适用范围:![]() NoSQL
NoSQL
在 Azure Cosmos DB 中,数据是按照为每个容器定义的索引策略编制索引的。 新建容器的默认索引策略会对任何字符串或数字强制使用范围索引。 可以使用自己的自定义索引策略替代此策略。
注意
本文所述的更新索引策略的方法仅适用于 Azure Cosmos DB for NoSQL。 在 Azure Cosmos DB for MongoDB 和 Azure Cosmos DB for Apache Cassandra 中的辅助索引中了解索引编制。
索引策略示例
以下是一些索引策略的示例,以它们的 JSON 格式呈现。 它们以 JSON 格式在 Azure 门户上公开。 可以通过 Azure CLI 或任何 SDK 设置相同的参数。
用以有选择地排除某些属性路径的选择退出策略
{
"indexingMode": "consistent",
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/path/to/single/excluded/property/?"
},
{
"path": "/path/to/root/of/multiple/excluded/properties/*"
}
]
}
用以有选择地包括某些属性路径的选择加入策略
{
"indexingMode": "consistent",
"includedPaths": [
{
"path": "/path/to/included/property/?"
},
{
"path": "/path/to/root/of/multiple/included/properties/*"
}
],
"excludedPaths": [
{
"path": "/*"
}
]
}
注意
我们通常建议使用选择退出索引策略。 Azure Cosmos DB 会主动索引可能会添加到你的数据模型的任何新属性。
仅在特定属性路径上使用空间索引
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/_etag/?"
}
],
"spatialIndexes": [
{
"path": "/path/to/geojson/property/?",
"types": [
"Point",
"Polygon",
"MultiPolygon",
"LineString"
]
}
]
}
矢量索引策略示例
除了包含或排除各个属性的路径以外,还可以指定一个矢量索引。 一般情况下,每当使用 VectorDistance 系统函数测量查询矢量和矢量属性之间的相似度时,都应指定矢量索引。
注意
在继续操作之前,必须启用 Azure Cosmos DB NoSQL 矢量索引和搜索。
重要
矢量索引策略必须位于容器的矢量策略中定义的同一路径上。 详细了解容器矢量策略。
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/_etag/?"
},
{
"path": "/vector/*"
}
],
"vectorIndexes": [
{
"path": "/vector",
"type": "quantizedFlat"
}
]
}
重要
将矢量路径添加到索引策略的“excludedPaths”部分可确保优化插入性能。 不将矢量路径添加到“excludedPaths”会导致矢量插入的 RU 费用和延迟较高。
重要
目前,矢量策略和矢量索引在创建后是不可变的。 若要进行更改,请创建一个新集合。
可以定义以下类型的矢量索引策略:
| 类型 | 描述 | 最大维度 |
|---|---|---|
flat |
将矢量存储在与其他已创建索引的属性相同的索引上。 | 505 |
quantizedFlat |
在索引上存储之前,量化(压缩)矢量。 这可以降低延迟和吞吐量,但会牺牲一点准确度。 | 4096 |
diskANN |
基于 DiskANN 创建索引,实现快速高效的近似搜索。 | 4096 |
执行矢量搜索时,flat 和 quantizedFlat 索引类型会利用 Azure Cosmos DB 的索引来存储和读取每个矢量。 使用 flat 索引的矢量搜索是暴力搜索,其准确度为 100%。 但是,平面索引上的矢量存在 505 个维度的限制。
quantizedFlat 索引会在该索引上存储量化或压缩矢量。 使用 quantizedFlat 索引的矢量搜索也是暴力搜索,但由于矢量在添加到索引之前进行了量化,因此其准确度可能略低于 100%。 但相较于 flat 索引上的矢量搜索,使用 quantized flat 的矢量搜索应会具有更低的延迟、更高的吞吐量和更低的 RU 成本。 如果使用查询筛选器将矢量搜索的范围缩小到相对较小的矢量集,则这是一个不错的选择。
diskANN 索引是专门为利用 DiskANN 的矢量定义的单独索引,DiskANN 则是 Microsoft Research 开发的高性能矢量索引算法套件。 DiskANN 索引可以提供一些延迟最低、每秒查询数 (QPS) 最高和 RU 成本最低的查询,且准确度很高。 但由于 DiskANN 是近似最近邻域 (ANN) 索引,因此准确度可能低于 quantizedFlat 或 flat。
diskANN 和 quantizedFlat 索引可以采用可选的索引生成参数,这些参数可用于优化适用于每个近似最近邻矢量索引的准确度与延迟权衡。
quantizationByteSize:设置产品量化的大小(以字节为单位)。 最小值为 1,默认值由系统动态决定,最大值为 512。 将此参数设置为较大的值可能会导致更高的矢量搜索准确度,代价是 RU 成本和延迟较高。 这适用于quantizedFlat和DiskANN索引类型。indexingSearchListSize:设置在构建索引期间要搜索的矢量数。 最小值为 10,默认值为 100,最大值为 500。 将此参数设置为较大的值可能会导致更高的矢量搜索准确度,代价是索引生成时间和矢量引入延迟时间更长。 这仅适用于DiskANN索引。
元组索引策略示例
