适用对象:![]() Cassandra
Cassandra
本文介绍如何在 Azure Cosmos DB for Apache Cassandra 中进行分区。
Cassandra API 使用分区操作来缩放密钥空间中的各个表,以满足应用程序的性能需求。 分区是根据与表中的每条记录关联的分区键值形成的。 一个分区中的所有记录都有相同的分区键值。 Azure Cosmos DB 以透明方式自动管理分区在物理资源中的位置,以有效满足表的可伸缩性和性能需求。 随着应用程序对吞吐量和存储的要求的提高,Azure Cosmos DB 将在更多的物理计算机之间移动和均衡数据。
从开发人员的角度来看,分区在 Azure Cosmos DB for Apache Cassandra 中的行为与其在原生 Apache Cassandra 中的行为相同。 不过,幕后存在一些差异。
Apache Cassandra 与 Azure Cosmos DB 之间的差异
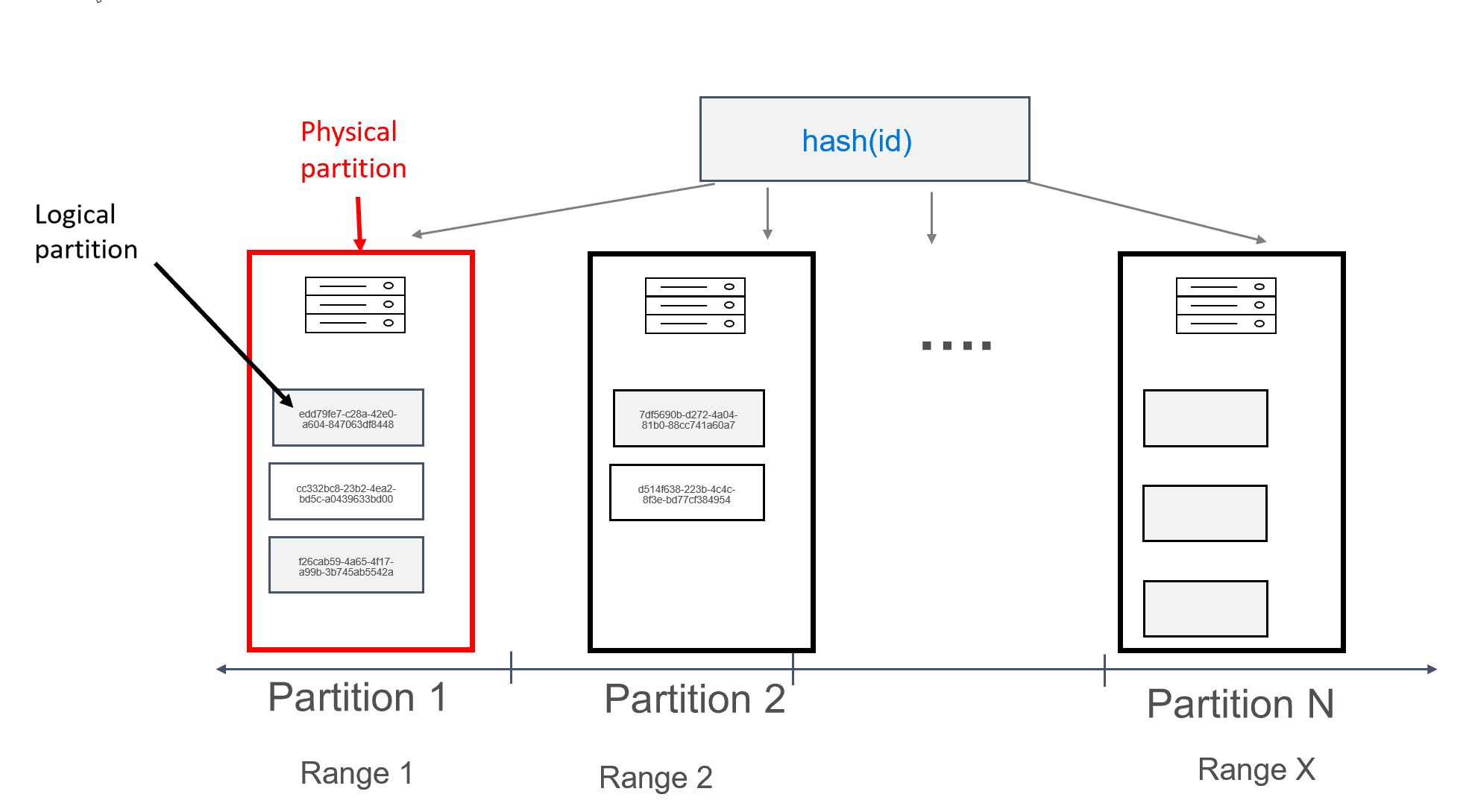
在 Azure Cosmos DB 中,存储着分区的每台计算机本身称为物理分区。 物理分区类似于虚拟机、专用计算单元或物理资源集。 此计算单元上存储的每个分区在 Azure Cosmos DB 中都称为逻辑分区。 如果你已熟悉 Apache Cassandra,则可以像看待 Cassandra 中的常规分区那样看待逻辑分区。
Apache Cassandra 建议你为可以存储在分区中的数据大小设置 100 MB 的限制。 Azure Cosmos DB 的 Cassandra API 允许每个逻辑分区最多具有 20 GB 的数据,每个物理分区最多具有 30 GB 的数据。 在 Azure Cosmos DB 中,与 Apache Cassandra 不同,物理分区中可用的计算容量使用称为请求单位的单个指标来表示,这允许你按每秒请求数(读取或写入数)而不是按核心数、内存或 IOPS 来考虑你的工作负荷。 在你了解每个请求的成本后,这可以使容量规划更加直接。 每个物理分区最多可以有 10000 RU 的计算能力供其使用。 若要详细了解可伸缩性选项,可阅读有关 Cassandra API 中的弹性缩放的文章。
