适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
本文概述了如何使用 Azure 数据工厂和 Synapse Analytics 管道中的复制活动从/向 Azure Database for PostgreSQL 复制数据,以及如何使用数据流转换 Azure Database for PostgreSQL 中的数据。 有关详细信息,请阅读 Azure 数据工厂和 Synapse Analytics 的简介文章。
重要
Azure Database for PostgreSQL 版本 2.0 提供了改进的本机 Azure Database for PostgreSQL 支持。 如果在解决方案中使用 Azure Database for PostgreSQL 版本 1.0,建议尽早 升级 Azure Database for PostgreSQL 连接器 。
此连接器专用于 Azure Database for PostgreSQL 服务。 若要从位于本地或云中的通用 PostgreSQL 数据库复制数据,请使用 PostgreSQL 连接器。
支持的功能
此 Azure Database for PostgreSQL 连接器支持以下功能:
| 支持的功能 | IR | 托管专用终结点 |
|---|---|---|
| 复制活动(源/接收器) | ① ② | ✓ |
| 映射数据流源(源/接收器) | ① | ✓ |
| 查找活动 | ① ② | ✓ |
① Azure 集成运行时 ② 自承载集成运行时
这三个活动适用于 Azure Database for PostgreSQL 单一服务器 和 灵活服务器,以及 Azure Cosmos DB for PostgreSQL。
入门
若要使用管道执行复制活动,可以使用以下工具或 SDK 之一:
使用 UI 创建一个到 Azure Database for PostgreSQL 的链接服务
使用以下步骤在 Azure 门户 UI 中创建一个到 Azure Database for PostgreSQL 的链接服务。
浏览到 Azure 数据工厂或 Synapse 工作区中的“管理”选项卡并选择“链接服务”,然后单击“新建”:
搜索 PostgreSQL 并选择 Azure Database for PostgreSQL 连接器。
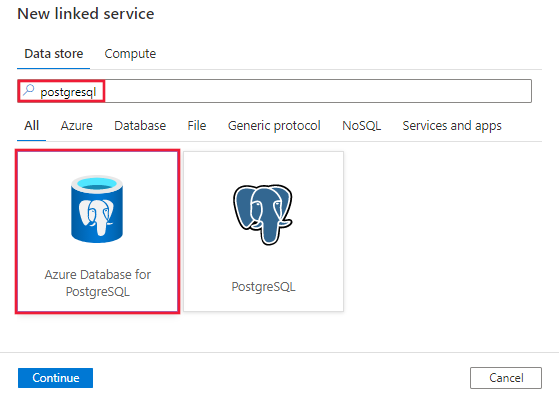
配置服务详细信息、测试连接并创建新的链接服务。
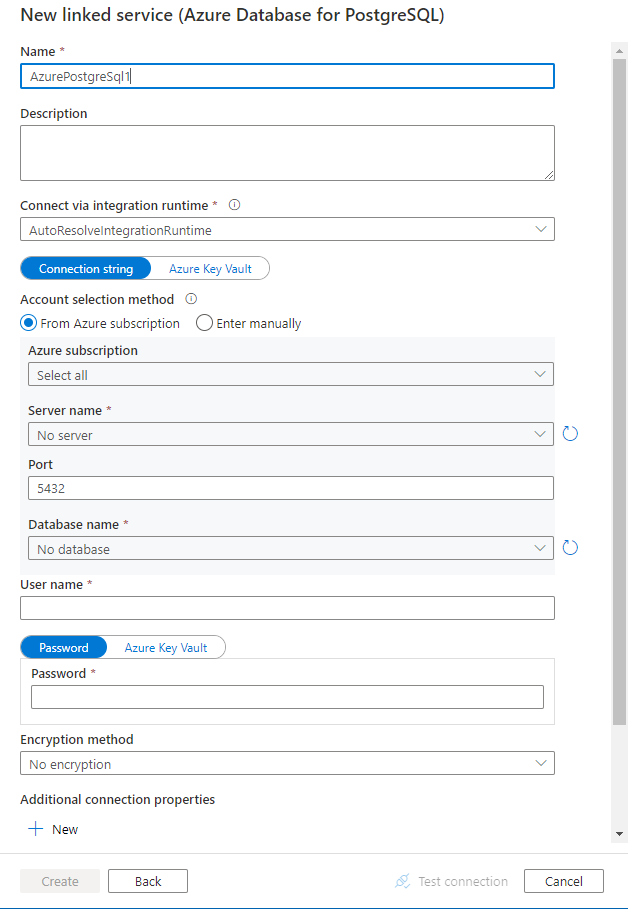
连接器配置详细信息
以下部分提供详细信息,描述用于定义特定于 Azure Database for PostgreSQL 连接器的数据工厂实体的属性。
链接服务属性
Azure Database for PostgreSQL 连接器版本 2.0 支持 TLS 1.3 和多个 SSL 模式。 请参阅本 部分 ,从版本 1.0 升级 Azure SQL 数据库连接器版本。 有关属性详细信息,请参阅相应部分。
版本 2.0
应用版本 2.0 时,Azure Database for PostgreSQL 链接服务支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | type 属性必须设置为:AzurePostgreSql。 | 是 |
| 版本 | 指定的版本。 该值为 2.0。 |
是 |
| 服务器 | 指定运行 Azure Database for PostgreSQL 的主机名和可选端口。 | 是 |
| 港口 | Azure Database for PostgreSQL 服务器的 TCP 端口。 默认值是 5432。 |
否 |
| 数据库 | 要连接到的 Azure Database for PostgreSQL 数据库的名称。 | 是 |
| 用户名 | 要连接的用户名。 如果使用 IntegratedSecurity,则不需要。 | 是 |
| 密码 | 要用于连接的密码。 如果使用 IntegratedSecurity,则不需要。 将此字段标记为 SecureString 以安全存储它。 或者,可以引用 Azure Key Vault 中存储的机密。 | 是 |
| SSL模式 | 控制是否使用 SSL,具体取决于服务器支持。 - 禁用:已禁用 SSL。 如果服务器需要 SSL,则连接将失败。 - 允许:如果服务器允许非 SSL 连接,则首选非 SSL 连接,但允许 SSL 连接。 - 首选:如果服务器允许 SSL 连接,则首选 SSL 连接,但允许不使用 SSL 的连接。 - 要求:如果服务器不支持 SSL,连接将失败。 - Verify-ca:如果服务器不支持 SSL,连接将失败。 同时验证服务器证书。 - 完全验证:如果服务器不支持 SSL,连接将失败。 还通过主机名验证服务器证书。 选项:禁用 (0) / 允许 (1) / 首选 (2)(默认)/ 需要 (3) / Verify-ca (4) / Verify-full (5) |