此示例索引策略在 events.name 和 events.category 上定义元组索引
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{"path":"/*"},
{"path":"/events/[]/{name,category}/?"}
],
"excludedPaths":[],
"compositeIndexes":[]
}
上述索引用于以下查询。
SELECT *
FROM root r
WHERE
EXISTS (SELECT VALUE 1 FROM ev IN r.events
WHERE ev.name = ‘M&M’ AND ev.category = ‘Candy’)
组合索引策略示例
除了包含或排除各属性的路径,还可以指定一个组合索引。 若要执行具有针对多个属性的 ORDER BY 子句的查询,需要这些属性上的组合索引。 如果查询包含筛选器并对多个属性进行排序,则可能需要多个组合索引。
对于具有多个筛选器或同时具有筛选器和 ORDER BY 子句的查询,组合索引也具有性能优势。
注意
组合路径具有隐式 /?,因为仅索引该路径上的标量值。 组合路径中不支持使用 /* 通配符。 不应在组合路径中指定 /? 或 /*。 复合路径也区分大小写。
针对 (name asc, age desc) 定义的组合索引
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"descending"
}
]
]
}
以下查询需要姓名和年龄的复合索引:
查询 #1:
SELECT *
FROM c
ORDER BY c.name ASC, c.age DESC
查询 #2:
SELECT *
FROM c
ORDER BY c.name DESC, c.age ASC
此复合索引有利于以下查询并优化筛选器:
查询 #3:
SELECT *
FROM c
WHERE c.name = "Tim"
ORDER BY c.name DESC, c.age ASC
查询 #4:
SELECT *
FROM c
WHERE c.name = "Tim" AND c.age > 18
针对 (name ASC, age ASC) 和 (name ASC, age DESC) 定义的组合索引
可以在同一个索引策略中定义多个组合索引。
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"ascending"
}
],
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"descending"
}
]
]
}
针对 (name ASC, age ASC) 定义的组合索引
可以选择指定顺序。 如果未指定,顺序为升序。
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name"
},
{
"path":"/age"
}
]
]
}
排除所有属性路径,但使索引保持活动状态
当生存时间 (TTL) 功能处于活动状态但不需要其他索引来将 Azure Cosmos DB 用作纯键-值存储时,可以使用此策略。
{
"indexingMode": "consistent",
"includedPaths": [],
"excludedPaths": [{
"path": "/*"
}]
}
无索引
此策略会关闭索引。 如果 indexingMode 设为 none,则无法在容器上设置 TTL。
{
"indexingMode": "none"
}
更新索引策略
在 Azure Cosmos DB 中,可以使用以下任一方法更新索引策略:
- 通过 Azure 门户
- 使用 Azure CLI
- 使用 PowerShell
- 使用某个 SDK
索引策略更新会触发索引转换。 还可以通过 SDK 跟踪此转换的进度。
注意
更新索引策略时,对 Azure Cosmos DB 的写入不会中断。 详细了解索引转换
重要
移除索引的操作会立即生效,而添加新索引则需要一些时间,因为它需要进行索引转换。 在将一个索引替换为另一个索引时(例如,将单个属性索引替换为复合索引),请确保先添加新索引,然后等待索引转换完成,再从索引策略中移除上一个索引。 否则,这将对查询上一个索引的能力产生负面影响,并可能中断引用上一个索引的任何活动工作负荷。
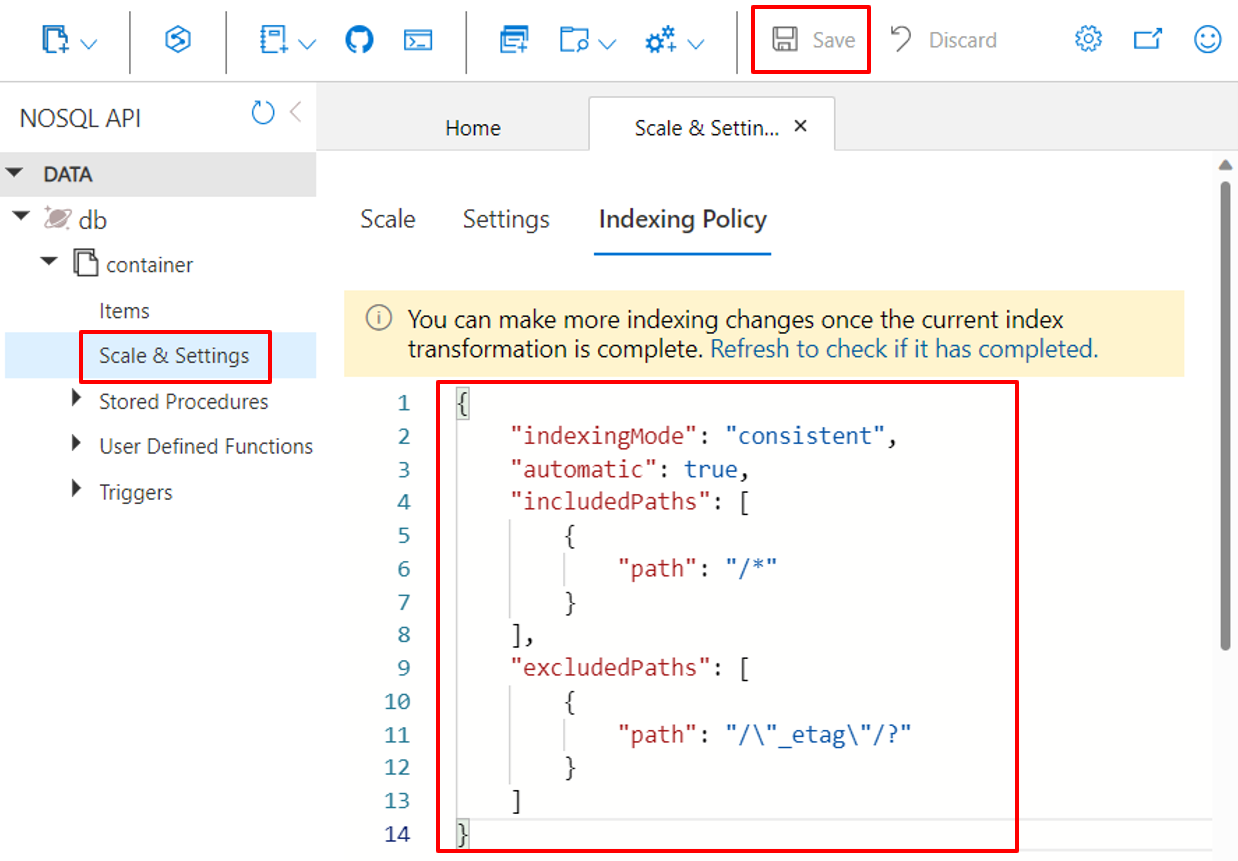
使用 Azure 门户
Azure Cosmos DB 容器将其索引策略存储为 JSON 文档,可以在 Azure 门户中直接编辑这些文档。
登录 Azure 门户。
创建新的 Azure Cosmos DB 帐户或选择现有的帐户。
打开“数据资源管理器”窗格,选择要使用的容器。
选择“缩放和设置”。
修改索引策略 JSON 文档,如这些例子所示。
完成时选择“保存” 。
使用 Azure CLI
若要创建具有自定义索引策略的容器,请参阅使用 CLI 创建具有自定义索引策略的容器。
使用 PowerShell
若要创建具有自定义索引策略的容器,请参阅使用 PowerShell 创建具有自定义索引策略的容器。
使用 .NET SDK
.NET SDK v3 中的 ContainerProperties 对象公开了一个 IndexingPolicy 属性,可以通过该属性更改 IndexingMode 以及添加或删除 IncludedPaths 和 ExcludedPaths。 有关更多信息,请参阅快速入门:适用于 .NET 的 Azure Cosmos DB for NoSQL 客户端库。
// Retrieve the container's details
ContainerResponse containerResponse = await client.GetContainer("database", "container").ReadContainerAsync();
// Set the indexing mode to consistent