在 Azure Cosmos DB 中,每个物理分区都由一组副本(也称为副本集)组成,每个分区至少有 4 个副本。 这与 Apache Cassandra 相反,后者可以将复制因子设置为 1。 但是,如果包含数据的唯一节点出现故障,这会导致低可用性。 在 Cassandra API 中,复制因子始终为 4(仲裁为 3)。 Azure Cosmos DB 自动管理副本集,而在 Apache Cassandra 中则需要使用各种工具来维护副本集。
Apache Cassandra 有令牌的概念,令牌是分区键的哈希。 令牌基于 murmur3 64 字节哈希,其值的范围为 -2^63 到 -2^63 - 1。 在 Apache Cassandra 中,此范围通常称为“令牌环”。 令牌环分布到令牌范围内,这些范围是在原生 Apache Cassandra 群集中的节点之间划分的。 Azure Cosmos DB 的分区以类似方式实现,不过它使用不同的哈希算法,并且有更大的内部令牌环。 但是,在外部,我们公开与 Apache Cassandra 相同的令牌范围,即 -2^63 到 -2^63 - 1。
主密钥
Cassandra API 中的所有表都必须定义一个 primary key。 主键的语法如下所示:
column_name cql_type_definition PRIMARY KEY
假设我们想要创建一个用户表,用于存储不同用户的消息:
CREATE TABLE uprofile.user (
id UUID PRIMARY KEY,
user text,
message text);
在此设计中,我们将 id 字段定义为主键。 主键用作表中记录的标识符,也用作 Azure Cosmos DB 中的分区键。 如果使用前述方法定义主键,则每个分区中将只有一条记录。 向数据库写入数据时,这会导致完全水平的和可缩放的分布,因此非常适用于键-值查找用例。 应用程序每次从表中读取数据时都应提供主键,以最程度地提高读取性能。
复合主键
Apache Cassandra 还有 compound keys 的概念。 复合 primary key 包含多个列;第一列是 partition key,任何其他列都是 clustering keys。 compound primary key 的语法如下所示:
PRIMARY KEY (partition_key_column_name, clustering_column_name [, ...])
假设我们要更改上述设计,并使其能够高效地检索给定用户的消息:
CREATE TABLE uprofile.user (
user text,