否 |
| connectVia | 此属性表示用于连接到数据存储的集成运行时。 如果数据存储位于专用网络,则可以使用 Azure Integration Runtime 或自承载集成运行时。 如果未指定,则使用默认 Azure Integration Runtime。 | 否 |
| 其他连接属性: | ||
| 图式 | 设置架构搜索路径。 | 否 |
| 池 | 是否应使用连接池。 | 否 |
| connectionTimeout | 等待的时间(以秒为单位),这是在尝试建立连接时,终止尝试并生成错误之前的时间。 | 否 |
| commandTimeout | 在终止尝试并生成错误之前,尝试执行命令的等待时间(以秒为单位)。 对于无穷大,设置为零。 | 否 |
| trustServerCertificate | 是否在不验证的情况下信任服务器证书。 | 否 |
| readBufferSize | 确定读取时 Npgsql 使用的内部缓冲区大小。 如果从数据库传输大型值,则增加大小可能会提高性能。 | 否 |
| 时区 | 获取或设置会话时区。 | 否 |
| 编码 | 获取或设置用于编码/解码 PostgreSQL 字符串数据的 .NET 编码格式。 | 否 |
示例:
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": "5432",
"database": "<database name>",
"sslMode": 2,
"username": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
示例:
在 Azure 密钥保管库中存储密码
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"port": "5432",
"database": "<database name>",
"sslMode": 2,
"username": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
}
}
}
版本 1.0
应用版本 1.0 时,Azure Database for PostgreSQL 链接服务支持以下属性:
| 物业 | 描述 | 必需 |
|---|---|---|
| 类型 | type 属性必须设置为:AzurePostgreSql。 | 是 |
| 版本 | 指定的版本。 该值为 1.0。 |
是 |
| connectionString | 用于连接到 Azure Database for PostgreSQL 的 Npgsql 连接字符串。 还可以将密码放在 Azure 密钥保管库中,并从连接字符串中拉取 password 配置。 有关更多详细信息,请参阅以下示例和在 Azure 密钥保管库中存储凭据。 |
是 |
| connectVia | 此属性表示用于连接到数据存储的集成运行时。 如果数据存储位于专用网络,则可以使用 Azure Integration Runtime 或自承载集成运行时。 如果未指定,则使用默认 Azure Integration Runtime。 | 否 |
典型的连接字符串为 host=<server>.postgres.database.chinacloudapi.cn;database=<database>;port=<port>;uid=<username>;password=<password>。 以下是你可以根据具体情况设置的更多属性:
| 属性 | 描述 | 选项 | 必需 |
|---|---|---|---|
| EncryptionMethod (EM) | 驱动程序用于加密在驱动程序和数据库服务器之间发送的数据的方法。 例如: EncryptionMethod=<0/1/6>; |
0 (No Encryption) (Default) / 1 (SSL) / 6 (RequestSSL) | 否 |
| ValidateServerCertificate (VSC) | 启用 SSL 加密后,确定驱动程序是否验证数据库服务器发送的证书(加密方法=1)。 例如: ValidateServerCertificate=<0/1>; |
0 (禁用) (默认) / 1 (启用) | 否 |
示例:
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "1.0",
"typeProperties": {
"connectionString": "host=<server>.postgres.database.chinacloudapi.cn;database=<database>;port=<port>;uid=<username>;password=<password>"
