SAP CDC 高级主题
适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
了解 SAP CDC 连接器的高级主题,例如元数据驱动的数据集成、调试等。
参数化 SAP CDC 映射数据流
Azure 数据工厂 和 Azure Synapse Analytics 中管道和映射数据流的主要优势之一是支持元数据驱动的数据集成。 借助此功能,可以设计一个(或几个)参数化管道,用于处理成百上千个源的集成。 SAP CDC 连接器的设计考虑到了这一原则:所有相关属性(无论是源对象、运行模式、键列等)都可以通过参数提供,以最大程度地提高 SAP CDC 映射数据流的灵活性和重用潜力。
若要了解参数化映射数据流的基本概念,请阅读参数化映射数据流。
在 Azure 数据工厂和 Azure Synapse Analytics 的模板库中,可以找到一个模板管道和数据流,其中显示了如何参数化 SAP CDC 数据引入。
参数化源和运行模式
映射数据流不一定需要数据集工件:源和接收器转换都提供源类型(或接收器类型)内联。 在这种情况下,可以在源转换的源选项(或接收器转换的设置选项卡)中配置在 ADF 数据集中以其他方式定义的所有源属性。 使用内联数据集可以更好地概述并简化映射数据流的参数化,因为完整的源(或接收器)配置会保存在一个位置。
对于 SAP CDC,最常通过参数设置的属性位于源选项和优化选项卡中。 当源类型为内联时,可以在源选项中参数化以下属性。
- ODP 上下文:有效的参数值是
- ABAP_CDS:ABAP 核心数据服务视图
- BW:SAP BW 或 SAP BW/4HANA InfoProviders
- HANA:SAP HANA 信息视图
- SAPI:SAP 数据源/提取器
- 将 SAP 横向转换复制服务器 (SLT) 用作源时,ODP 上下文名称为 SLT~<队列别名>。 队列别名值可以在 SLT 考核中心(SAP 事务 LTRC)的 SLT 配置中的“管理数据”下找到。
- ODP_SELF 和 RANDOM 是用于技术验证和测试的 ODP 上下文,通常不相关。
- ODP 名称:提供要从中提取数据的 ODP 名称。
- 运行模式:有效的参数值是
- fullAndIncrementalLoad 意为第一次运行时为完整,之后增量,它会启动变更数据捕获过程并提取当前的完整数据快照。
- fullLoad 意为每次运行都是完整,它会提取当前的完整数据快照而不会启动变更数据捕获过程。
- incrementalLoad 意为仅增量更改,它会启动变更数据捕获过程而不会提取当前的完整快照。
- 键列:键列作为(双引号内的)字符串数组提供。 例如,当使用 SAP 表 VBAP(销售订单项)时,关键定义必须是 ["VBELN", "POSNR"](或 ["MANDT","VBELN","POSNR"],以防客户端字段也被考虑在内)。
参数化源分区的筛选条件
在优化选项卡中,源分区方案(请参阅优化完整或初始加载的性能)可以通过参数定义。 通常,需要执行两个步骤:
- 定义源分区方案。
- 将分区参数引入映射数据流。
定义源分区方案
步骤 1 中的格式遵循 JSON 标准,由分区定义数组组成,每个定义本身都是单个筛选条件的数组。 这些条件本身是 JSON 对象,其结构与 SAP 中所谓的选择选项保持一致。 事实上,SAP ODP 框架所需的格式基本上与 SAP BW 中的动态 DTP 筛选器相同:
{ "fieldName": <>, "sign": <>, "option": <>, "low": <>, "high": <> }
例如:
{ "fieldName": "VBELN", "sign": "I", "option": "EQ", "low": "0000001000" }
对应于 SQL WHERE 子句 ... WHERE "VBELN" = '0000001000',或
{ "fieldName": "VBELN", "sign": "I", "option": "BT", "low": "0000000000", "high": "0000001000" }
对应于 SQL WHERE 子句 ... WHERE "VBELN" BETWEEN '0000000000' AND '0000001000'
因此,包含两个分区的分区方案的 JSON 定义如下所示
[
[
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2011", "high": "2015" }
],
[
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2016", "high": "2020" }
]
]
其中第一个分区包含 2011 到 2015 财年 (GJAHR),第二个分区包含 2016 到 2020 财年。
注意
Azure 数据工厂不会对这些条件执行任何检查。 例如,确保分区条件不重叠是用户的责任。
分区条件可以更为复杂,包含多个基本筛选条件本身。 没有显式定义如何在一个分区中合并多个基本条件的逻辑连词。 SAP 中的隐式定义如下所示:
- 对于同一字段名称的包括条件 ("sign": "I"),用 OR 来组合(在脑海里,为结果条件加上括号)
- 对于同一字段名称的排除条件 ("sign": "E"),用 OR 来组合(同样,在脑海里,为结果条件加上括号)
- 步骤 1 和 2 的结果条件是
- 对于包括条件,与 AND 组合,
- 对于排除条件,与 AND NOT 组合。
例如,分区条件
[
{ "fieldName": "BUKRS", "sign": "I", "option": "EQ", "low": "1000" },
{ "fieldName": "BUKRS", "sign": "I", "option": "EQ", "low": "1010" },
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2010", "high": "2025" },
{ "fieldName": "GJAHR", "sign": "E", "option": "EQ", "low": "2023" },
{ "fieldName": "GJAHR", "sign": "E", "option": "EQ", "low": "2021" }
]