id int,
message text,
PRIMARY KEY (user, id));
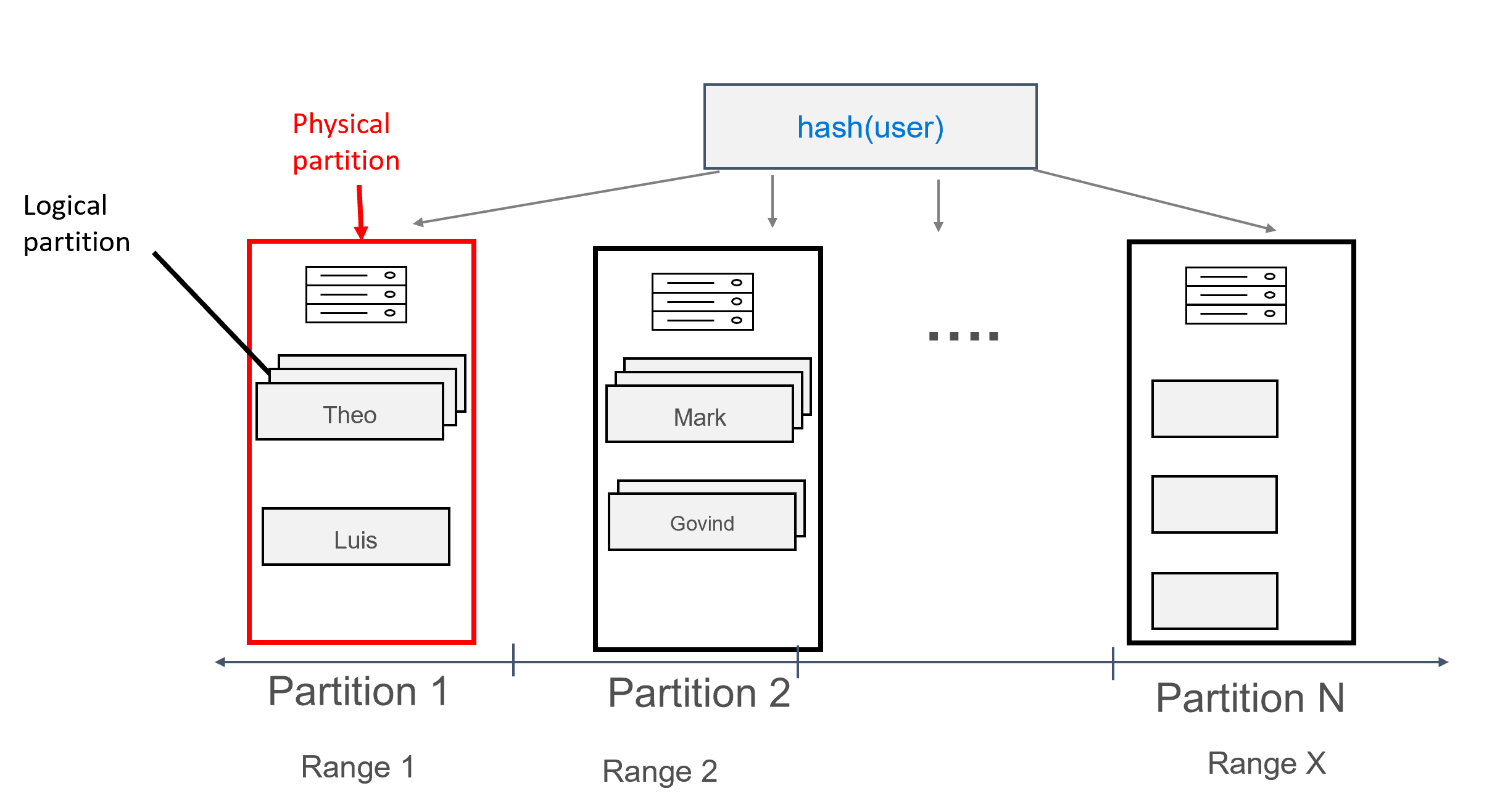
在此设计中,我们现在将 user 定义为分区键,并将 id 定义为聚类分析键。 你可以根据需要定义任意数量的聚类分析键,但聚类分析键的每个值(或值的组合)必须是独一无二的,否则无法生成添加到同一分区的多条记录,例如:
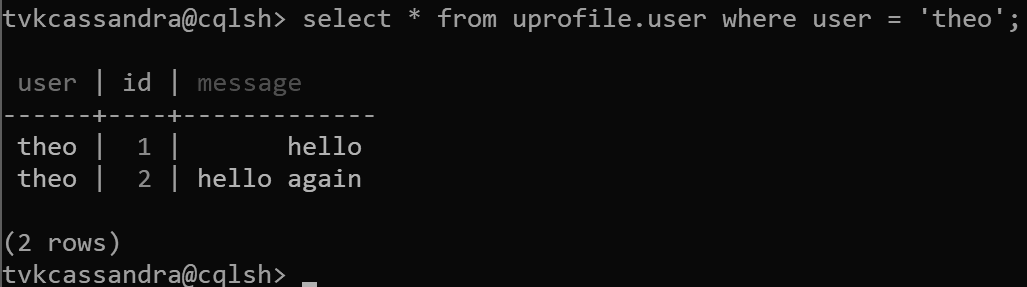
insert into uprofile.user (user, id, message) values ('theo', 1, 'hello');
insert into uprofile.user (user, id, message) values ('theo', 2, 'hello again');
当返回数据时,数据将按聚类分析键进行排序,如 Apache Cassandra 中预期的那样:
警告
查询具有复合主键的表中的数据时,如果要筛选分区键和除聚类分析键之外的任何其他非索引字段,请确保在分区键上显式添加辅助索引:
CREATE INDEX ON uprofile.user (user);
默认情况下,Azure Cosmos DB for Apache Cassandra 不会将索引应用于分区键,此方案中的索引可显著提高查询性能。 有关详细信息,请参阅关于辅助索引的文章。
对于以此方式建模的数据,可以将多条记录分配给每个分区,并按用户分组。 因此,我们可以发出按 partition key(在本例中为 user)进行高效路由的查询,以获取给定用户的所有消息。
复合分区键
复合分区键的工作方式实质上与复合键相同,不同之处在于你可以将多个列指定为复合分区键。 复合分区键的语法如下所示:
PRIMARY KEY (
(partition_key_column_name[, ...]),
clustering_column_name [, ...]);
例如,可以使用以下方法,其中 firstname 和 lastname 的唯一组合将形成分区键,id 为聚类分析键:
CREATE TABLE uprofile.user (
firstname text,
lastname text,
id int,
message text,
PRIMARY KEY ((firstname, lastname), id) );