series_outliers()
对序列中的异常点进行评分。
该函数接受一个带有动态数值数组的表达式作为输入,生成一个相同长度的动态数值数组。 数组的每个值指示使用 Tukey 测试时可能出现异常的分数。 相同输入元素中大于 1.5 的值表示异常增加。 小于 -1.5 的值表示异常减少。
语法
series_outliers(series [, kind ] [, ignore_val ] [, min_percentile ] [, max_percentile ])
详细了解语法约定。
参数
| 客户 | 类型 | 必需 | 说明 |
|---|---|---|---|
| series | dynamic |
✔️ | 一组数值。 |
| kind | string |
用于离群值检测的算法。 支持的选项是 "tukey"(传统的“Tukey”)和 "ctukey"(自定义的“Tukey”)。 默认值为 "ctukey"。 |
|
| ignore_val | int、long 或 real | 一个数值,表示序列中缺少的值。 默认值为 double(null)。 NULL 和忽略值的分数将设置为 0。 |
|
| min_percentile | int、long 或 real | 用于计算归一化四分位差的最小分位数。 默认值为 10。 值必须在 [2.0, 98.0] 范围内。 此参数仅与 "ctukey" kind 相关。 |
|
| max_percentile | int、long 或 real | 用于计算归一化四分位差的最大分位数。 默认值为 90。 值必须在 [2.0, 98.0] 范围内。 此参数仅与 "ctukey" kind 相关。 |
下表描述了 "tukey" 和 "ctukey" 之间的差异:
| 算法 | 默认分位范围 | 支持自定义分位范围 |
|---|---|---|
"tukey" |
25% / 75% | 否 |
"ctukey" |
10% / 90% | 是 |
提示
使用此函数的最佳方式是将其应用于 make-series 运算符的结果。
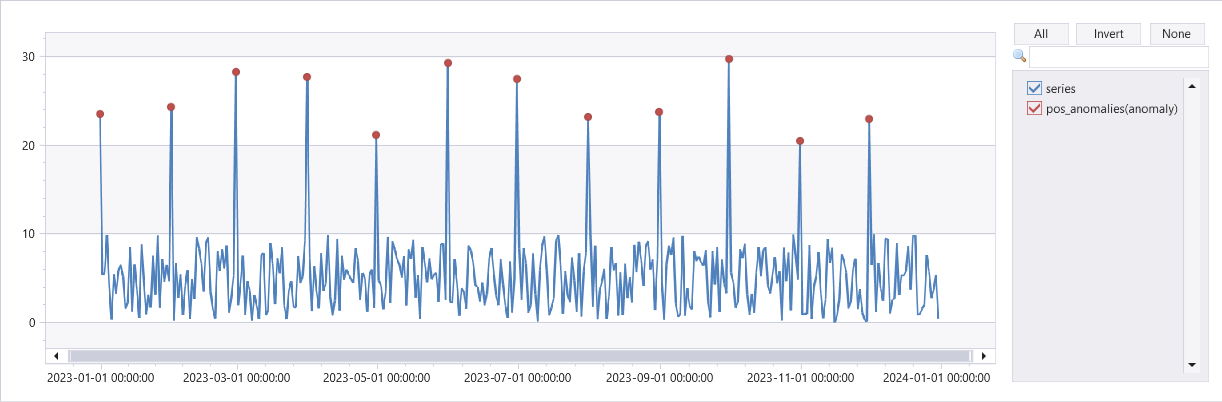
示例
range x from 0 to 364 step 1
| extend t = datetime(2023-01-01) + 1d*x
| extend y = rand() * 10
| extend y = iff(monthofyear(t) != monthofyear(prev(t)), y+20, y) // generate a sample series with outliers at first day of each month
| summarize t = make_list(t), series = make_list(y)
| extend outliers=series_outliers(series)
| extend pos_anomalies = array_iff(series_greater_equals(outliers, 1.5), 1, 0)
| render anomalychart with(xcolumn=t, ycolumns=series, anomalycolumns=pos_anomalies)