}
}
}
示例:
在 Azure 密钥保管库中存储密码
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"version": "1.0",
"typeProperties": {
"connectionString": "host=<server>.postgres.database.chinacloudapi.cn;database=<database>;port=<port>;uid=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
}
}
}
数据集属性
有关可用于定义数据集的各个部分和属性的完整列表,请参阅数据集。 本部分提供数据集中 Azure Database for PostgreSQL 支持的属性列表。
要从 Azure Database for PostgreSQL 复制数据,请将数据集的 type 属性设置为 AzurePostgreSqlTable。 支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 数据集的 type 属性必须设置为 AzurePostgreSqlTable | 是 |
| tableName | 表名称 | 否(如果指定了活动源中的“query”) |
示例:
{
"name": "AzurePostgreSqlDataset",
"properties": {
"type": "AzurePostgreSqlTable",
"linkedServiceName": {
"referenceName": "<AzurePostgreSql linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {}
}
}
复制活动属性
有关可用于定义活动的各个部分和属性的完整列表,请参阅管道和活动。 本部分提供 Azure Database for PostgreSQL 源支持的属性列表。
用于 PostgreSql 的 Azure 数据库作为源
要从 Azure Database for PostgreSQL 复制数据,请将复制活动中的源类型设置为 AzurePostgreSqlSource。 复制活动source部分支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 复制活动源的 type 属性必须设置为 AzurePostgreSqlSource | 是 |
| 查询 | 使用自定义 SQL 查询读取数据。 例如 SELECT * FROM mytable 或 SELECT * FROM "MyTable"。 请注意,在 PostgreSQL 中,如果未加引号,则实体名称不区分大小写。 |
否(如果指定了数据集中的 tableName 属性) |
| queryTimeout | 终止尝试执行命令并生成错误之前的等待时间,默认值为 120 分钟。 如果为此属性设置了参数,则允许的值是时间跨度,例如“02:00:00”(120 分钟)。 有关详细信息,请参阅 CommandTimeout。 | 否 |
| 分区选项 | 指定用于从 Azure SQL 数据库加载数据的数据分区选项。 允许值包括:None(默认值)、PhysicalPartitionsOfTable 和 DynamicRange 。 启用分区选项(即,该选项不为 None)时,用于从 Azure SQL 数据库并行加载数据的并行度由复制活动上的 parallelCopies 设置控制。 |
否 |
| 分区设置 | 指定数据分区的设置组。 当分区选项不是 None 时适用。 |
否 |
在 partitionSettings 下: |
||
| partitionNames | 需要复制的物理分区的列表。 当分区选项是 PhysicalPartitionsOfTable 时适用。 如果使用查询来检索源数据,请在 WHERE 子句中挂接 ?AdfTabularPartitionName。 有关示例,请参阅从 Azure Database for PostgreSQL 进行并行复制一节。 |
否 |
| partitionColumnName | 以整数类型、日期类型或日期/时间类型(int、smallint、bigint、date、timestamp without time zone、timestamp with time zone 或 time without time zone)指定源列的名称,范围分区将使用它进行并行复制。 如果未指定,系统会自动检测表的主键并将其用作分区列。当分区选项是 DynamicRange 时适用。 如果使用查询来检索源数据,请在 WHERE 子句中挂接 ?AdfRangePartitionColumnName 。 有关示例,请参阅从 Azure Database for PostgreSQL 进行并行复制一节。 |