containerResponse.Resource.IndexingPolicy.IndexingMode = IndexingMode.Consistent;
// Add an included path
containerResponse.Resource.IndexingPolicy.IncludedPaths.Add(new IncludedPath { Path = "/*" });
// Add an excluded path
containerResponse.Resource.IndexingPolicy.ExcludedPaths.Add(new ExcludedPath { Path = "/name/*" });
// Add a spatial index
SpatialPath spatialPath = new SpatialPath
{
Path = "/locations/*"
};
spatialPath.SpatialTypes.Add(SpatialType.Point);
containerResponse.Resource.IndexingPolicy.SpatialIndexes.Add(spatialPath);
// Add a composite index
containerResponse.Resource.IndexingPolicy.CompositeIndexes.Add(new Collection<CompositePath> { new CompositePath() { Path = "/name", Order = CompositePathSortOrder.Ascending }, new CompositePath() { Path = "/age", Order = CompositePathSortOrder.Descending } });
// Update container with changes
await client.GetContainer("database", "container").ReplaceContainerAsync(containerResponse.Resource);
若要跟踪索引转换进度,请传递一个 RequestOptions 对象,用以将 PopulateQuotaInfo 属性设置为 true。 从 x-ms-documentdb-collection-index-transformation-progress 响应头中检索值。
// retrieve the container's details
ContainerResponse containerResponse = await client.GetContainer("database", "container").ReadContainerAsync(new ContainerRequestOptions { PopulateQuotaInfo = true });
// retrieve the index transformation progress from the result
long indexTransformationProgress = long.Parse(containerResponse.Headers["x-ms-documentdb-collection-index-transformation-progress"]);
在创建新容器的同时定义自定义索引策略时,SDK V3 Fluent API 可让你以简洁高效的方式编写这个定义:
await client.GetDatabase("database").DefineContainer(name: "container", partitionKeyPath: "/myPartitionKey")
.WithIndexingPolicy()
.WithIncludedPaths()
.Path("/*")
.Attach()
.WithExcludedPaths()
.Path("/name/*")
.Attach()
.WithSpatialIndex()
.Path("/locations/*", SpatialType.Point)
.Attach()
.WithCompositeIndex()
.Path("/name", CompositePathSortOrder.Ascending)
.Path("/age", CompositePathSortOrder.Descending)
.Attach()
.Attach()
.CreateIfNotExistsAsync();
使用 Java SDK
Java SDK 中的 DocumentCollection 对象公开 getIndexingPolicy() 和 setIndexingPolicy() 方法。 通过它们操作的 IndexingPolicy 对象,你可以更改索引模式,以及添加或删除包括的和排除的路径。 有关详细信息,请参阅快速入门:构建 Java 应用来管理 Azure Cosmos DB for NoSQL 数据。
// Retrieve the container's details
Observable<ResourceResponse<DocumentCollection>> containerResponse = client.readCollection(String.format("/dbs/%s/colls/%s", "database", "container"), null);
containerResponse.subscribe(result -> {
DocumentCollection container = result.getResource();
IndexingPolicy indexingPolicy = container.getIndexingPolicy();
// Set the indexing mode to consistent
indexingPolicy.setIndexingMode(IndexingMode.Consistent);
// Add an included path
Collection<IncludedPath> includedPaths = new ArrayList<>();
IncludedPath includedPath = new IncludedPath();
includedPath.setPath("/*");
includedPaths.add(includedPath);
indexingPolicy.setIncludedPaths(includedPaths);
// Add an excluded path
Collection<ExcludedPath> excludedPaths = new ArrayList<>();
ExcludedPath excludedPath = new ExcludedPath();
excludedPath.setPath("/name/*");
excludedPaths.add(excludedPath);
indexingPolicy.setExcludedPaths(excludedPaths);
// Add a spatial index
Collection<SpatialSpec> spatialIndexes = new ArrayList<SpatialSpec>();
Collection<SpatialType> collectionOfSpatialTypes = new ArrayList<SpatialType>();
SpatialSpec spec = new SpatialSpec();
spec.setPath("/locations/*");
collectionOfSpatialTypes.add(SpatialType.Point);
spec.setSpatialTypes(collectionOfSpatialTypes);
spatialIndexes.add(spec);
indexingPolicy.setSpatialIndexes(spatialIndexes);
// Add a composite index
Collection<ArrayList<CompositePath>> compositeIndexes = new ArrayList<>();
ArrayList<CompositePath> compositePaths = new ArrayList<>();
CompositePath nameCompositePath = new CompositePath();
nameCompositePath.setPath("/name");
nameCompositePath.setOrder(CompositePathSortOrder.Ascending);
CompositePath ageCompositePath = new CompositePath();
ageCompositePath.setPath("/age");
ageCompositePath.setOrder(CompositePathSortOrder.Descending);
compositePaths.add(ageCompositePath);
compositePaths.add(nameCompositePath);
compositeIndexes.add(compositePaths);
indexingPolicy.setCompositeIndexes(compositeIndexes);
// Update the container with changes
client.replaceCollection(container, null);
});
若要在容器上跟踪索引转换进度,请传递一个用以请求要填充的配额信息的 RequestOptions 对象。 从 x-ms-documentdb-collection-index-transformation-progress 响应头中检索值。
// set the RequestOptions object
RequestOptions requestOptions = new RequestOptions();
requestOptions.setPopulateQuotaInfo(true);
// retrieve the container's details
Observable<ResourceResponse<DocumentCollection>> containerResponse = client.readCollection(String.format("/dbs/%s/colls/%s", "database", "container"), requestOptions);
containerResponse.subscribe(result -> {
// retrieve the index transformation progress from the response headers
String indexTransformationProgress = result.getResponseHeaders().get("x-ms-documentdb-collection-index-transformation-progress");
});
使用 Node.js SDK
Node.js SDK 中的 ContainerDefinition 接口公开 indexingPolicy 属性,可以通过该属性更改 indexingMode 并添加或删除 includedPaths 和 excludedPaths。 有关更多信息,请参阅快速入门–适用于 Node.js 的 Azure Cosmos DB for NoSQL 客户端库。
检索容器的详细信息:
const containerResponse = await client.database('database').container('container').read();
将索引模式设置为“一致”:
containerResponse.body.indexingPolicy.indexingMode = "consistent";
