适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
本文概述了如何使用 Azure 数据工厂和 Azure Synapse 中的复制活动向/从 Azure Databricks Delta Lake 复制数据。 本文是根据总体概述复制活动的复制活动一文编写的。
支持的功能
此 Azure Databricks Delta Lake 连接器支持以下功能:
| 支持的功能 | IR |
|---|---|
| 复制活动(源/接收器) | ① ② |
| 映射数据流源(源/接收器) | ① |
| Lookup 活动 | ① ② |
① Azure 集成运行时 ② 自承载集成运行时
通常,该服务支持使用具有以下功能的 Delta Lake 来满足你的各种需求。
- 复制活动支持使用 Azure Databricks Delta Lake 连接器将数据从任何受支持的源数据存储复制到 Azure Databricks Delta Lake 表,以及从 Delta Lake 表复制到任何受支持的接收器数据存储。 它利用 Databricks 群集执行数据移动,详见“先决条件”部分。
- 映射数据流支持将 Azure 存储上的通用 Delta 格式作为源和接收器,以便读取和写入无代码 ETL 的 Delta 文件,并在托管 Azure Integration Runtime 上运行。
- Databricks 活动支持在 Delta Lake 之上协调以代码为中心的 ETL 或机器学习工作负荷。
先决条件
若要使用此 Azure Databricks Delta Lake 连接器,你需要在 Azure Databricks 中设置群集。
- 为了将数据复制到 Delta Lake,复制活动会调用 Azure Databricks 群集来从 Azure 存储中读取数据。该存储可以是原始源,也可以是该服务通过内置的暂存复制首先将源数据写入到其中的暂存区域。 从 Delta Lake 作为接收器中了解详细信息。
- 类似地,为了从 Delta Lake 复制数据,复制活动会调用 Azure Databricks 群集来将数据写入到 Azure 存储。该存储可以是你的原始接收器,也可以是该服务通过内置的暂存复制继续从中将数据写入到最终接收器的暂存区域。 从 Delta Lake 作为源中了解详细信息。
Databricks 群集需要有权访问 Azure Blob 或 Azure Data Lake Storage Gen2 帐户、用于源/接收器/暂存的存储容器/文件系统,以及要在其中写入 Delta Lake 表的容器/文件系统。
若要使用 Azure Data Lake Storage Gen2,你可以在 Databricks 群集上的 Apache Spark 配置中配置服务主体。 根据直接使用服务主体访问中的步骤操作。
若要使用 Azure Blob 存储,你可以在 Databricks 群集上的 Apache Spark 配置中配置存储帐户访问密钥或 SAS 令牌。 按照使用 RDD API 访问 Azure Blob 存储中的步骤进行操作。
在复制活动执行期间,如果你配置的群集已终止,则该服务会自动启动它。 如果你使用创作 UI 来创作管道,则对于数据预览之类的操作,你需要有一个实时群集,该服务不会代表你启动群集。
指定群集配置
在“群集模式”下拉列表中,选择“标准” 。
在“Databricks Runtime 版本”下拉列表中,选择一个 Databricks 运行时版本。
-
spark.databricks.delta.optimizeWrite.enabled true spark.databricks.delta.autoCompact.enabled true 根据集成和缩放需求配置群集。
有关群集配置的详细信息,请参阅配置群集。
入门
若要使用管道执行复制活动,可以使用以下工具或 SDK 之一:
使用 UI 创建到 Azure Databricks Delta Lake 的链接服务
使用以下步骤在 Azure 门户 UI 中创建一个到 Azure Databricks Delta Lake 的链接服务。
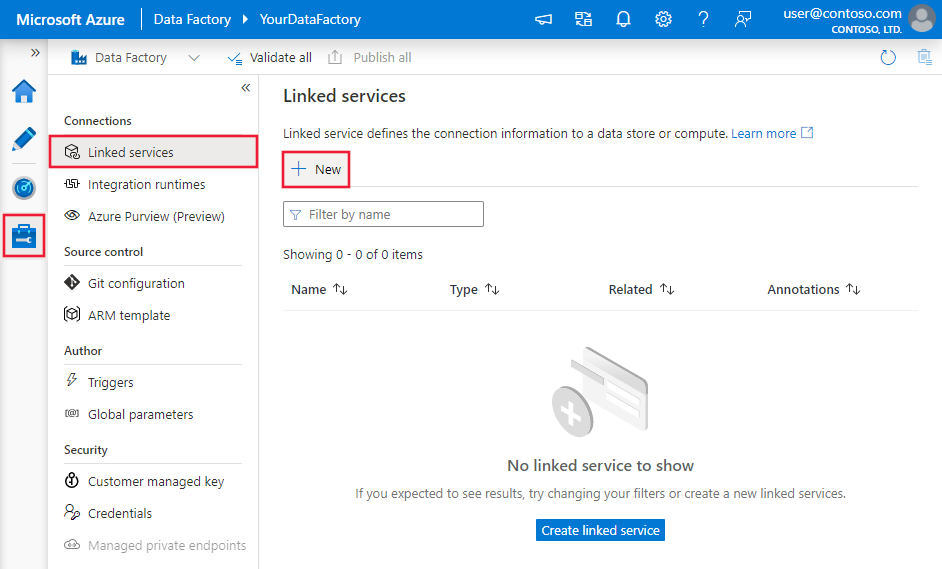
