hll_merge()
合并 HLL 结果。 这是聚合版 hll_merge() 的标量版本。
重要
hll()、hll_if() 和 hll_merge() 的结果可以进行存储,并在以后进行检索。 例如,你可能想要创建每日唯一用户摘要,然后就可以将其用于计算每周计数。 然而,这些结果的精确二进制表示形式可能会随时间而改变。 无法保证这些函数会为相同的输入生成相同的结果,因此不建议依赖它们。
语法
hll_merge( hll, hll2, [ hll3, ... ])
详细了解语法约定。
参数
| 客户 | 类型 | 必需 | 说明 |
|---|---|---|---|
| hll, hll2, ... | string |
✔️ | 包含要合并的 HLL 值的列名称。 此函数需要 2-64 个参数。 |
返回
返回一个 HLL 值。 值是合并 hll、hll2、... hllN 列后的结果。
示例
此示例显示合并列的值。
range x from 1 to 10 step 1
| extend y = x + 10
| summarize hll_x = hll(x), hll_y = hll(y)
| project merged = hll_merge(hll_x, hll_y)
| project dcount_hll(merged)
输出
dcount_hll_merged |
|---|
| 20 |
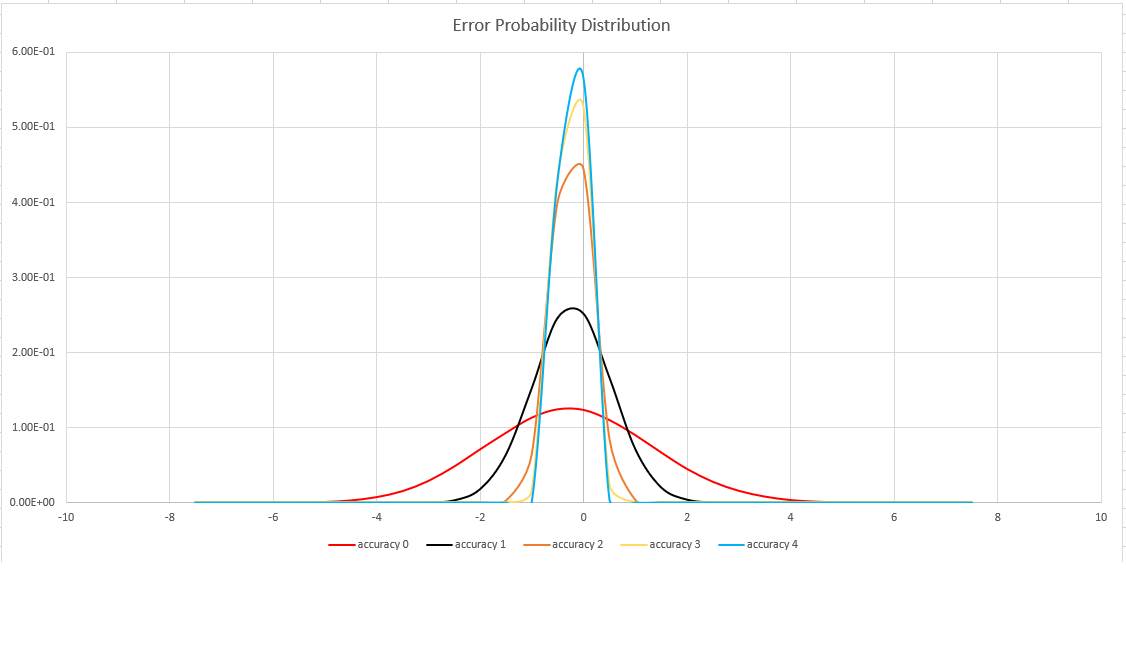
估计准确度
此函数使用 HyperLogLog (HLL) 算法的变体,该算法对集基数进行随机估算。 该算法提供一个“旋钮”,可用于平衡每个内存大小的准确度和执行时间:
| 精确度 | 错误 (%) | 条目数 |
|---|---|---|
| 0 | 1.6 | 212 |
| 1 | 0.8 | 214 |
| 2 | 0.4 | 216 |
| 3 | 0.28 | 217 |
| 4 | 0.2 | 218 |
注意
“条目数”列是 HLL 实现中 1 字节计数器的数目。
如果集基数足够小,则该算法包括以下有关执行理想计数(零错误)的规定:
- 当准确度等级为
1时,将返回 1000 个值 - 当准确度等级为
2时,将返回 8000 个值
错误边界基于概率,而不是基于理论界限。 值是错误分布的标准偏差 (sigma),99.7% 的估计值的相对误差小于 3 x sigma。
下图显示所有受支持的准确度设置的相对估计误差的概率分布函数,以百分比为单位: