series_decompose_anomalies()
异常情况检测基于序列分解。 有关详细信息,请参阅 series_decompose()。
此函数采用包含某个序列(动态数值数组)的表达式作为输入,并提取有分数的异常点。
语法
series_decompose_anomalies (系列, [阈值, 季节性 , 趋势, Test_points, AD_method, Seasonality_threshold ])
详细了解语法约定。
参数
| 客户 | 类型 | 必需 | 说明 |
|---|---|---|---|
| 系列 | dynamic |
✔️ | 数值的数组,通常是 make-series 或 make_list 运算符生成的输出。 |
| 阈值 | real |
异常阈值。 默认值为 1.5(k 值),用于检测轻度异常或更严重的异常。 | |
| 季节性 | int |
控制周期性分析。 可能的值为: - -1:使用 series_periods_detect 自动检测周期性。 这是默认值。- 整数时间段:一个正整数,指定箱数的预期周期。例如,如果系列位于 1h 箱中,则每周周期为 168 箱。- 0:无周期性,因此请跳过提取此组件的操作。 |
|
| 趋势 | string |
控制趋势分析。 可能的值为: - avg:将趋势组件定义为 average(x)。 这是默认值。- linefit:使用线性回归提取趋势组件。- none:无趋势,因此请跳过提取此组件的操作。 |
|
| Test_points | int |
正整数,指定要从学习或回归过程中排除的序列末尾处的点的数目。 应当设置此参数,用于预测。 默认值为 0。 | |
| AD_method | string |
控制对残差时序的异常情况检测方法,其中包含以下值之一: - ctukey:Tukey 的围栏测试,采用自定义的第 10 - 90 个百分位数范围。 这是默认值。- tukey:Tukey 的围栏测试,采用标准的第 25 - 75 个百分位数范围。有关残差时序的详细信息,请参阅 series_outliers。 |
|
| Seasonality_threshold | real |
当 Seasonality 设置为 autodetect 时周期性分数的阈值。 默认分数阈值为 0.6。 有关详细信息,请参阅 series_periods_detect。 |
返回
该函数返回以下各个序列:
ad_flag:一个三元序列,其中包含 (+1, -1, 0),分别标记为正常/关闭/无异常ad_score:异常分数baseline:序列的预测值,通过分解获得
算法
此函数执行以下步骤:
- 使用相应的参数调用 series_decompose() 来创建基线和残差序列。
- 通过使用所选的异常情况检测方法对残差序列应用 series_outliers() 来计算 ad_score 序列。
- 通过对 ad_score 应用阈值来计算 ad_flag 序列,分别标记为正常/关闭/无异常。
示例
检测每周周期性中的异常
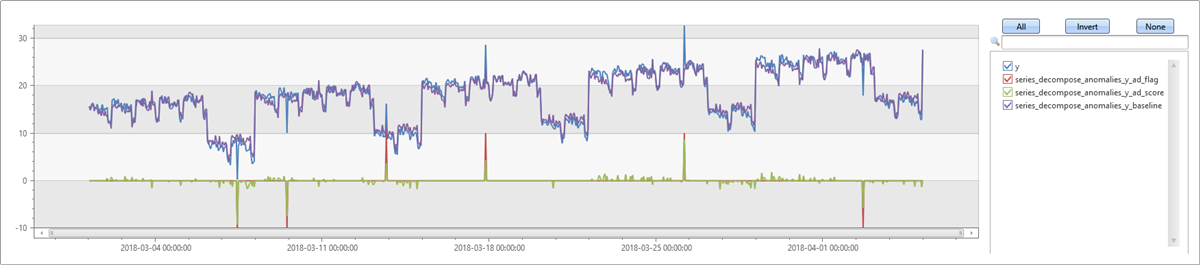
在下面的示例中,将生成一个包含每周周期性的序列,然后向其中添加一些离群值。 series_decompose_anomalies 会自动检测周期性并生成用于捕获重复模式的基线。 在 ad_score 组件中可以清楚地辨认出你添加的离群值。
let ts=range t from 1 to 24*7*5 step 1
| extend Timestamp = datetime(2018-03-01 05:00) + 1h * t
| extend y = 2*rand() + iff((t/24)%7>=5, 10.0, 15.0) - (((t%24)/10)*((t%24)/10)) // generate a series with weekly seasonality
| extend y=iff(t==150 or t==200 or t==780, y-8.0, y) // add some dip outliers
| extend y=iff(t==300 or t==400 or t==600, y+8.0, y) // add some spike outliers
| summarize Timestamp=make_list(Timestamp, 10000),y=make_list(y, 10000);
ts
| extend series_decompose_anomalies(y)
| render timechart
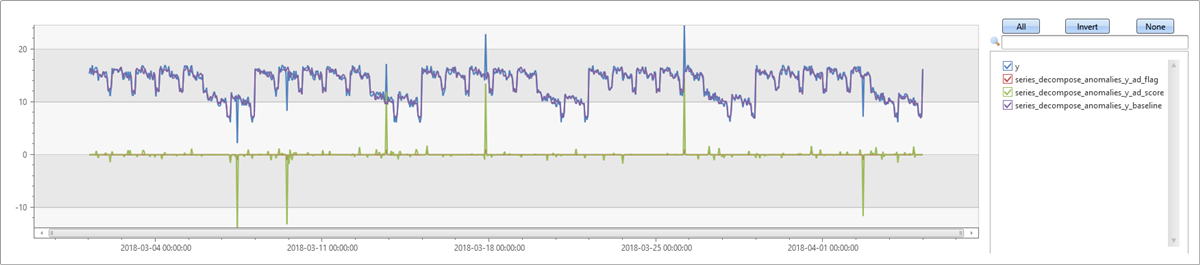
检测具有趋势的每周周期性中的异常
在此示例中,将向上一示例中的序列添加趋势。 首先,使用默认参数运行 series_decompose_anomalies,其中的趋势 avg 默认值仅取平均值,不计算趋势。 与前面的示例相比,生成的基线不包含趋势,并且准确度更低。 因此,你在数据中插入的某些离群值会因为差异较大而不被检测到。
let ts=range t from 1 to 24*7*5 step 1
| extend Timestamp = datetime(2018-03-01 05:00) + 1h * t