添加包含的路径(包括空间索引):
containerResponse.body.indexingPolicy.includedPaths.push({
includedPaths: [
{
path: "/age/*",
indexes: [
{
kind: cosmos.DocumentBase.IndexKind.Range,
dataType: cosmos.DocumentBase.DataType.String
},
{
kind: cosmos.DocumentBase.IndexKind.Range,
dataType: cosmos.DocumentBase.DataType.Number
}
]
},
{
path: "/locations/*",
indexes: [
{
kind: cosmos.DocumentBase.IndexKind.Spatial,
dataType: cosmos.DocumentBase.DataType.Point
}
]
}
]
});
添加排除的路径:
containerResponse.body.indexingPolicy.excludedPaths.push({ path: '/name/*' });
将更改更新到容器:
const replaceResponse = await client.database('database').container('container').replace(containerResponse.body);
若要跟踪容器上的索引转换进度,请传递一个将 populateQuotaInfo 属性设为 true 的 RequestOptions 对象。 从 x-ms-documentdb-collection-index-transformation-progress 响应头中检索值。
// retrieve the container's details
const containerResponse = await client.database('database').container('container').read({
populateQuotaInfo: true
});
// retrieve the index transformation progress from the response headers
const indexTransformationProgress = replaceResponse.headers['x-ms-documentdb-collection-index-transformation-progress'];
添加组合索引:
console.log("create container with composite indexes");
const containerDefWithCompositeIndexes = {
id: "containerWithCompositeIndexingPolicy",
indexingPolicy: {
automatic: true,
indexingMode: IndexingMode.consistent,
includedPaths: [
{
path: "/*",
},
],
excludedPaths: [
{
path: '/"systemMetadata"/*',
},
],
compositeIndexes: [
[
{ path: "/field", order: "ascending" },
{ path: "/key", order: "ascending" },
],
],
},
};
const containerWithCompositeIndexes = (
await database.containers.create(containerDefWithCompositeIndexes)
).container;
使用 Python SDK
使用 Python SDK V3 时,容器配置作为字典进行管理。 从此字典中,可以访问索引策略及其所有属性。 有关更多信息,请参阅快速入门:适用于 Python 的 Azure Cosmos DB for NoSQL 客户端库。
检索容器的详细信息:
containerPath = 'dbs/database/colls/collection'
container = client.ReadContainer(containerPath)
将索引模式设置为“一致”:
container['indexingPolicy']['indexingMode'] = 'consistent'
使用包含的路径和空间索引定义索引策略:
container["indexingPolicy"] = {
"indexingMode":"consistent",
"spatialIndexes":[
{"path":"/location/*","types":["Point"]}
],
"includedPaths":[{"path":"/age/*","indexes":[]}],
"excludedPaths":[{"path":"/*"}]
}
使用排除的路径定义索引策略:
container["indexingPolicy"] = {
"indexingMode":"consistent",
"includedPaths":[{"path":"/*","indexes":[]}],
"excludedPaths":[{"path":"/name/*"}]
}
添加组合索引:
container['indexingPolicy']['compositeIndexes'] = [
[
{
"path": "/name",
"order": "ascending"
},
{
"path": "/age",
"order": "descending"
}
]
]
将更改更新到容器:
response = client.ReplaceContainer(containerPath, container)
后续步骤
阅读以下文章中有关索引的详细信息: