适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
本文概述如何使用 Azure 数据工厂和 Synapse Analytics 管道中的复制活动从 Amazon Redshift 复制数据。 它是基于概述复制活动总体的复制活动概述一文。
支持的功能
此 Amazon Redshift 连接器支持以下功能:
| 支持的功能 | IR |
|---|---|
| 复制活动(源/-) | ① ② |
| Lookup 活动 | ① ② |
① Azure 集成运行时 ② 自承载集成运行时
有关复制活动支持作为源或接收器的数据存储列表,请参阅支持的数据存储表。
具体而言,通过使用查询或内置 Redshift UNLOAD 支持,此 Amazon Redshift 连接器支持从 Redshift 检索数据。
连接器支持此文章中的 Windows 版本。
提示
若要在从 Redshift 复制大量数据时获得最佳性能,请考虑通过 Amazon S3 使用内置的 Redshift UNLOAD。 有关详细信息,请参阅使用 UNLOAD 从Amazon Redshift 复制数据部分。
先决条件
- 如果使用自承载集成运行时将数据复制到本地数据存储,请授权集成运行时(使用计算机的 IP 地址)对 Amazon Redshift 群集的访问权限。 有关说明,请参阅授予对群集的访问权限。
- 如果要将数据复制到 Azure 数据存储,请参阅 Azure 数据中心 IP 范围,了解 Azure 数据中心使用的计算 IP 地址和 SQL 范围。
入门
若要使用管道执行复制活动,可以使用以下工具或 SDK 之一:
使用 UI 创建到 Amazon Redshift 的链接服务
使用以下步骤在 Azure 门户 UI 中创建一个到 Amazon Redshift 的链接服务。
浏览到 Azure 数据工厂或 Synapse 工作区中的“管理”选项卡并选择“链接服务”,然后单击“新建”:
搜索“Amazon”并选择“Amazon Redshift 连接器”。
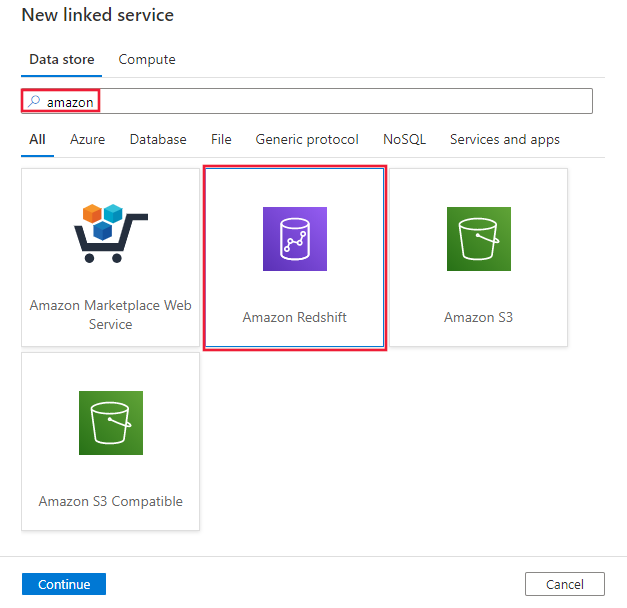
配置服务详细信息、测试连接并创建新的链接服务。
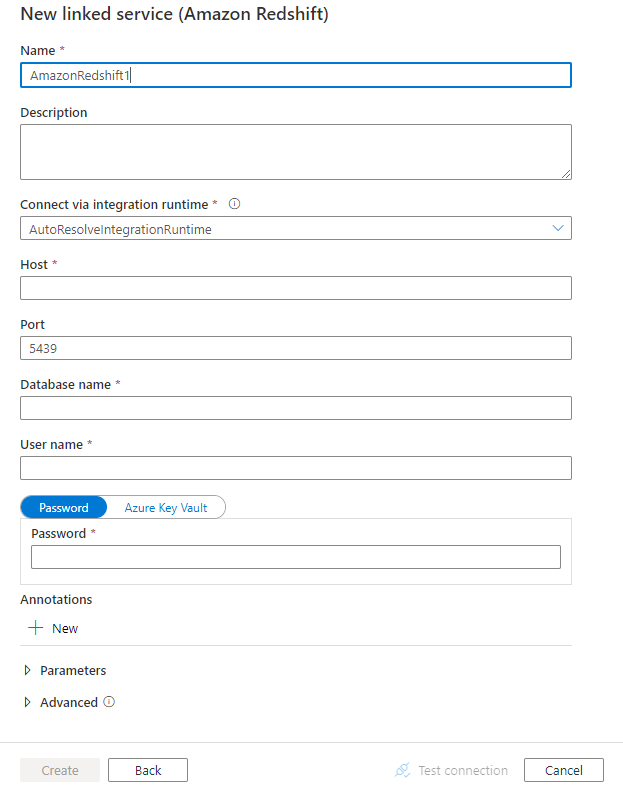
连接器配置详细信息
对于特定于 Amazon Redshift 连接器的数据工厂实体,以下部分提供了有关用于定义这些实体的属性的详细信息。
链接服务属性
Amazon Redshift 链接的服务支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| type | type 属性必须设置为:AmazonRedshift | 是 |
| server | Amazon Redshift 服务器的 IP 地址或主机名。 | 是 |
| port | Amazon Redshift 服务器用于侦听客户端连接的 TCP 端口数。 | 否,默认值为 5439 |
| database | Amazon Redshift 数据库名称。 | 是 |
| username | 有权访问数据库的用户的名称。 | 是 |
| password | 用户帐户密码。 将此字段标记为 SecureString 以安全地存储它,或引用存储在 Azure Key Vault 中的机密。 | 是 |
| connectVia | 用于连接到数据存储的集成运行时。 如果数据存储位于专用网络,则可以使用 Azure Integration Runtime 或自承载集成运行时。 如果未指定,则使用默认 Azure Integration Runtime。 | 否 |
示例:
{
"name": "AmazonRedshiftLinkedService",
"properties":
{
"type": "AmazonRedshift",
"typeProperties":
{
"server": "<server name>",
"database": "<database name>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
数据集属性
有关可用于定义数据集的各部分和属性的完整列表,请参阅数据集一文。 本部分提供 Amazon Redshift 数据集支持的属性列表。
若要从 Amazon Redshift 复制数据,支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| type | 数据集的 type 属性必须设置为:AmazonRedshiftTable | 是 |
| schema | 架构的名称。 | 否(如果指定了活动源中的“query”) |
| 表 | 表的名称。 | 否(如果指定了活动源中的“query”) |
| tableName | 具有架构的表的名称。 支持此属性是为了向后兼容。 对于新的工作负荷,请使用 schema 和 table。 |
否(如果指定了活动源中的“query”) |
示例
{
"name": "AmazonRedshiftDataset",
"properties":
{
"type": "AmazonRedshiftTable",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Amazon Redshift linked service name>",
"type": "LinkedServiceReference"
}
}
}
如果使用 RelationalTable 类型数据集,该数据集仍按原样受支持,但我们建议今后使用新数据集。
复制活动属性
有关可用于定义活动的各部分和属性的完整列表,请参阅管道一文。 本部分提供 Amazon Redshift 源支持的属性列表。
作为源的 Amazon Redshift
要从 Amazon Redshift 复制数据,请将复制活动中的源类型设置为“AmazonRedshiftSource” 。 复制活动source部分支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| type | 复制活动 source 的 type 属性必须设置为:AmazonRedshiftSource | 是 |
| 查询 | 使用自定义查询读取数据。 例如:select * from MyTable。 | 否(如果指定了数据集中的“tableName”) |
| redshiftUnloadSettings | 使用 Amazon Redshift UNLOAD 时的属性组。 | 否 |
| s3LinkedServiceName | 表示通过指定“AmazonS3”类型的链接服务名称,将用作临时存储的 Amazon S3。 | 是(如果使用的是 UNLOAD) |
| bucketName | 指示 S3 Bucket 以存储临时数据。 如果未提供,此服务将自动生成它。 | 是(如果使用的是 UNLOAD) |
示例:复制活动中使用 UNLOAD 的 Amazon Redshift 源
"source": {
"type": "AmazonRedshiftSource",
"query": "<SQL query>",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "<Amazon S3 linked service>",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
}
在下一节中,深入了解如何使用 UNLOAD 高效地从 Amazon Redshift 复制数据。
使用 UNLOAD 从Amazon Redshift 复制数据
UNLOAD 是 Amazon Redshift 提供的一种机制,可将查询结果卸载到 Amazon 简单存储服务 (Amazon S3) 上的一个或多个文件中。 Amazon 推荐使用此方式从 Redshift 复制大数据集。
示例:使用 UNLOAD、暂存复制和 PolyBase 将数据从 Amazon Redshift 复制到 Azure Synapse Analytics
对于此示例用例,复制活动按“redshiftUnloadSettings”中的配置将数据从 Amazon Redshift 卸载到 Amazon S3,然后按“stagingSettings”中指定的要求将数据从 Amazon S3 复制到 Azure Blob,最后使用 PolyBase 将数据载入 Azure Synapse Analytics。 所有临时格式均由复制活动正确处理。

"activities":[
{
"name": "CopyFromAmazonRedshiftToSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "AmazonRedshiftDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRedshiftSource",
"query": "select * from MyTable",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "AmazonS3LinkedService",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": "AzureStorageLinkedService",
"path": "adfstagingcopydata"
},
"dataIntegrationUnits": 32
}
}
]
Amazon Redshift 的数据类型映射
从 Amazon Redshift 复制数据时,以下映射用于从 Amazon Redshift 数据类型映射到服务内部使用的临时数据类型。 若要了解复制活动如何将源架构和数据类型映射到接收器,请参阅架构和数据类型映射。
| Amazon Redshift 数据类型 | 临时服务数据类型 |
|---|---|
| BIGINT | Int64 |
| BOOLEAN | String |
| CHAR | String |
| DATE | DateTime |
| DECIMAL | 小数 |
| DOUBLE PRECISION | Double |
| INTEGER | Int32 |
| real | Single |
| SMALLINT | Int16 |
| TEXT | String |
| TIMESTAMP | DateTime |
| VARCHAR | String |
查找活动属性
若要了解有关属性的详细信息,请查看 Lookup 活动。
相关内容
有关复制活动支持作为源和接收器的数据存储的列表,请参阅支持的数据存储。