dcountif()(聚合函数)
估算行的 expr(其中的 predicate 计算为 true)的非重复值的数目。
空值会被忽略,不会纳入计算中。
注意
此函数与 summarize 运算符结合使用。
语法
dcountif (expr、谓词、[, 准确度])
详细了解语法约定。
参数
| 客户 | 类型 | 必需 | 说明 |
|---|---|---|---|
| expr | string |
✔️ | 用于聚合计算的表达式。 |
| predicate | string |
✔️ | 用于筛选行的表达式。 |
| accuracy | int |
速度和准确度之间的控制。 如果未指定,则默认值为 1。 有关支持的值,请参阅估计准确度。 |
返回
返回行的 expr(其中的 predicate 计算为 true)的非重复值的估算数目。
提示
在所有行或没有行通过 Predicate 表达式的情况下,dcountif() 可能会返回错误。
示例
此示例显示了在每个州有多少种类型的致命风暴事件发生。
StormEvents
| summarize DifferentFatalEvents=dcountif(EventType,(DeathsDirect + DeathsIndirect)>0) by State
| where DifferentFatalEvents > 0
| order by DifferentFatalEvents
显示的结果表仅包括前 10 行。
| 状态 | DifferentFatalEvents |
|---|---|
| CALIFORNIA | 12 |
| 德克萨斯 | 12 |
| OKLAHOMA | 10 |
| ILLINOIS | 9 |
| KANSAS | 9 |
| NEW YORK | 9 |
| NEW JERSEY | 7 |
| 华盛顿州 | 7 |
| 密歇根州 | 7 |
| MISSOURI | 7 |
| ... | ... |
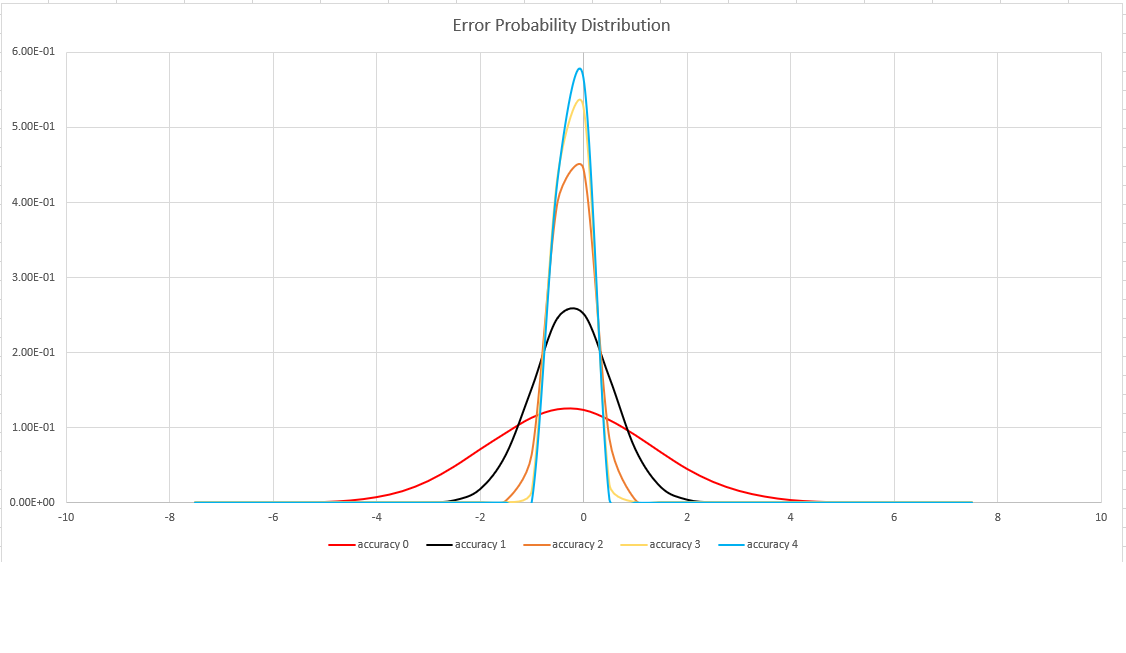
估计准确度
此函数使用 HyperLogLog (HLL) 算法的变体,该算法对集基数进行随机估算。 该算法提供一个“旋钮”,可用于平衡每个内存大小的准确度和执行时间:
| 精确度 | 错误 (%) | 条目数 |
|---|---|---|
| 0 | 1.6 | 212 |
| 1 | 0.8 | 214 |
| 2 | 0.4 | 216 |
| 3 | 0.28 | 217 |
| 4 | 0.2 | 218 |
注意
“条目数”列是 HLL 实现中 1 字节计数器的数目。
如果集基数足够小,则该算法包括以下有关执行理想计数(零错误)的规定:
- 当准确度等级为
1时,将返回 1000 个值 - 当准确度等级为
2时,将返回 8000 个值
错误边界基于概率,而不是基于理论界限。 值是错误分布的标准偏差 (sigma),99.7% 的估计值的相对误差小于 3 x sigma。
下图显示所有受支持的准确度设置的相对估计误差的概率分布函数,以百分比为单位: