适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
本文概述如何使用 Azure 数据工厂或 Synapse Analytics 管道中的复制活动从 Netezza 复制数据。 本文是基于概括性介绍复制活动的复制活动一文编写的。
提示
对于从 Netezza 到 Azure 的数据迁移方案,请在将数据从本地 Netezza 服务器迁移到 Azure 中了解详细信息。
支持的功能
以下功能支持此 Netezza 连接器:
| 支持的功能 | IR |
|---|---|
| 复制活动(源/-) | ① ② |
| Lookup 活动 | ① ② |
① Azure 集成运行时 ② 自承载集成运行时
有关复制活动支持作为源和接收器的数据存储的列表,请参阅支持的数据存储和格式。
此 Netezza 连接器支持:
- 从源进行并行复制。 有关详细信息,请参阅从 Netezza 进行并行复制部分。
- Netezza 性能服务器版本 11。
- 本文章中的 Windows 版本。
服务提供了内置驱动程序,用来启用连接。 无需要手动安装任何驱动程序即可使用此连接器。
先决条件
如果数据存储位于本地网络、Azure 虚拟网络或 Amazon Virtual Private Cloud 内部,则需要配置自承载集成运行时才能连接到该数据存储。
如果数据存储是托管的云数据服务,则可以使用 Azure Integration Runtime。 如果访问范围限制为防火墙规则中允许的 IP,你可以选择将 Azure Integration Runtime IP 添加到允许列表。
此外,还可以使用 Azure 数据工厂中的托管虚拟网络集成运行时功能访问本地网络,而无需安装和配置自承载集成运行时。
要详细了解网络安全机制和数据工厂支持的选项,请参阅数据访问策略。
入门
可以通过使用 .NET SDK、Python SDK、Azure PowerShell、REST API 或 Azure 资源管理器模板创建使用复制活动的管道。 有关创建包含复制活动的管道的分步说明,请参阅复制活动教程。
使用 UI 创建到 Netezza 的链接服务
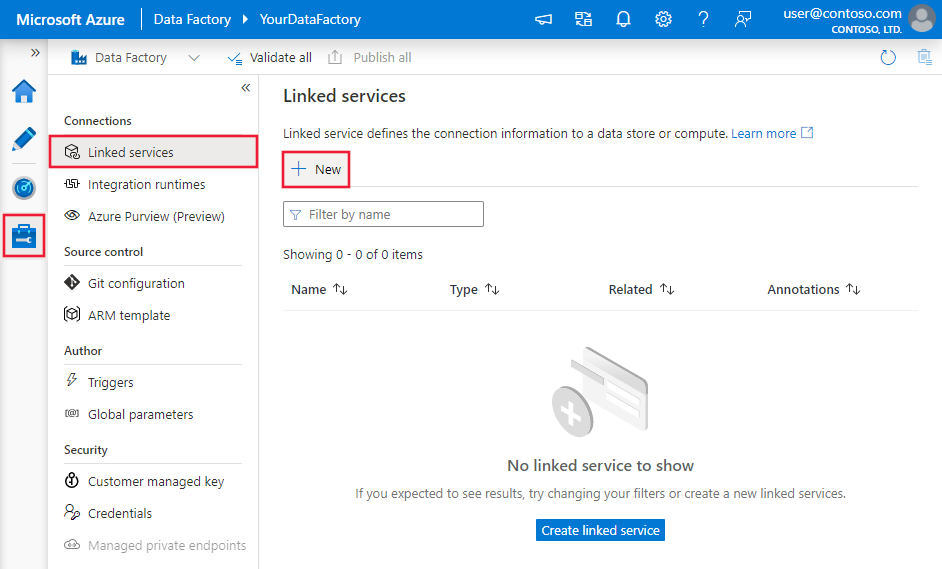
使用以下步骤在 Azure 门户 UI 中创建一个到 Netezza 的链接服务。
浏览到 Azure 数据工厂或 Synapse 工作区中的“管理”选项卡并选择“链接服务”,然后单击“新建”:
搜索“Netezza”,然后选择“Netezza”连接器。

配置服务详细信息、测试连接并创建新的链接服务。
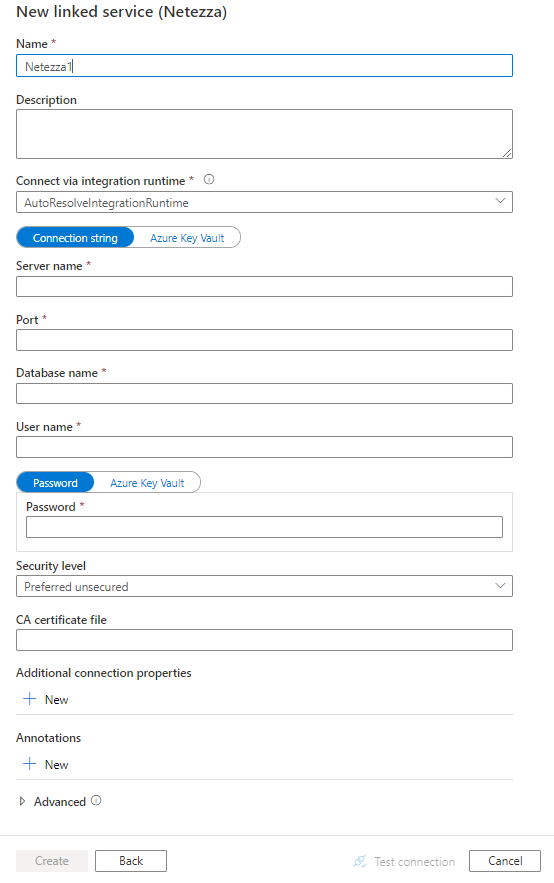
连接器配置详细信息
以下部分详述的属性可用于定义特定于 Netezza 连接器的实体。
链接服务属性
Netezza 链接服务支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| type | “type”属性必须设置为“Netezza” 。 | 是 |
| connectionString | 用于连接到 Netezza 的 ODBC 连接字符串。 还可以将密码放在 Azure 密钥保管库中,并从连接字符串中拉取 pwd 配置。 有关更多详细信息,请参阅以下示例和在 Azure 密钥保管库中存储凭据一文。 |
是 |
| connectVia | 用于连接到数据存储的 Integration Runtime。 从先决条件部分了解更多信息。 如果未指定,则使用默认 Azure Integration Runtime。 | 否 |
典型的连接字符串为 Server=<server>;Port=<port>;Database=<database>;UID=<user name>;PWD=<password>。 下表介绍了更多可以设置的属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| SecurityLevel | 驱动程序用于连接到数据存储的安全级别。 示例: SecurityLevel=preferredUnSecured。 支持的值是:- 仅限未受保护 (onlyUnSecured) :该驱动程序不使用 SSL。 - 首选未受保护 (preferredUnSecured)(默认) :如果该服务器提供选择,则驱动程序不使用 SSL。 |
否 |
注意
该连接器不支持 SSLv3,因为它已被 Netezza 正式弃用。
示例
{
"name": "NetezzaLinkedService",
"properties": {
"type": "Netezza",
"typeProperties": {
"connectionString": "Server=<server>;Port=<port>;Database=<database>;UID=<user name>;PWD=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
示例:在 Azure 密钥保管库中存储密码
{
"name": "NetezzaLinkedService",
"properties": {
"type": "Netezza",
"typeProperties": {
"connectionString": "Server=<server>;Port=<port>;Database=<database>;UID=<user name>;",
"pwd": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
数据集属性
本部分提供 Netezza 数据集支持的属性列表。
若要查看可用于定义数据集的各部分和属性的完整列表,请参阅数据集。
若要从 Netezza 复制数据,请将数据集的 type 属性设置为“NetezzaTable” 。 支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| type | 数据集的 type 属性必须设置为:NetezzaTable | 是 |
| schema | 架构的名称。 | 否(如果指定了活动源中的“query”) |
| 表 | 表的名称。 | 否(如果指定了活动源中的“query”) |
| tableName | 具有架构的表的名称。 支持此属性是为了向后兼容。 对于新的工作负荷,请使用 schema 和 table。 |
否(如果指定了活动源中的“query”) |
示例
{
"name": "NetezzaDataset",
"properties": {
"type": "NetezzaTable",
"linkedServiceName": {
"referenceName": "<Netezza linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {}
}
}
复制活动属性
本部分提供 Netezza 源支持的属性列表。
有关可用于定义活动的各个部分和属性的完整列表,请参阅管道。
以 Netezza 作为源
提示
若要详细了解如何使用数据分区从 Netezza 高效加载数据,请参阅从 Netezza 进行并行复制部分。
若要从 Netezza 复制数据,请将复制活动中的 source 类型设置为“NetezzaSource” 。 复制活动 source 节支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| type | 必须将复制活动源的 type 属性设置为“NetezzaSource” 。 | 是 |
| query | 使用自定义 SQL 查询读取数据。 示例: "SELECT * FROM MyTable" |
否(如果指定了数据集中的“tableName”) |
| partitionOptions | 指定用于从 Netezza 加载数据的数据分区选项。 允许值为:None(默认值)、DataSlice 和 DynamicRange。 启用分区选项(即,该选项不为 None)时,用于从 Netezza 数据库并行加载数据的并行度由复制活动上的 parallelCopies 设置控制。 |
否 |
| partitionSettings | 指定数据分区的设置组。 当分区选项不是 None 时适用。 |
否 |
| partitionColumnName | 指定并行复制范围分区使用的源列(整数类型)的名称。 如果未指定,系统会自动检测表的主键并将其用作分区列。 当分区选项是 DynamicRange 时适用。 如果使用查询来检索源数据,请在 WHERE 子句中挂接 ?AdfRangePartitionColumnName。 请参阅从 Netezza 进行并行复制部分的示例。 |
否 |
| partitionUpperBound | 要从中复制数据的分区列的最大值。 当分区选项是 DynamicRange 时适用。 如果使用查询来检索源数据,请在 WHERE 子句中挂接 ?AdfRangePartitionUpbound。 如需示例,请参阅从 Netezza 进行并行复制部分。 |
否 |
| partitionLowerBound | 要从中复制数据的分区列的最小值。 当分区选项是 DynamicRange 时适用。 如果使用查询来检索源数据,请在 WHERE 子句中挂接 ?AdfRangePartitionLowbound。 如需示例,请参阅从 Netezza 进行并行复制部分。 |
否 |
示例:
"activities":[
{
"name": "CopyFromNetezza",
"type": "Copy",
"inputs": [
{
"referenceName": "<Netezza input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "NetezzaSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
从 Netezza 进行并行复制
数据工厂 Netezza 连接器提供内置的数据分区,用于从 Netezza 并行复制数据。 可以在复制活动的“源”表中找到数据分区选项。

启用分区复制后,服务将对 Netezza 源运行并行查询,以便按分区加载数据。 可通过复制活动中的 parallelCopies 设置控制并行度。 例如,如果将 parallelCopies 设置为 4,服务会根据指定的分区选项和设置并行生成并运行 4 个查询,每个查询从 Netezza 数据库检索一部分数据。
建议同时启用并行复制和数据分区,尤其是从 Netezza 数据库加载大量数据时。 下面是适用于不同方案的建议配置。 将数据复制到基于文件的数据存储中时,建议将数据作为多个文件写入文件夹(仅指定文件夹名称),在这种情况下,性能优于写入单个文件。
| 方案 | 建议的设置 |
|---|---|
| 从大型表进行完整加载。 | 分区选项:数据切片。 在执行期间,服务会自动根据 Netezza 的内置数据切片将数据分区,并按分区复制数据。 |
| 使用自定义查询加载大量数据。 | 分区选项:数据切片。 查询: SELECT * FROM <TABLENAME> WHERE mod(datasliceid, ?AdfPartitionCount) = ?AdfDataSliceCondition AND <your_additional_where_clause>。在执行期间,服务会将 ?AdfPartitionCount(并行复制数在复制活动中设置)和 ?AdfDataSliceCondition 替换为数据切片分区逻辑,并将其发送到 Netezza。 |
| 使用自定义查询加载大量数据,某个整数列包含均匀分布的范围分区值。 | 分区选项:动态范围分区。 查询: SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>。分区列:指定用于对数据进行分区的列。 可以针对整数数据类型的列进行分区。 分区上限和分区下限:指定是否要对分区列进行筛选,以便仅检索介于下限和上限之间的数据。 在执行期间,服务会将 ?AdfRangePartitionColumnName、?AdfRangePartitionUpbound 和 ?AdfRangePartitionLowbound 替换为每个分区的实际列名称和值范围,并将其发送到 Netezza。 例如,如果为分区列“ID”设置了下限 1、上限 80,并将并行复制设置为 4,则服务会按 4 个分区检索数据。 其 ID 分别介于 [1, 20]、[21, 40]、[41, 60] 和 [61, 80] 之间。 |
示例:使用数据切片分区进行查询
"source": {
"type": "NetezzaSource",
"query": "SELECT * FROM <TABLENAME> WHERE mod(datasliceid, ?AdfPartitionCount) = ?AdfDataSliceCondition AND <your_additional_where_clause>",
"partitionOption": "DataSlice"
}
示例:使用动态范围分区进行查询
"source": {
"type": "NetezzaSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<dynamic_range_partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column>",
"partitionLowerBound": "<lower_value_of_partition_column>"
}
}
Lookup 活动属性
若要了解有关属性的详细信息,请查看 Lookup 活动。
相关内容
有关复制活动支持作为源和接收器的数据存储的列表,请参阅支持的数据存储和格式。