否 |
| partitionUpperBound | 要从中复制数据的分区列的最大值。 当分区选项是 DynamicRange 时适用。 如果使用查询来检索源数据,请在 WHERE 子句中挂接 ?AdfRangePartitionUpbound。 有关示例,请参阅从 Azure Database for PostgreSQL 进行并行复制一节。 |
否 |
| partitionLowerBound | 要从中复制数据的分区列的最小值。 当分区选项是 DynamicRange 时适用。 如果使用查询来检索源数据,请在 WHERE 子句中挂接 ?AdfRangePartitionLowbound。 有关示例,请参阅从 Azure Database for PostgreSQL 进行并行复制一节。 |
否 |
示例:
"activities":[
{
"name": "CopyFromAzurePostgreSql",
"type": "Copy",
"inputs": [
{
"referenceName": "<AzurePostgreSql input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzurePostgreSqlSource",
"query": "<custom query e.g. SELECT * FROM mytable>",
"queryTimeout": "00:10:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Azure Database for PostgreSQL 作为接收器
将数据复制到 Azure Database for PostgreSQL 时,复制活动的 sink 节支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| type | 复制活动接收器的 type 属性必须设置为 AzurePostgreSQLSink。 | 是 |
| preCopyScript | 每次运行时将数据写入 Azure Database for PostgreSQL 之前,为要执行的复制活动指定 SQL 查询。 可以使用此属性清除预加载的数据。 | 否 |
| writeMethod | 用于将数据写入 Azure Database for PostgreSQL 的方法。 允许的值为:CopyCommand(默认值,性能较佳)和 BulkInsert 。 |
否 |
| writeBatchSize | 每批加载到 Azure Database for PostgreSQL 中的行数。 允许的值是表示行数的整数。 |
否(默认值为 1000000) |
| writeBatchTimeout | 超时之前等待批插入操作完成时的等待时间。 允许的值为 Timespan 字符串。 示例为 00:30:00(30 分钟)。 |
否(默认值为 00:30:00) |
示例:
"activities":[
{
"name": "CopyToAzureDatabaseForPostgreSQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure PostgreSQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzurePostgreSQLSink",
"preCopyScript": "<custom SQL script>",
"writeMethod": "CopyCommand",
"writeBatchSize": 1000000
}
}
}
]
从 Azure Database for PostgreSQL 进行并行复制
复制活动中的 Azure Database for PostgreSQL 连接器提供内置的数据分区,用于并行复制数据。 可以在复制活动的“源”表中找到数据分区选项。
启用分区复制时,复制活动将对 Azure Database for PostgreSQL 源运行并行查询,以按分区加载数据。 可通过复制活动中的 parallelCopies 设置控制并行度。 例如,如果将 parallelCopies 设置为 4,则该服务会根据指定的分区选项和设置并行生成并运行 4 个查询,每个查询从 Azure Database for PostgreSQL 检索一部分数据。
建议同时启用并行复制和数据分区,尤其是从 Azure Database for PostgreSQL 加载大量数据时。 下面是适用于不同方案的建议配置。 将数据复制到基于文件的数据存储中时,建议将数据作为多个文件写入文件夹(仅指定文件夹名称),在这种情况下,性能优于写入单个文件。
| 场景 | 建议的设置 |
|---|---|
