = spark.read.table("samples.tpch.region").select(collect_list("r_name")).collect()[0][0]
# Iterate through region names to create new region-specific materialized views
for region in region_list:
@dlt.table(name=f"{region.lower().replace(' ', '_')}_customer_orders")
def regional_customer_orders(region_filter=region):
customer_orders = spark.read.table("LIVE.customer_orders")
nation_region = spark.read.table("LIVE.nation_region")
return (customer_orders.join(nation_region, customer_orders.nationkey == nation_region.nationkey)
.select(
col("custkey"),
col("name"),
col("phone"),
col("nation"),
col("region"),
col("orderkey"),
col("orderstatus"),
col("totalprice"),
col("orderdate")
).filter(f"region = '{region_filter}'")
)
下面是此管道的数据流图示例:
故障排除:for 循环创建多个具有相同值的表
管道用于评估 Python 代码的延迟执行模型要求在调用由 @dlt.table() 修饰的函数时,逻辑直接引用单个值。
以下示例演示了使用 for 循环定义表的两种正确方法。 在这两个示例中,tables 列表的每个表名都在由 @dlt.table() 修饰的函数中显式引用。
import dlt
# Create a parent function to set local variables
def create_table(table_name):
@dlt.table(name=table_name)
def t():
return spark.read.table(table_name)
tables = ["t1", "t2", "t3"]
for t_name in tables:
create_table(t_name)
# Call `@dlt.table()` within a for loop and pass values as variables
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dlt.table(name=t_name)
def create_table(table_name=t_name):
return spark.read.table(table_name)
以下示例未正确引用值。 此示例创建具有不同名称的表,但所有表都从 for 循环中的最后一个值加载数据:
import dlt
# Don't do this!
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dlt.table(name=t_name)
def create_table():
return spark.read.table(t_name)