| extend y = 2*rand() + iff((t/24)%7>=5, 5.0, 15.0) - (((t%24)/10)*((t%24)/10)) + t/72.0 // generate a series with weekly seasonality and ongoing trend
| extend y=iff(t==150 or t==200 or t==780, y-8.0, y) // add some dip outliers
| extend y=iff(t==300 or t==400 or t==600, y+8.0, y) // add some spike outliers
| summarize Timestamp=make_list(Timestamp, 10000),y=make_list(y, 10000);
ts
| extend series_decompose_anomalies(y)
| extend series_decompose_anomalies_y_ad_flag =
series_multiply(10, series_decompose_anomalies_y_ad_flag) // multiply by 10 for visualization purposes
| render timechart
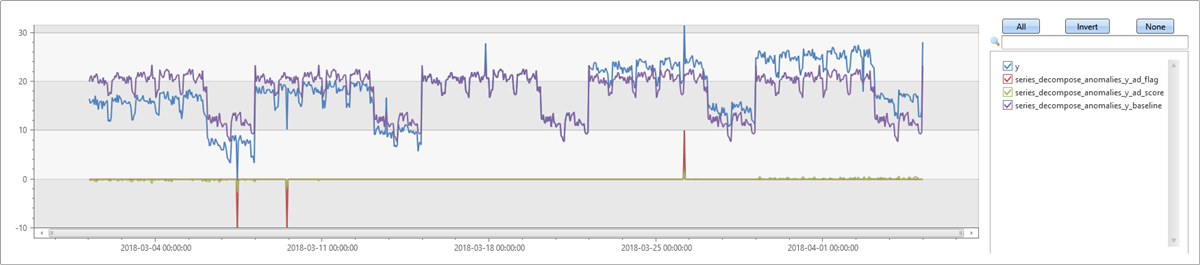
接下来运行同一示例,但由于你预计序列中存在趋势,因此请在 trend 参数中指定 linefit。 你可以看到,基线更接近输入序列。 将会检测到所有插入的离群值,还会检测到一些误报。 请参阅接下来有关调整阈值的示例。
let ts=range t from 1 to 24*7*5 step 1
| extend Timestamp = datetime(2018-03-01 05:00) + 1h * t
| extend y = 2*rand() + iff((t/24)%7>=5, 5.0, 15.0) - (((t%24)/10)*((t%24)/10)) + t/72.0 // generate a series with weekly seasonality and ongoing trend
| extend y=iff(t==150 or t==200 or t==780, y-8.0, y) // add some dip outliers
| extend y=iff(t==300 or t==400 or t==600, y+8.0, y) // add some spike outliers
| summarize Timestamp=make_list(Timestamp, 10000),y=make_list(y, 10000);
ts
| extend series_decompose_anomalies(y, 1.5, -1, 'linefit')
| extend series_decompose_anomalies_y_ad_flag =
series_multiply(10, series_decompose_anomalies_y_ad_flag) // multiply by 10 for visualization purposes
| render timechart
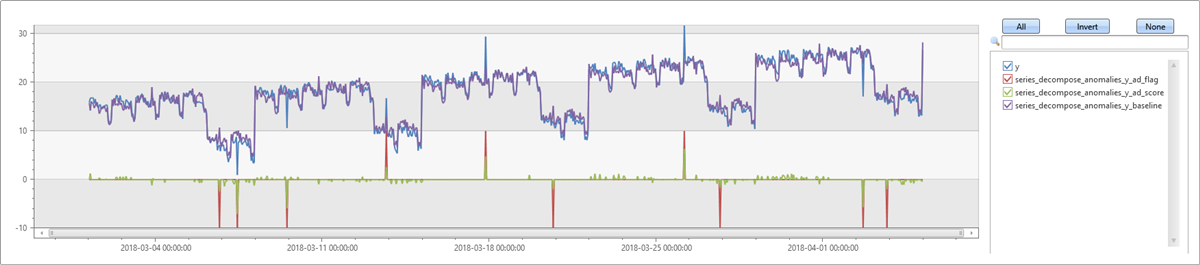
调整异常情况检测阈值
在上一示例中,一些干扰点被当作异常情况检测出来。 现在,将异常情况检测阈值从默认值 1.5 提高到 2.5。 使用此百分位距,将只会检测到更严重的异常。 现在,将只会检测到你在数据中插入的离群值。
let ts=range t from 1 to 24*7*5 step 1
| extend Timestamp = datetime(2018-03-01 05:00) + 1h * t
| extend y = 2*rand() + iff((t/24)%7>=5, 5.0, 15.0) - (((t%24)/10)*((t%24)/10)) + t/72.0 // generate a series with weekly seasonality and onlgoing trend
| extend y=iff(t==150 or t==200 or t==780, y-8.0, y) // add some dip outliers
| extend y=iff(t==300 or t==400 or t==600, y+8.0, y) // add some spike outliers
| summarize Timestamp=make_list(Timestamp, 10000),y=make_list(y, 10000);
ts
| extend series_decompose_anomalies(y, 2.5, -1, 'linefit')
| extend series_decompose_anomalies_y_ad_flag =
series_multiply(10, series_decompose_anomalies_y_ad_flag) // multiply by 10 for visualization purposes
| render timechart