浏览到 Azure 数据工厂或 Synapse 工作区中的“管理”选项卡并选择“链接服务”,然后单击“新建”:
搜索“delta”并选择 Azure Databricks Delta Lake 连接器。

配置服务详细信息、测试连接并创建新的链接服务。
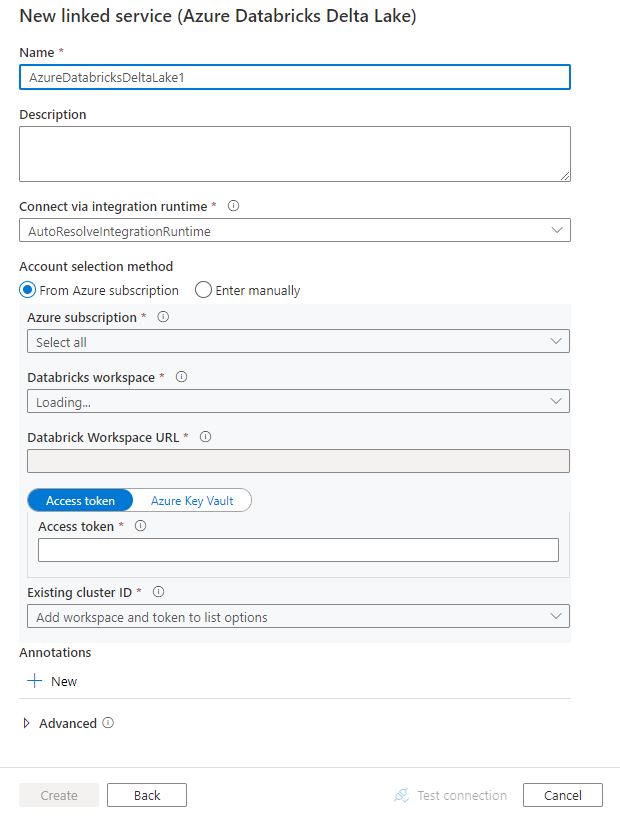
连接器配置详细信息
以下部分详细介绍了用来定义特定于 Azure Databricks Delta Lake 连接器的实体的属性。
链接服务属性
此 Azure Databricks Delta Lake 连接器支持以下身份验证类型。 有关详细信息,请参阅相应部分。
访问令牌
Azure Databricks Delta Lake 链接服务支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| type | type 属性必须设置为 AzureDatabricksDeltaLake。 | 是 |
| 域 | 指定 Azure Databricks 工作区 URL,例如 https://adb-xxxxxxxxx.xx.databricks.azure.cn。 |
|
| clusterId | 指定现有群集的群集 ID。 该群集应该是已创建的交互式群集。 可以通过 Databricks 工作区 ->“群集”->“交互式群集名称”->“配置”->“标记”找到交互式群集的群集 ID。 了解详细信息。 |
|
| accessToken | 该服务通过 Azure Databricks 进行身份验证时,必须使用访问令牌。 需从 Databricks 工作区生成访问令牌。 此处提供了查找访问令牌的更多详细步骤。 | |
| connectVia | 用于连接到数据存储的 Integration Runtime。 可使用 Azure Integration Runtime 或自承载集成运行时(如果数据存储位于专用网络)。 如果未指定,则使用默认 Azure Integration Runtime。 | 否 |
示例:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.databricks.azure.cn",
"clusterId": "<cluster id>",
"accessToken": {
"type": "SecureString",
"value": "<access token>"
}
}
}
}
系统分配的托管标识身份验证
若要详细了解 Azure 资源系统分配的托管标识,请参阅 Azure 资源系统分配的托管标识。
若要使用系统分配的托管标识身份验证,请按照以下步骤授予权限:
通过复制与数据工厂或 Synapse 工作区一起生成的“托管标识对象 ID”值,检索托管标识信息。
在 Azure Databricks 中向托管标识授予正确的权限。 一般情况下,必须至少在 Azure Databricks 的访问控制 (IAM) 中向系统分配的托管标识授予“参与者”角色。
Azure Databricks Delta Lake 链接服务支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| type | type 属性必须设置为 AzureDatabricksDeltaLake。 | 是 |
| 域 | 指定 Azure Databricks 工作区 URL,例如 https://adb-xxxxxxxxx.xx.databricks.azure.cn。 |
是 |
| clusterId | 指定现有群集的群集 ID。 该群集应该是已创建的交互式群集。 可以通过 Databricks 工作区 ->“群集”->“交互式群集名称”->“配置”->“标记”找到交互式群集的群集 ID。 了解详细信息。 |
是 |
| workspaceResourceId | 指定 Azure Databricks 的工作区资源 ID。 | 是 |
| connectVia | 用于连接到数据存储的 Integration Runtime。 可使用 Azure Integration Runtime 或自承载集成运行时(如果数据存储位于专用网络)。 如果未指定,则使用默认 Azure Integration Runtime。 | 否 |