| 从包含物理分区的大型表进行完整加载。 | 分区选项:表的物理分区。 在执行期间,该服务将自动检测物理分区并按分区复制数据。 |
| 从不包含物理分区但包含用于数据分区的整数列的大型表进行完整加载。 | 分区选项:动态范围分区。 分区列:指定用于对数据进行分区的列。 如果未指定,将使用主键列。 |
| 使用自定义查询加载包含物理分区的大量数据。 | 分区选项:表的物理分区。 查询: SELECT * FROM ?AdfTabularPartitionName WHERE <your_additional_where_clause>。分区名称:指定要从中复制数据的分区名称。 如果未指定,服务会自动检测在 PostgreSQL 数据集中指定的表的物理分区。 在执行期间,服务会将 ?AdfTabularPartitionName 替换为实际分区名,并发送到 Azure Database for PostgreSQL。 |
| 使用自定义查询从不包含物理分区但包含用于数据分区的整数列的表加载大量数据。 | 分区选项:动态范围分区。 查询: SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>。分区列:指定用于对数据进行分区的列。 你可以针对具有整数或日期、日期/时间数据类型的列进行分区。 分区上限和分区下限:指定是否要对分区列进行筛选,以便仅检索介于下限和上限之间的数据。 在执行期间,该服务会将 ?AdfRangePartitionColumnName、?AdfRangePartitionUpbound 和 ?AdfRangePartitionLowbound 替换为每个分区的实际列名和值范围,并发送到 Azure Database for PostgreSQL。 例如,如果为分区列“ID”设置了下限 1、上限 80,并将并行复制设置为 4,则服务会按 4 个分区检索数据。 其 ID 分别介于 [1, 20]、[21, 40]、[41, 60] 和 [61, 80] 之间。 |
使用分区选项加载数据的最佳做法:
- 选择独特的列作为分区列(如主键或唯一键),以避免数据倾斜。
- 如果表具有内置分区,请使用名为“表的物理分区”分区选项来提升性能。
- 如果使用 Azure Integration Runtime 复制数据,则可设置较大的“数据集成单元 (DIU)”(>4) 以利用更多计算资源。 检查此处适用的方案。
- “复制并行度”可控制分区数量,将此数字设置得太大有时会损害性能,建议将此数字设置按以下公式计算的值:(DIU 或自承载 IR 节点数)*(2 到 4)。
示例:从包含物理分区的大型表进行完整加载
"source": {
"type": "AzurePostgreSqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
示例:使用动态范围分区进行查询
"source": {
"type": "AzurePostgreSqlSource",
"query": "SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
映射数据流属性
在映射数据流中转换数据时,可以从 Azure Database for PostgreSQL 读取表以及将数据写入表。 有关详细信息,请参阅映射数据流中的源转换和汇集转换。 你可以选择使用 Azure Database for PostgreSQL 数据集或内联数据集作为源和接收器类型。
源转换
下表列出了 Azure Database for PostgreSQL 源支持的属性。 你可以在“源选项”选项卡中编辑这些属性。
| 名称 | 描述 | 必需 | 允许的值 | 数据流脚本属性 |
|---|---|---|---|---|
| 表 | 如果你选择“表”作为输入,则数据流会从数据集中指定的表提取所有数据。 | 否 | - | (仅适用于内联数据集) tableName |
| 查询 | 如果你选择“查询”作为输入,请指定一个用来从源提取数据的 SQL 查询,这将替代在数据集中指定的任何表。 使用查询是一个好方法,它可以减少用于测试或查找的行数。 不支持 Order By 子句,但你可以设置完整的 SELECT FROM 语句。 还可以使用用户定义的表函数。 select * from udfGetData() 是 SQL 中的一个 UDF,它返回你可以在数据流中使用的表。 查询示例: select * from mytable where customerId > 1000 and customerId < 2000 或 select * from "MyTable"。 请注意,在 PostgreSQL 中,如果未加引号,则实体名称不区分大小写。 |
否 | 字符串 | 查询 |
| 架构名称 | 如果选择“存储过程”作为输入,请指定存储过程的架构名称,或选择“刷新”以请求服务发现架构名称。 | 否 | 字符串 | schemaName |
