适用于: Azure 数据工厂
Azure 数据工厂  Azure Synapse Analytics
Azure Synapse Analytics
数据整理涉及从其原始源转换和重新格式化数据,使其更适用于各种下游应用程序。
组织需要能够浏览其关键的业务数据,以进行数据准备和整理,从而准确地分析这些每日持续增长的复杂数据。 组织经过数据准备,可以利用各种业务流程中的数据,从而提高效率。
通过数据工厂,用户能够使用 Power Query 反复地进行云规模的无代码数据准备。 数据工厂与 Power Query Online 集成,将 Power Query M 函数作为管道活动使用。
数据工厂通过将 M 转换为 Azure 数据工厂数据流,来将 Power Query Online 混合编辑器生成的 M 转换为 spark 代码,以便实现云规模执行。 整理 Power Query 数据和数据流的数据对于数据工程师或“公民数据集成商”特别有帮助。
用例
快速交互式数据探索和准备
多个数据工程师和公民集成商可通过交互方式进行云规模的数据集探索和准备。 随着数据湖中数据的数量、种类和速度的增长,用户需要一种有效的方法来探索和准备数据集。 例如,用户可能需要创建一个“包含自 2017 年以来所有新客户统计信息”的数据集。 用户没有映射到已知目标。 用户要先探索、整理和准备数据集,满足要求后,才能将数据集发布到数据湖中。 数据整理通常用于不太正式的分析方案。 数据集准备好后可用于执行转换操作和下游的机器学习操作。
无代码的敏捷数据准备
公民数据集成商花费超过 60% 的时间来查找和准备数据。 他们希望以一种无代码的方式来准备数据,从而提高操作效率。 公民数据集成商使用已知的工具(如 Power Query Online)以可扩展的方式来丰富、调整和发布数据,极大地提高了他们的工作效率。 Azure 数据工厂的数据整理功能启用了熟悉的Power Query Online混搭编辑器,使公民数据集成商能够快速修复错误,实现数据标准化,并生成高质量的数据来帮助进行业务决策。
数据验证和探索
以无代码方式浏览数据,删除任何离群值和异常情况,并将其与形状相符合,便于快速分析。
受支持的源
| 连接器 | 数据格式 | 身份验证类型 |
|---|---|---|
| Azure Blob 存储 | CSV、Parquet、Excel | 帐户密钥、服务主体、MSI |
| Azure Data Lake Storage Gen2 | CSV、Parquet、Excel | 帐户密钥、服务主体、MSI |
| Azure SQL 数据库 | - | SQL身份验证、MSI、服务主体 |
| Azure Synapse Analytics | - | SQL身份验证、MSI、服务主体 |
混合编辑器
创建 Power Query 活动时,所有源数据集都将成为数据集查询,并放置在“ADFResource”文件夹中。 默认情况下,UserQuery 将指向第一个数据集查询。 所有转换都应在 UserQuery 上完成,因为不支持对数据集查询进行更改,也不会将其保留。 当前不支持重命名、添加和删除查询。
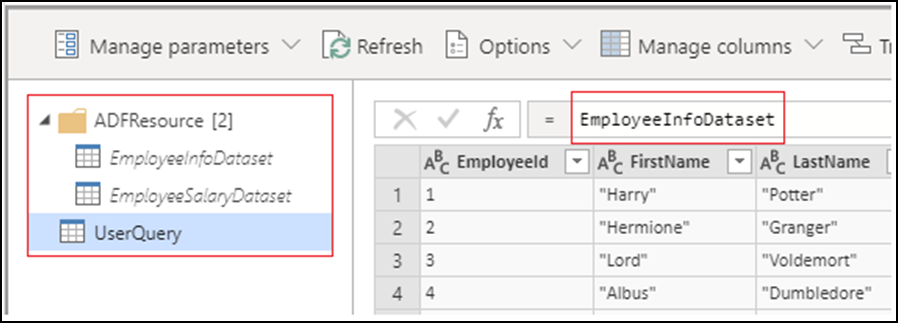
目前,尽管在创作过程中可以使用 Power Query M 函数,但并非所有的 Power Query M 函数都支持用于数据处理。 在构建 Power Query 活动时,如果函数不受支持,系统将提示以下错误消息:
The Power Query Spark Runtime does not support the function
有关支持的转换的详细信息,请参阅 Power Query 数据整理功能。