示例:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.databricks.azure.cn",
"clusterId": "<cluster id>",
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
用户分配的托管标识身份验证
若要详细了解 Azure 资源用户分配的托管标识,请参阅用户分配的托管标识
若要使用用户分配的托管标识身份验证,请执行以下步骤:
创建一个或多个用户分配的托管标识,并在 Azure Databricks 中授予权限。 一般情况下,必须至少在 Azure Databricks 的访问控制 (IAM) 中向用户分配的托管标识授予“参与者”角色。
为数据工厂或 Synapse 工作区分配一个或多个用户分配的托管标识,并为每个用户分配的托管标识创建凭据。
Azure Databricks Delta Lake 链接服务支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| type | type 属性必须设置为 AzureDatabricksDeltaLake。 | 是 |
| 域 | 指定 Azure Databricks 工作区 URL,例如 https://adb-xxxxxxxxx.xx.databricks.azure.cn。 |
是 |
| clusterId | 指定现有群集的群集 ID。 该群集应该是已创建的交互式群集。 可以通过 Databricks 工作区 ->“群集”->“交互式群集名称”->“配置”->“标记”找到交互式群集的群集 ID。 了解详细信息。 |
是 |
| 凭据 | 将用户分配的托管标识指定为凭据对象。 | 是 |
| workspaceResourceId | 指定 Azure Databricks 的工作区资源 ID。 | 是 |
| connectVia | 用于连接到数据存储的 Integration Runtime。 可使用 Azure Integration Runtime 或自承载集成运行时(如果数据存储位于专用网络)。 如果未指定,则使用默认 Azure Integration Runtime。 | 否 |
示例:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.databricks.azure.cn",
"clusterId": "<cluster id>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
数据集属性
有关可用于定义数据集的各部分和属性的完整列表,请参阅数据集一文。
Azure Databricks Delta Lake 数据集支持以下属性。
| Property | 描述 | 必需 |
|---|---|---|
| type | 数据集的 type 属性必须设置为 AzureDatabricksDeltaLakeDataset。 | 是 |
| database | 数据库的名称。 | 对于源为“否”,对于接收器为“是” |
| 表 | 增量表的名称。 | 对于源为“否”,对于接收器为“是” |
示例:
{
"name": "AzureDatabricksDeltaLakeDataset",
"properties": {
"type": "AzureDatabricksDeltaLakeDataset",
"typeProperties": {
"database": "<database name>",
"table": "<delta table name>"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference"
}
}
}
复制活动属性
有关可用于定义活动的各部分和属性的完整列表,请参阅管道一文。 本部分提供了 Azure Databricks Delta Lake 源和接收器支持的属性的列表。
Delta Lake 作为源
为了从 Azure Databricks Delta Lake 复制数据,复制活动的 source 节需要支持以下属性。
| Property | 描述 | 必需 |
|---|---|---|