| 存储过程 | 如果选择“存储过程”作为输入,请指定要从源表读取数据的存储过程的名称,或选择“刷新”以请求服务发现过程名称。 | 是(如果选择“存储过程”作为输入) | 字符串 | 过程名称 |
| 过程参数 | 如果选择“存储过程”作为输入,请按过程中设置的顺序为存储过程指定任何输入参数,或者选择“导入”以使用窗体 @paraName 导入所有过程参数。 |
否 | 数组 | inputs |
| 批大小 | 指定批大小,以将大型数据分成多个批。 | 否 | 整数 | batchSize |
| 隔离级别 | 选择下列隔离级别之一: - 读取已提交的内容 - 读取未提交的内容(默认) - 可重复的读取 - 可序列化 - 无(忽略隔离级别) |
否 | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ SERIALIZABLE 无 |
隔离级别 |
Azure Database for PostgreSQL 源脚本示例
使用 Azure Database for PostgreSQL 作为源类型时,关联的数据流脚本为:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from mytable',
format: 'query') ~> AzurePostgreSQLSource
接收器转换
下表列出了 Azure Database for PostgreSQL 接收器支持的属性。 您可以在“Sink选项”选项卡中编辑这些属性。
| 名称 | 描述 | 必需 | 允许的值 | 数据流脚本属性 |
|---|---|---|---|---|
| 更新方法 | 指定数据库目标上允许哪些操作。 默认设置为仅允许插入。 若要更新、更新插入或删除行,需要进行“更改行”转换才能标记这些操作的行。 |
是 | true 或 false |
可删除的 insertable updateable upsertable |
| 键列 | 对于更新、更新插入和删除操作,必须设置键列来确定要更改的行。 后续的更新、更新插入和删除将使用你选取为密钥的列名称。 因此,你必须选取存在于接收器映射中的列。 |
否 | 数组 | 密钥 |
| 跳过写入键列 | 如果你不希望将值写入到键列,请选择“跳过写入键列”。 | 否 | true 或 false |
skipKeyWrites |
| 表操作 | 确定在写入之前是否从目标表重新创建或删除所有行。 - 无:不会对表进行任何操作。 - 重新创建:将删除表并重新创建表。 动态创建新表时是必需的。 - 截断:将删除目标表中的所有行。 |
否 | true 或 false |
recreate truncate |
| 批大小 | 指定每批中写入的行数。 较大的批大小可提高压缩比并改进内存优化,但在缓存数据时可能会导致内存不足异常。 | 否 | 整数 | batchSize |
| 选择用户 DB 架构 | 默认情况下,将在接收器架构下创建临时表作为暂存方式。 或者,可以取消选中使用接收器架构选项,改为指定一个架构名称;数据工厂将在该架构下创建一个临时表来加载上游数据,并在完成后自动清理它们。 请确保已在数据库中创建表权限,并更改对架构的权限。 | 否 | 字符串 | stagingSchemaName |
| 预处理和后处理 SQL 脚本 | 指定在将数据写入接收器数据库之前(预处理)和之后(后处理)会执行的多行 SQL 脚本。 | 否 | 字符串 | preSQLs postSQLs |
提示
- 建议将包含多个命令的单个批处理脚本拆分为多个批处理。
- 只有返回简单更新计数的数据定义语言 (Data Definition Language, DDL) 和数据操作语言 (Data Manipulation Language, DML) 语句可作为批处理的一部分运行。 在执行批量操作中了解详细信息
启用增量提取:使用此选项告知 ADF 仅处理自上次执行管道以来已更改的行。
增量日期列:使用增量提取功能时,必须选择要用作源表中水印的日期/时间或数字列。
从头开始读取:使用增量提取设置此选项将指示 ADF 在首次执行具有增量提取的管道时读取所有行。
Azure Database for PostgreSQL 接收器脚本示例
使用 Azure Database for PostgreSQL 作为接收器类型时,关联的数据流脚本为:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzurePostgreSQLSink
查找活动属性
有关属性的详细信息,请参阅查找活动。
升级 Azure Database for PostgreSQL 连接器
在“编辑链接服务”页中,在“版本”下选择 2.0,并通过引用链接服务属性版本 2.0 配置链接服务。
相关内容
有关复制活动支持作为源和接收器的数据存储的列表,请参阅受支持的数据存储。