对应于 SQL WHERE 子句 ... WHERE ("BUKRS" = '1000' OR "BUKRS" = '1010') AND ("GJAHR" BETWEEN '2010' AND '2025') AND NOT ("GJAHR" = '2021' or "GJARH" = '2023')
注意
请确保对低值和高值使用 SAP 内部格式,包括开头的零,并将日历日期表示为八个字符的字符串,格式为“YYYYMMDD”。
将分区参数引入映射数据流
若要将分区方案引入映射数据流,请创建数据流参数(例如“sapPartitions”) 。 若要将 JSON 格式传递给此参数,必须使用 @string() 函数将其转换为字符串:
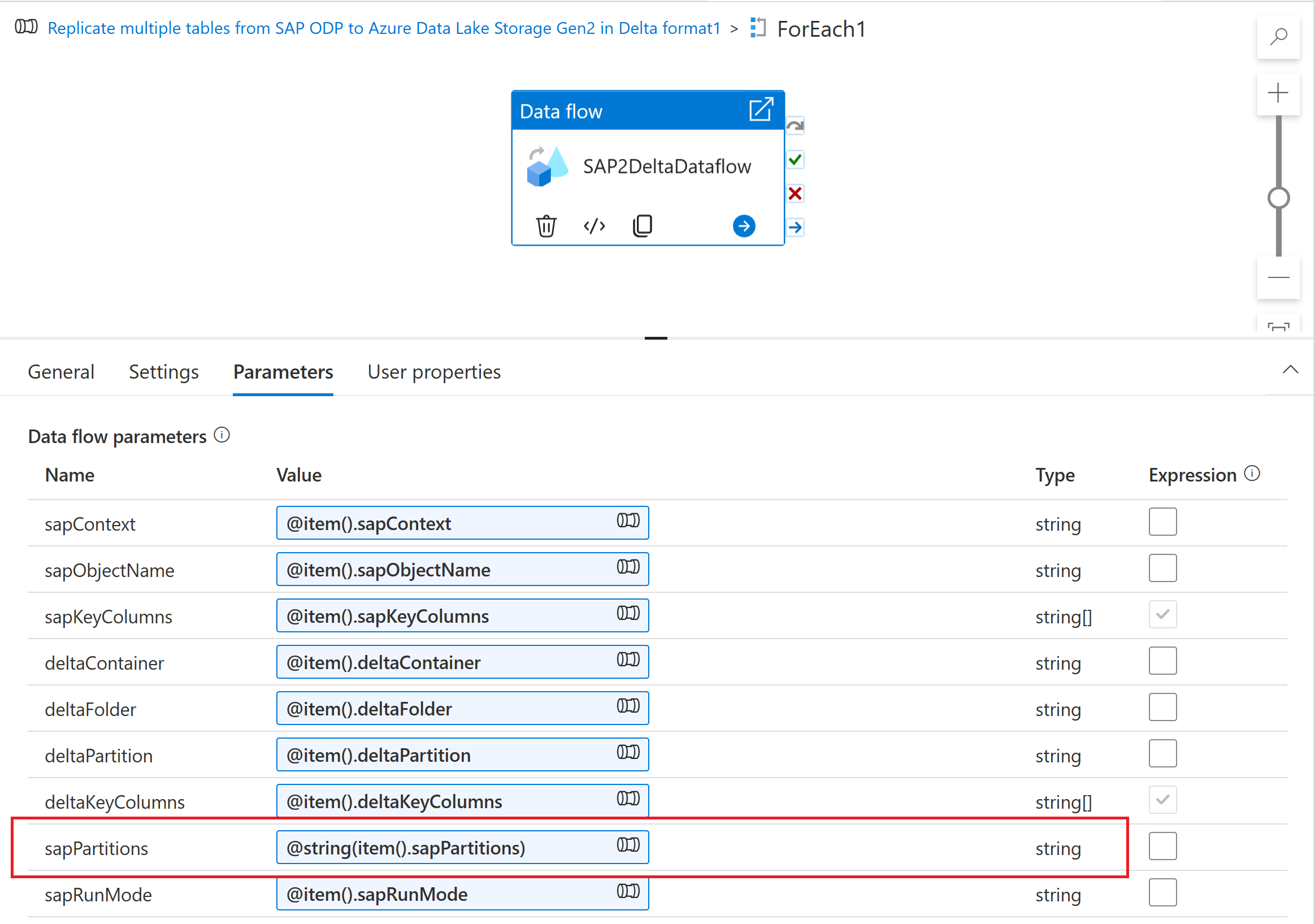
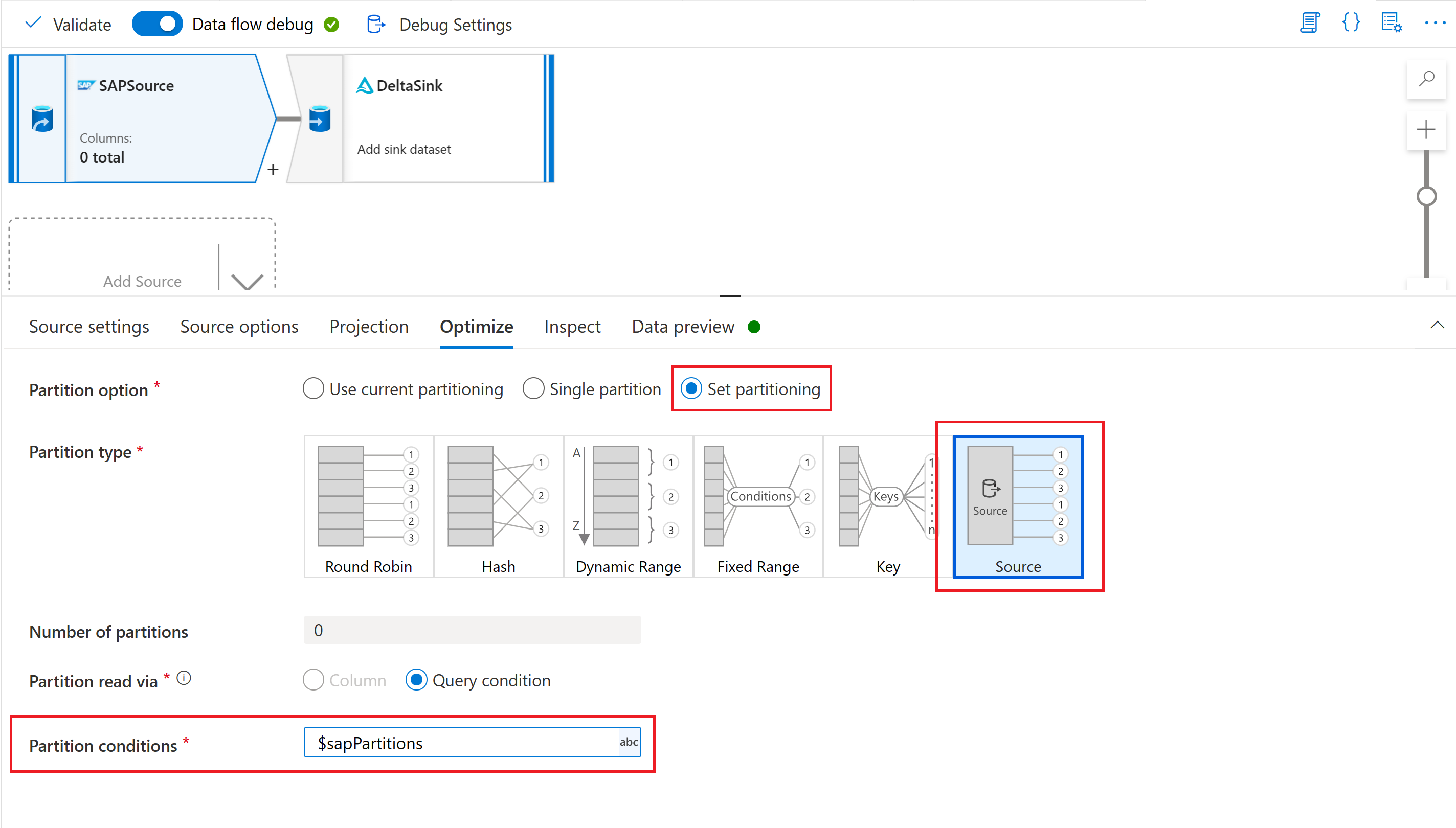
最后,在映射数据流中源转换的优化选项卡中,选择分区类型“源”,并在分区条件属性中输入数据流参数。
参数化检查点密钥
使用参数化数据流从多个 SAP CDC 源中提取数据时,请务必在管道的数据流活动中参数化检查点密钥。 Azure 数据工厂使用检查点密钥来管理变更数据捕获过程的状态。 若要避免一个 CDC 进程的状态覆盖另一个进程的状态,请确保检查点键值对于数据流中使用的每个参数集都是唯一的。
注意
确保检查点键唯一性的最佳做法是将检查点键值添加到数据流的参数集中。
有关检查点密钥的详细信息,请参阅使用 SAP CDC 连接器转换数据。
调试
Azure 数据工厂管道可以通过触发的或调试运行来执行。 这两个选项之间的一个基本区别是,调试运行基于用户界面中建模的当前版本来执行数据流和管道,而触发的运行会执行数据流和管道的上次发布版本。
对于 SAP CDC,还有一个方面需要了解:为了避免调试运行对现有变更数据捕获进程的影响,调试运行会使用不同的“订阅方进程”值(请参阅监视 SAP CDC 数据流),而不是触发的运行。 因此,它们会在 SAP 系统中创建单独的订阅(即变更数据捕获过程)。 此外,调试运行的“订阅方进程”值的生存期仅限于浏览器 UI 会话。
注意
若要在较长时间内(例如,好几天)使用 SAP CDC 测试变更数据捕获过程的稳定性,则需要发布数据流和管道,并且需要执行触发的运行。