| type | 复制活动源的 type 属性必须设置为 AzureDatabricksDeltaLakeSource。 | 是 |
| query | 指定用于读取数据的 SQL 查询。 对于“按时间顺序查看”控制,请遵循以下模式: - SELECT * FROM events TIMESTAMP AS OF timestamp_expression- SELECT * FROM events VERSION AS OF version |
否 |
| exportSettings | 用于从增量表检索数据的高级设置。 | 否 |
在 exportSettings 下: |
||
| type | 导出命令的类型,设置为 AzureDatabricksDeltaLakeExportCommand。 | 是 |
| dateFormat | 将日期类型格式化为具有日期格式的字符串。 自定义日期格式遵循日期/时间模式中的格式。 如果未指定,则它使用默认值 yyyy-MM-dd。 |
否 |
| timestampFormat | 将时间戳类型格式化为具有时间戳格式的字符串。 自定义日期格式遵循日期/时间模式中的格式。 如果未指定,则它使用默认值 yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]。 |
否 |
从 Delta Lake 进行的直接复制
如果接收器数据存储和格式符合此部分所述条件,则可使用复制活动将数据从 Azure Databricks Delta 表直接复制到接收器。 该服务将检查设置,如果不符合以下条件,复制活动运行将会失败:
接收器链接服务是 Azure Blob 存储或 Azure Data Lake Storage Gen2。 应当在 Azure Databricks 群集配置中预先配置帐户凭据,请从先决条件中了解详细信息。
接收器数据格式为“Parquet”、“带分隔符的文本”或“Avro”,具有以下配置,并且指向文件夹而非文件。
- 对于“Parquet”格式,压缩编解码器为“none”、“snappy”或或“gzip”。
- 对于“带分隔符的文本”格式:
rowDelimiter是任意单个字符。compression可以是“none”、“bzip2”、“gzip”。- 不支持
encodingNameUTF-7。
- 对于“Avro”格式,压缩编解码器为“none”、“deflate”或“snappy”。
在复制活动源中,
additionalColumns未指定。如果将数据复制为带分隔符的文本,则在复制活动接收器中,
fileExtension需要是“.csv”。在复制活动映射中,未启用类型转换。
示例:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
}
}
}
]
从 Delta Lake 进行的暂存复制
如上一部分所述,如果接收器数据存储或格式与直接复制条件不匹配,请通过临时的 Azure 存储实例启用内置的暂存复制。 暂存复制功能也能提供更高的吞吐量。 该服务将数据从 Azure Databricks Delta Lake 导出到暂存存储,然后将数据复制到接收器,最后从暂存存储中清除临时数据。 若要详细了解如何通过暂存方式复制数据,请参阅暂存复制。
若要使用此功能,请创建 Azure Blob 存储链接服务或 Azure Data Lake Storage Gen2 链接服务,该服务引用作为临时暂存帐户的存储帐户。 然后,在复制活动中指定 enableStaging 和 stagingSettings 属性。
注意
应当在 Azure Databricks 群集配置中预先配置暂存存储帐户凭据,请从先决条件中了解详细信息。
示例:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Delta Lake 作为接收器
为了将数据复制到 Azure Databricks Delta Lake,复制活动的 sink 节需要支持以下属性。
| Property | 描述 | 必需 |
|---|---|---|
| type | 复制活动接收器的 type 属性,设置为 AzureDatabricksDeltaLakeSink。 | 是 |
| preCopyScript | 指定一个 SQL 查询。每次运行时,复制活动在将数据写入到 Databricks 增量表之前都会运行该查询。 示例:VACUUM eventsTable DRY RUN。你可以使用此属性清除预加载的数据,或者添加 truncate table 或 Vacuum 语句。 |
否 |
| importSettings | 用于将数据写入增量表的高级设置。 | 否 |
在 importSettings 下: |
||
| type | 导入命令的类型,设置为 AzureDatabricksDeltaLakeImportCommand。 | 是 |
| dateFormat | 将字符串格式化为具有日期格式的日期类型。 自定义日期格式遵循日期/时间模式中的格式。 如果未指定,则它使用默认值 yyyy-MM-dd。 |
否 |
| timestampFormat | 将字符串格式化为具有时间戳格式的时间戳类型。 自定义日期格式遵循日期/时间模式中的格式。 如果未指定,则它使用默认值 yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]。 |
否 |
到 Delta Lake 的直接复制
如果源数据存储和格式符合此部分所述条件,则可使用复制活动将数据从源直接复制到 Azure Databricks Delta Lake。 该服务将检查设置,如果不符合以下条件,复制活动运行将会失败:
源链接服务是 Azure Blob 存储或 Azure Data Lake Storage Gen2。 应当在 Azure Databricks 群集配置中预先配置帐户凭据,请从先决条件中了解详细信息。
源数据格式为“Parquet”、“带分隔符的文本”或“Avro”,具有以下配置,并且指向文件夹而非文件。
- 对于“Parquet”格式,压缩编解码器为“none”、“snappy”或或“gzip”。
- 对于“带分隔符的文本”格式:
rowDelimiter为默认值或任意单个字符。compression可以是“none”、“bzip2”、“gzip”。- 不支持
encodingNameUTF-7。
- 对于“Avro”格式,压缩编解码器为“none”、“deflate”或“snappy”。
在复制活动源中:
wildcardFileName仅包含通配符*而未包含?,未指定wildcardFolderName。- 未指定
prefix、modifiedDateTimeStart、modifiedDateTimeEnd和enablePartitionDiscovery。 - 未指定
additionalColumns。
在复制活动映射中,未启用类型转换。
示例:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink",
"sqlReaderQuery": "VACUUM eventsTable DRY RUN"
}
}
}
]
到 Delta Lake 的暂存复制
如上一部分所述,如果源数据存储或格式与直接复制条件不匹配,请通过临时的 Azure 存储实例启用内置的暂存复制。 暂存复制功能也能提供更高的吞吐量。 该服务会自动转换数据以满足暂存存储中的数据格式要求,然后再从其中将数据加载到 Delta Lake。 最后,它会从存储中清理临时数据。 若要详细了解如何通过暂存方式复制数据,请参阅暂存复制。
若要使用此功能,请创建 Azure Blob 存储链接服务或 Azure Data Lake Storage Gen2 链接服务,该服务引用作为临时暂存帐户的存储帐户。 然后,在复制活动中指定 enableStaging 和 stagingSettings 属性。
注意
应当在 Azure Databricks 群集配置中预先配置暂存存储帐户凭据,请从先决条件中了解详细信息。
示例:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
监视
为其他连接器提供了相同的复制活动监视体验。 此外,因为是在 Azure Databricks 群集上向/从 Delta Lake 加载数据,所以可以进一步查看详细的群集日志并监视性能。
查找活动属性
有关属性的详细信息,请参阅查找活动。
查找活动最多可以返回 1000 行;如果结果集包含的记录超过此范围,将返回前 1000 行。
相关内容
有关复制活动支持作为源和接收器的数据存储的列表,请参阅支持的数据存储和格式。